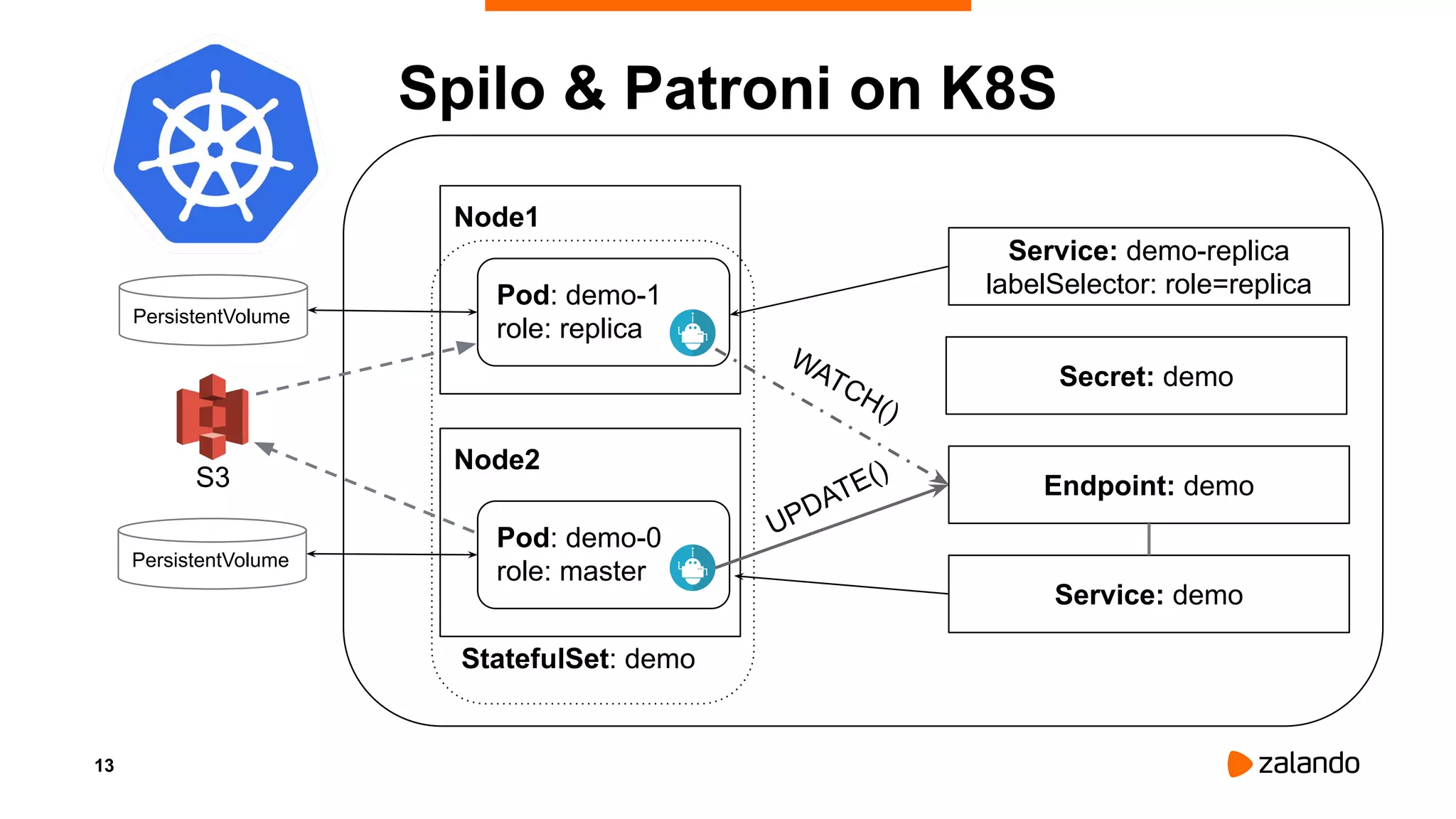
