Downloaded 62 times


















![Jobs
A job creates one or more pods and ensures that a specified number of them successfully
terminate.
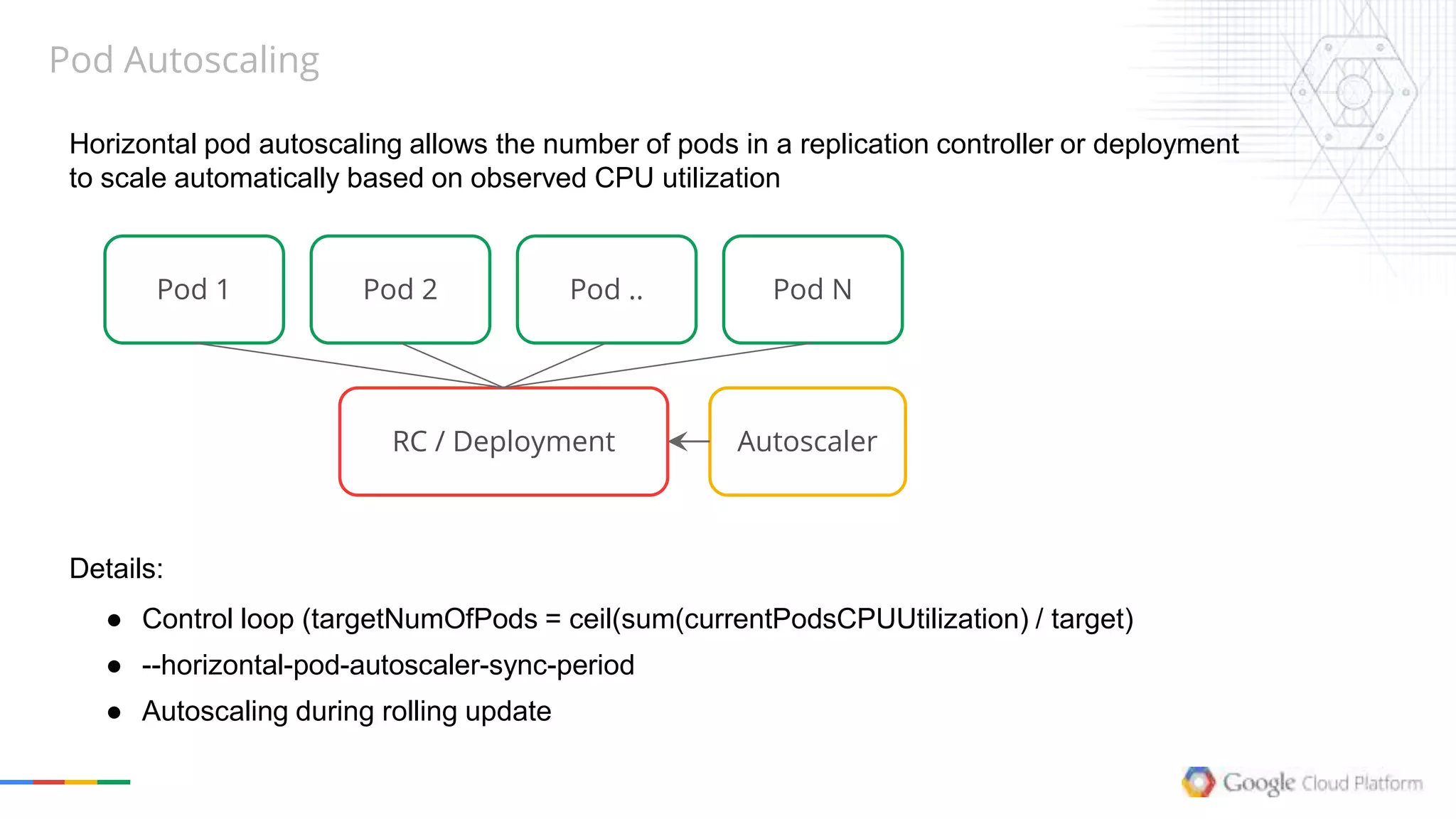
Details:
● .restartPolicy, .parallelism & .completions
● replication controller vs jobs
● cron
