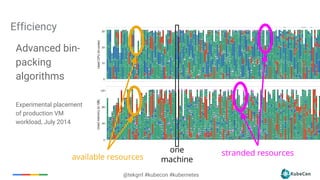
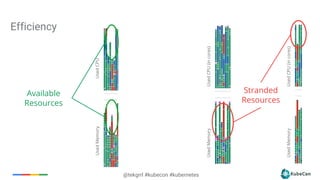
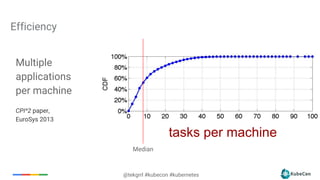
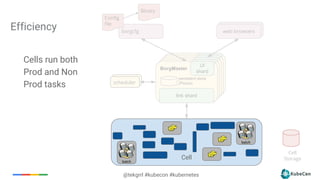
Downloaded 72 times












![@tekgrrl #kubecon #kubernetes
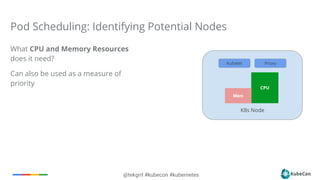
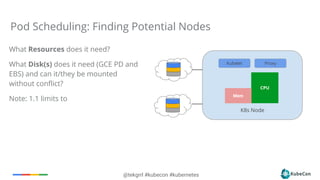
Resource based Scheduling (Work In Progress)
Provide QoS for Scheduled Pods
Per Container CPU and Memory requirements
Specified as Request and Limit
Future releases will [better] support:
● Best Effort (Request == 0)
● Burstable ( Request < Limit)
● Guaranteed (Request == Limit)
Best Effort Scheduling for low priority workloads improves
Utilization at Google by 20%](https://image.slidesharecdn.com/kubeconeu-workingslides-160330022850/85/KubeCon-EU-2016-A-Practical-Guide-to-Container-Scheduling-27-320.jpg)
![@tekgrrl #kubecon #kubernetes
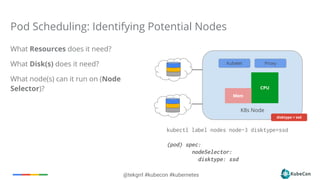
nodeAffinity (Alpha in 1.2)
{
"nodeAffinity": {
"requiredDuringSchedulingIgnoredDuringExecution": {
"nodeSelectorTerms": [
{
"matchExpressions": [
{
"key": "beta.kubernetes.io/instance-type",
"operator": "In",
"values": ["n1-highmem-2", "n1-highmem-4"]
}
]
}
]
}
}
}
http://kubernetes.github.io/docs/user-guide/node-selection/
Implemented through Annotations in 1.2,
through fields in 1.3
Can be ‘Required’ or ‘Preferred’ during
scheduling
In future can can be ‘Required’ during
execution (Node labels can change)
Will eventually replace NodeSelector
If you specify both nodeSelector and
nodeAffinity, both must be satisfied](https://image.slidesharecdn.com/kubeconeu-workingslides-160330022850/85/KubeCon-EU-2016-A-Practical-Guide-to-Container-Scheduling-32-320.jpg)
![@tekgrrl #kubecon #kubernetes
Prefer node with most free resource
left after the pod is deployed
Prefer nodes with the specified label
Minimise number of Pods from the
same service on the same node
CPU and Memory is balanced after the
Pod is deployed [Default]
Pod Scheduling: Ranking Potential Nodes
Node2
Node3
Node1](https://image.slidesharecdn.com/kubeconeu-workingslides-160330022850/85/KubeCon-EU-2016-A-Practical-Guide-to-Container-Scheduling-33-320.jpg)





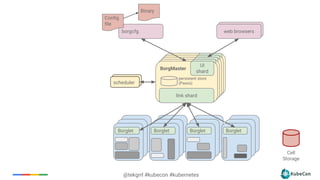
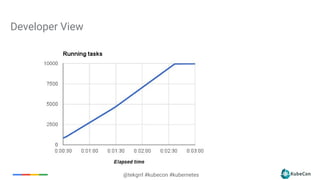
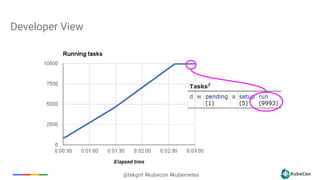
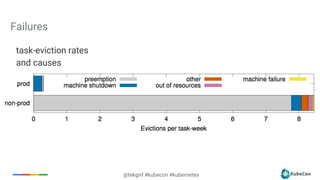
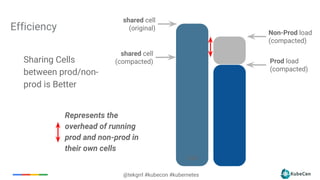
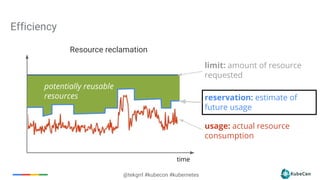
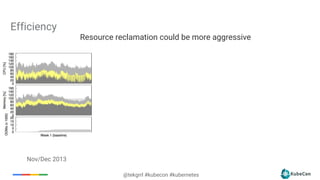
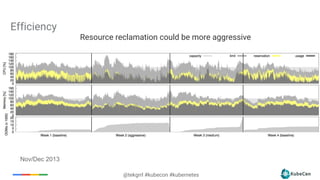
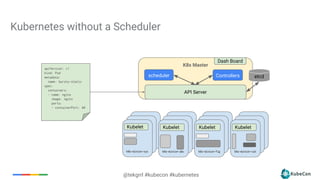
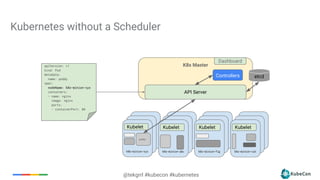
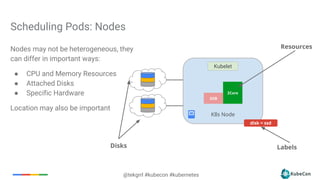
The document provides an overview of container scheduling in Kubernetes, discussing job definitions, resource requirements, and task efficiencies. It emphasizes the use of containers over VMs, resource reclamation, and outlines Kubernetes resource allocation mechanisms. Additionally, it touches on scheduling strategies, nodes, and the importance of admission control in enforcing resource constraints.





























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)