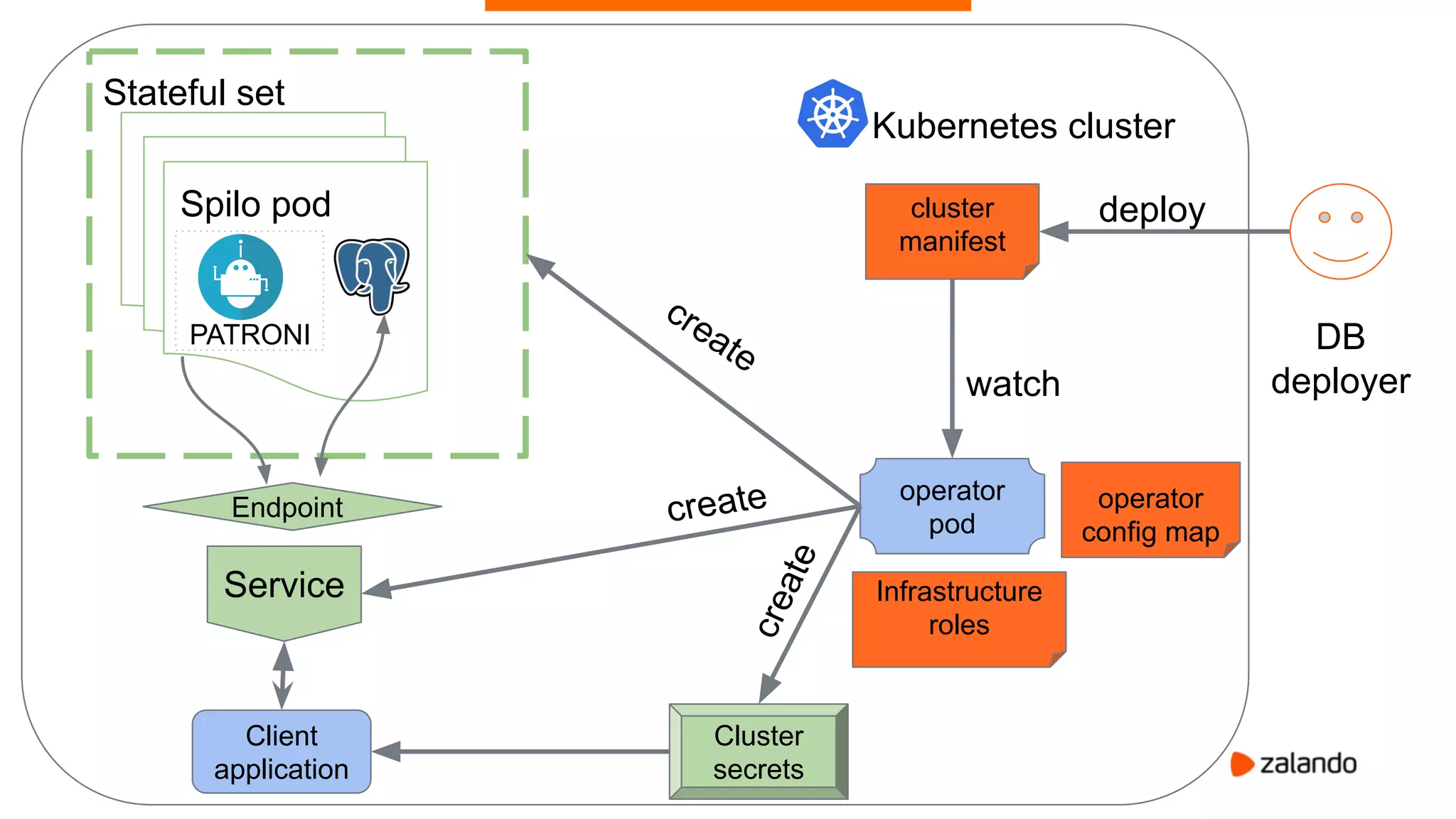