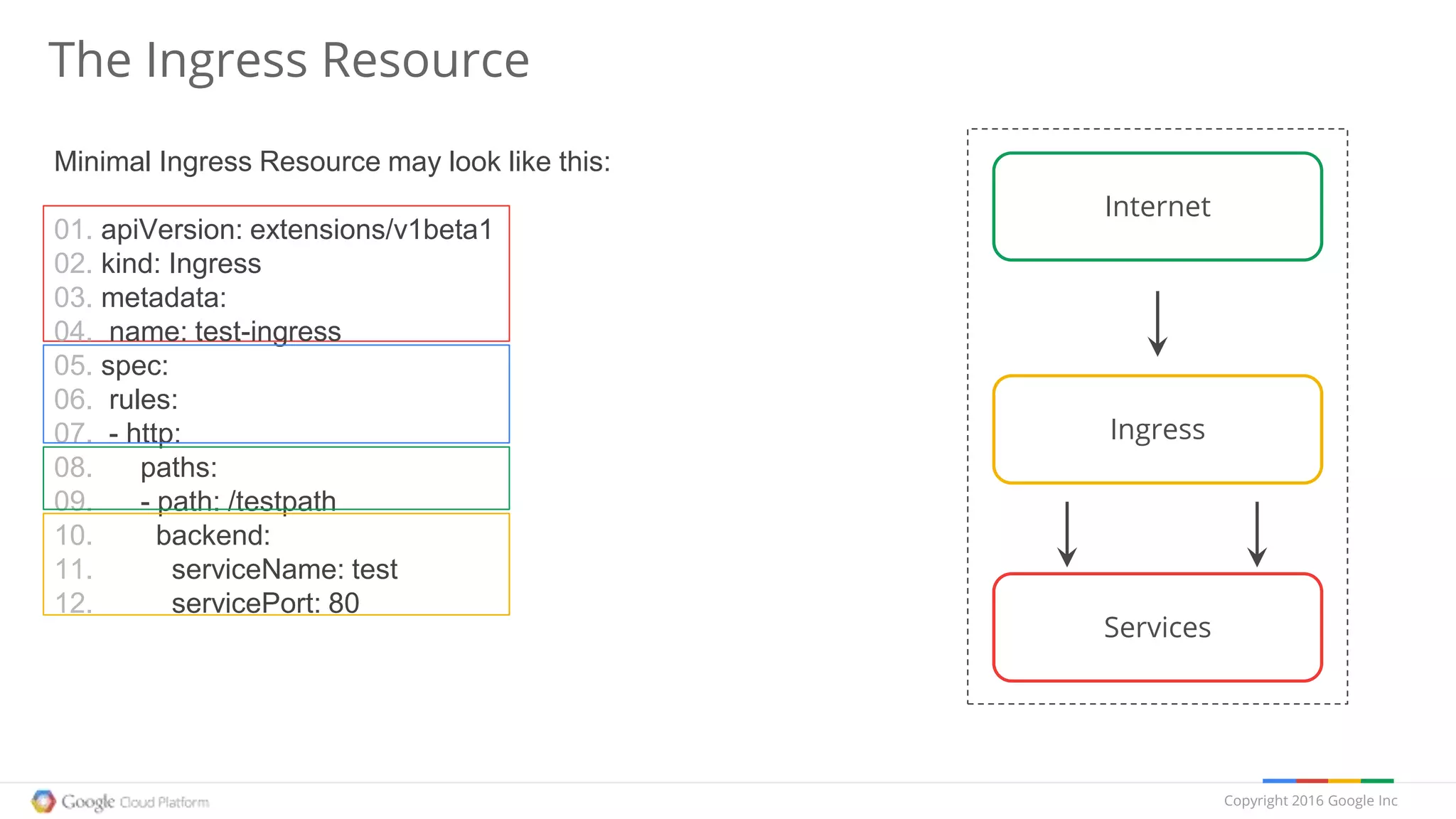
apiVersion: extensions/v1beta1
kind: Job
metadata:
name: pi
spec:
selector:
matchLabels:
app: pi
template:
metadata:
name: pi
labels:
app: pi
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
$ kubectl create -f ./job.yaml
jobs/pi
$ kubectl logs pi-aiw0a