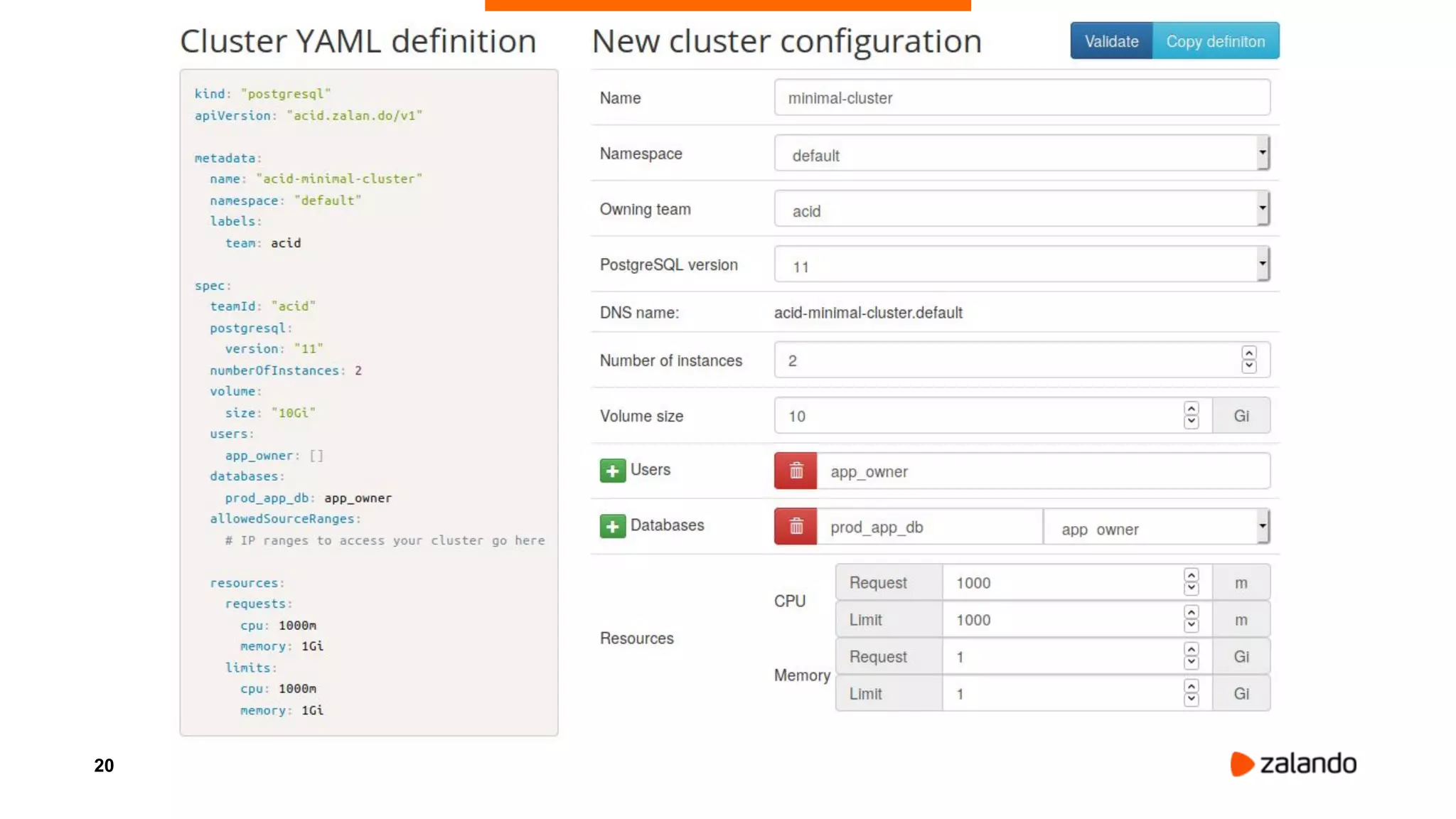
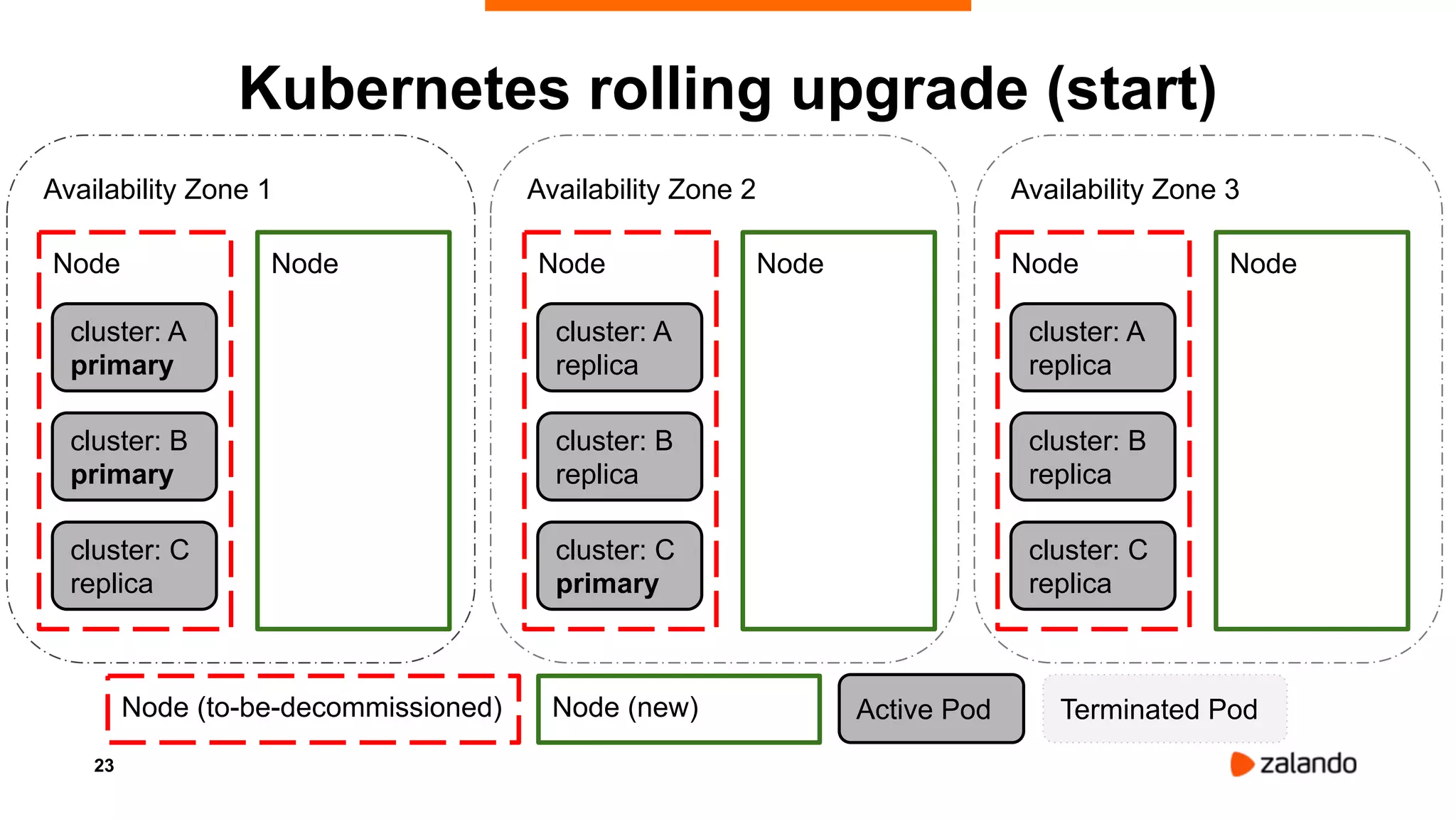