3.141592653589793238462643383279502884197169399
37510582097494459230781640628620899862803482534
21170679821480865132823066470938446095505822317
25359408128481117450284102701938521105559644622
94895493038196442881097566593344612847564823371](https://image.slidesharecdn.com/kubernetesroadmap2016-160112211804/75/Kubernetes-State-of-the-Union-Q1-2016-30-2048.jpg)




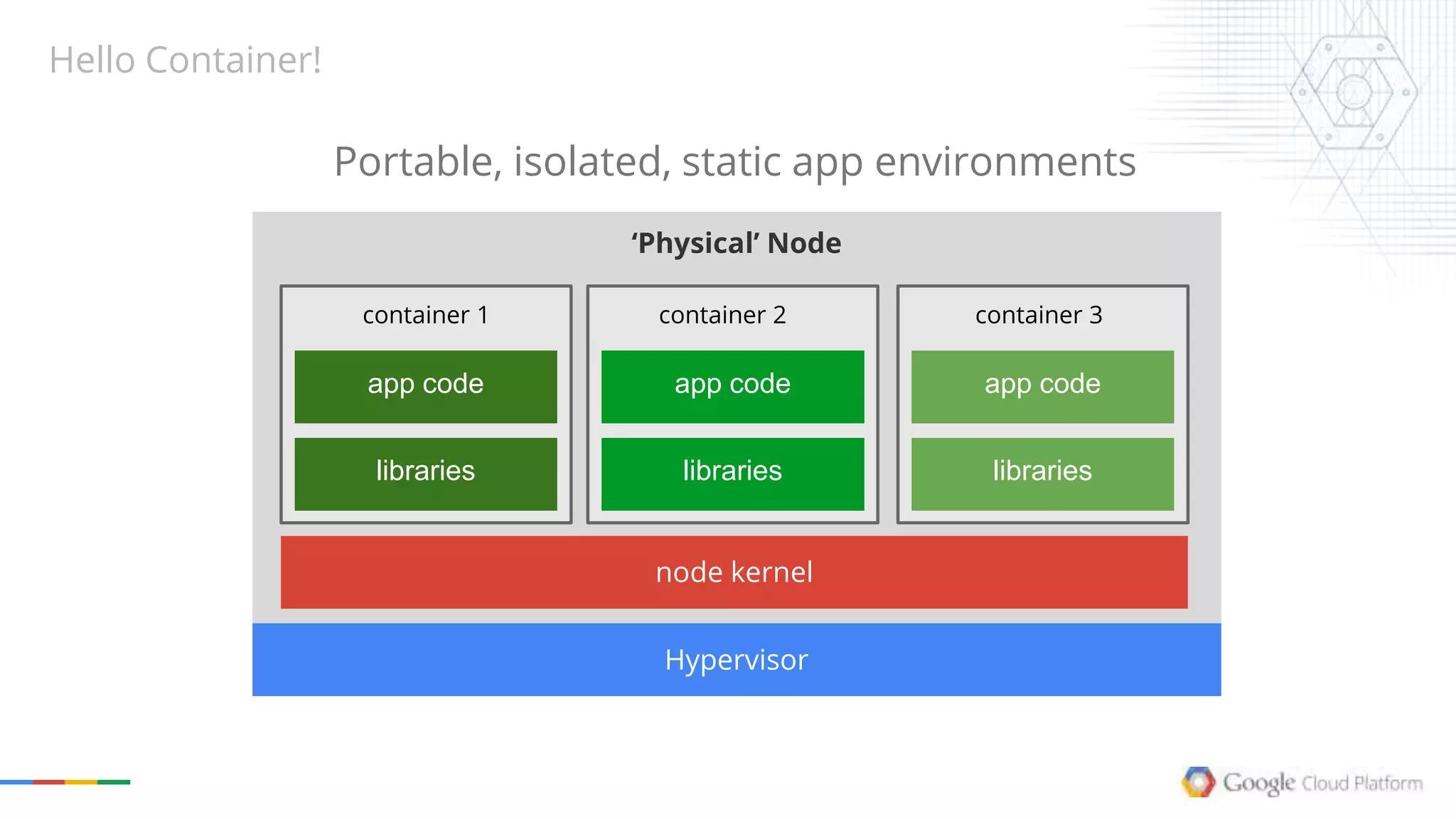
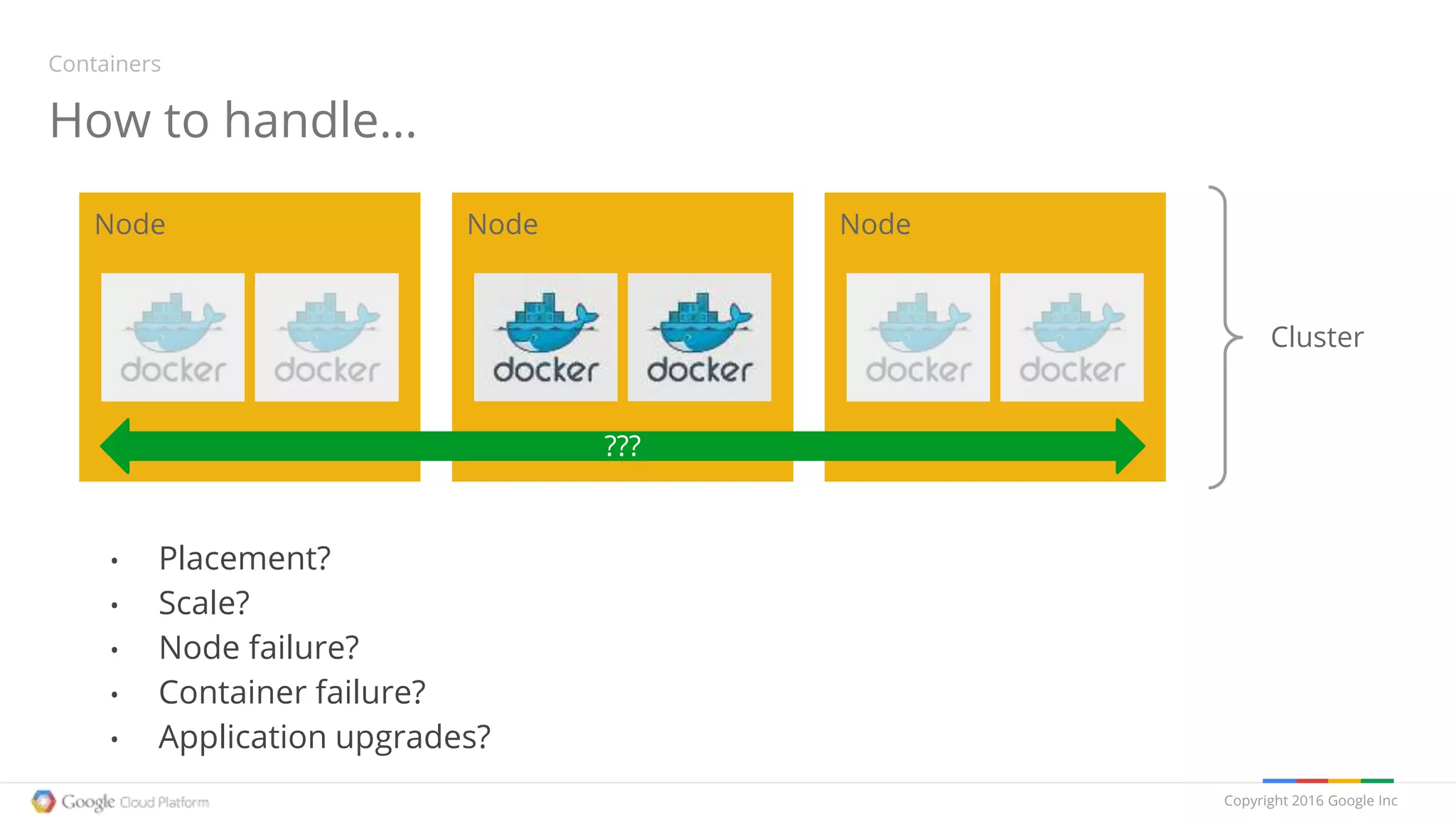
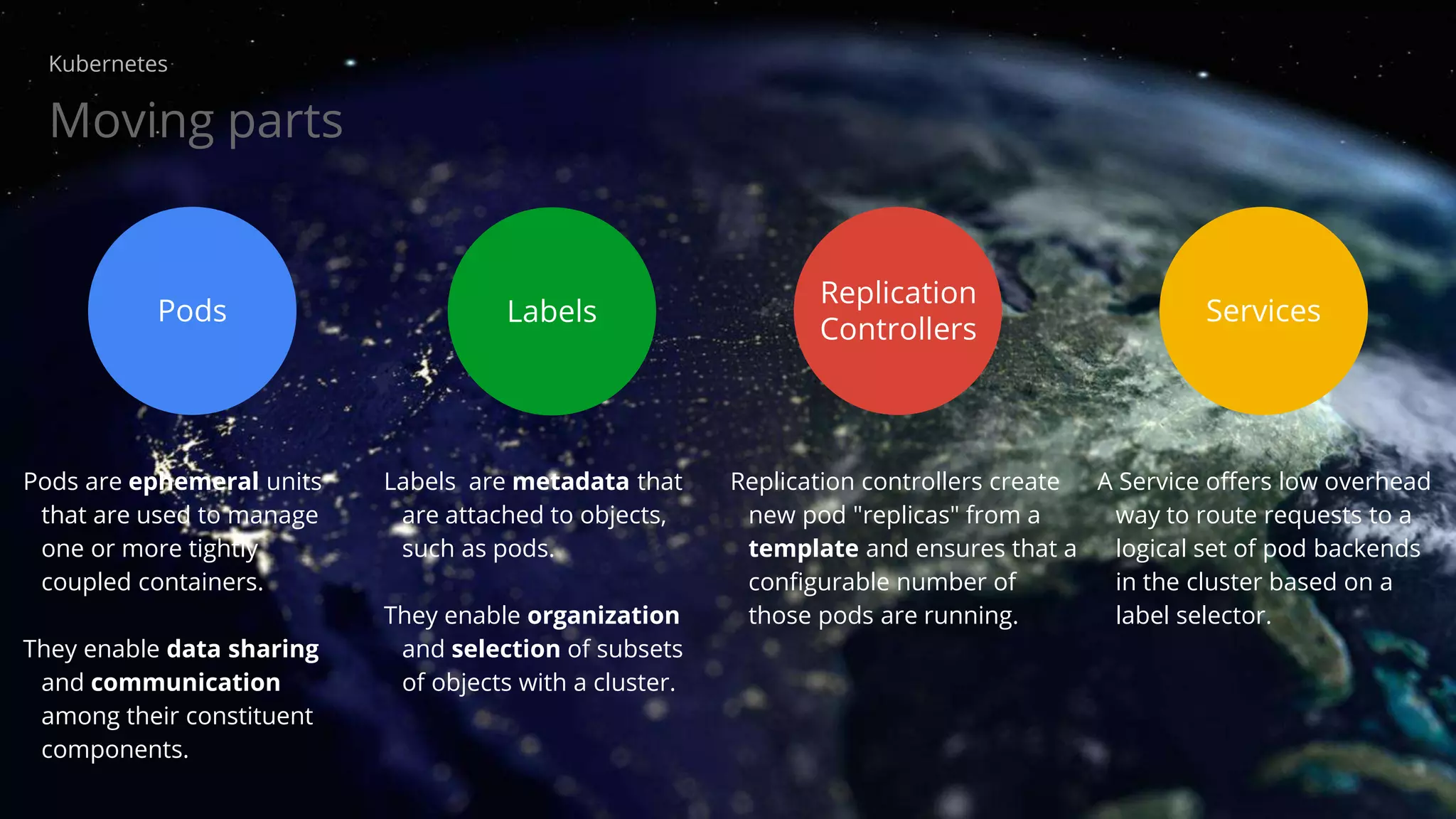
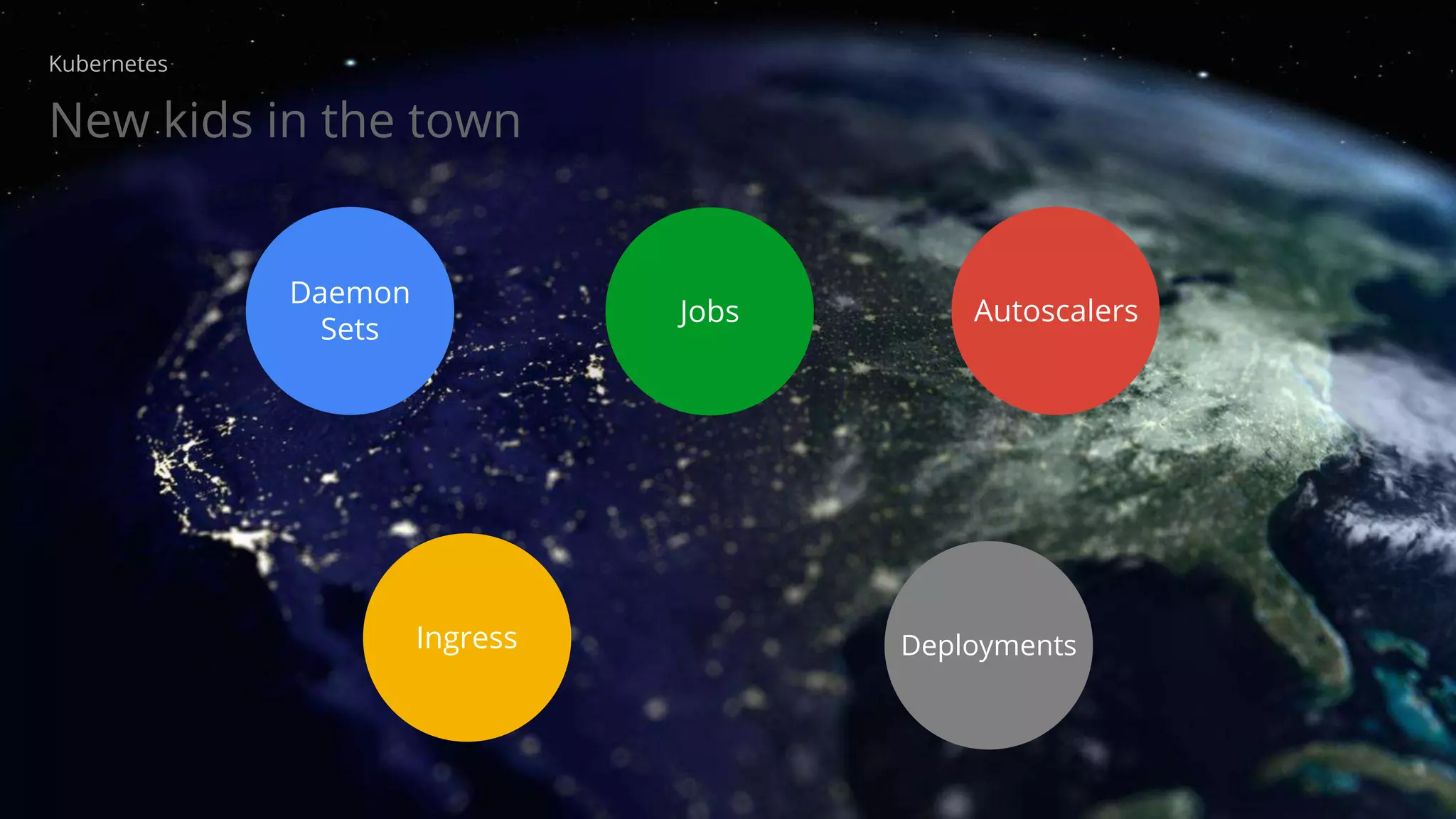
The document provides an overview of Kubernetes, discussing its architecture, features, and components including containers, pods, replication controllers, and services. It highlights important concepts such as deployments, autoscaling, ingress, and jobs, detailing how these elements contribute to managing container workloads effectively. It also mentions the evolution of Kubernetes and future work expected in upcoming versions.







































































![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)










![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)