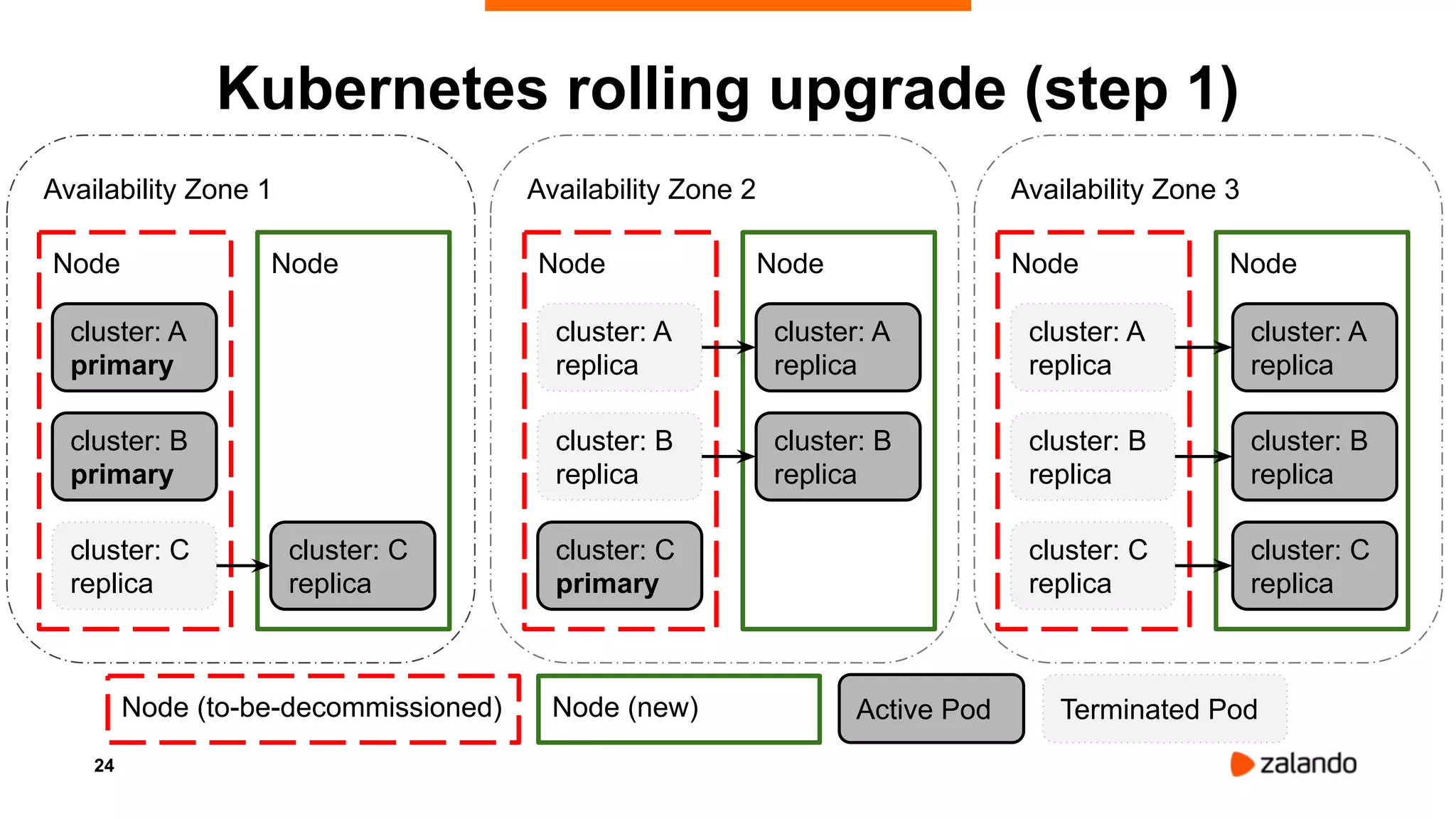
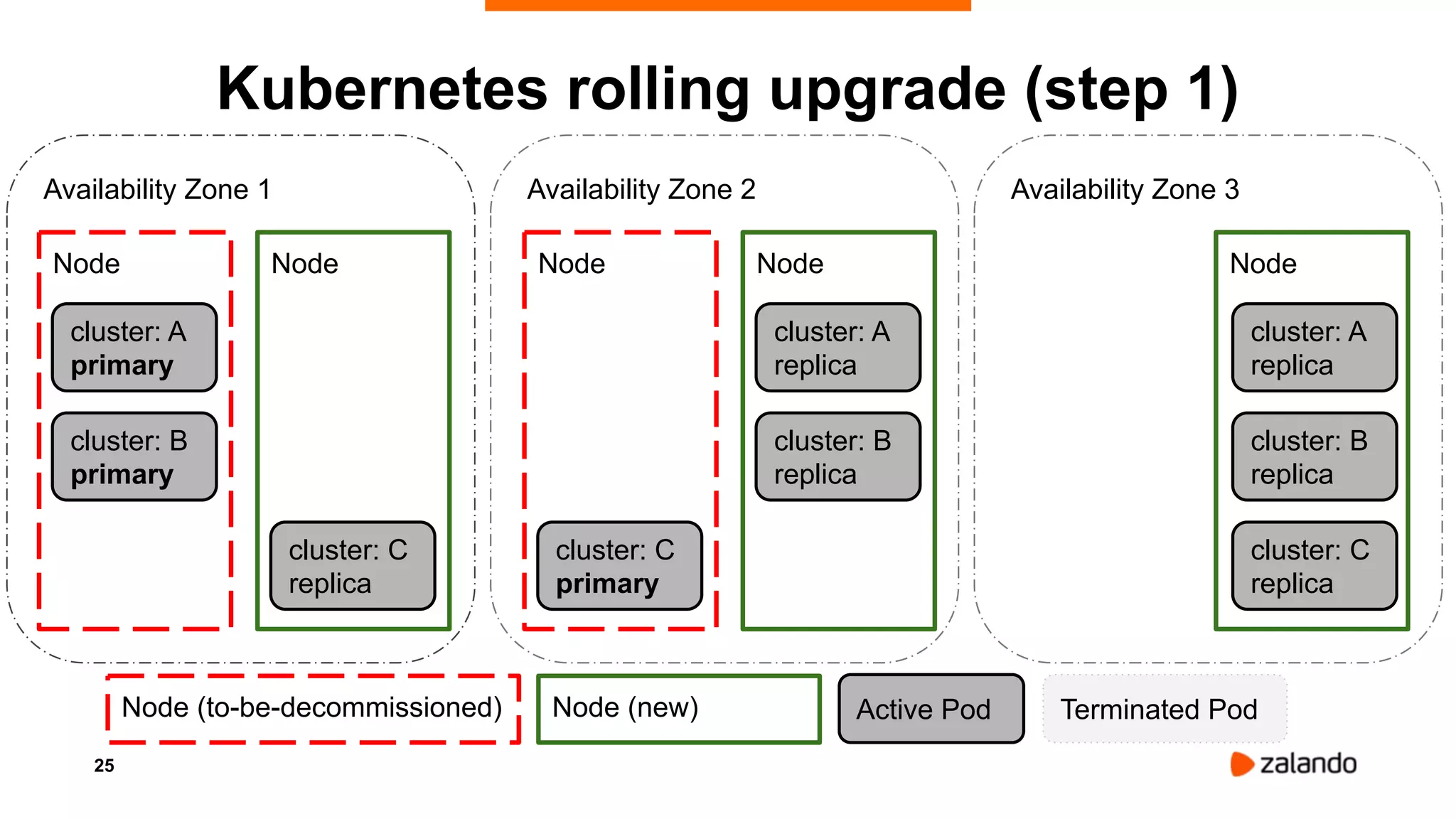
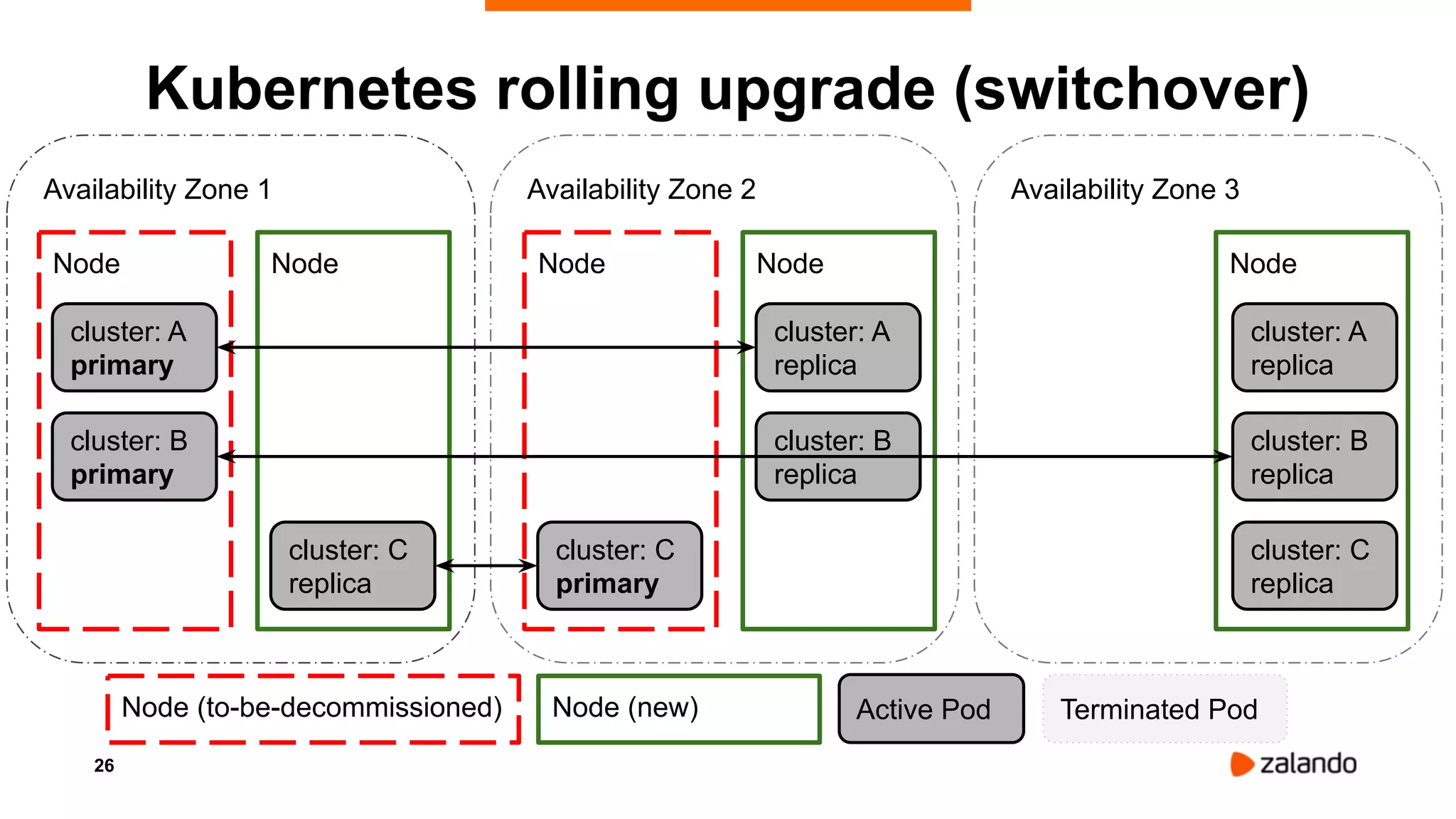
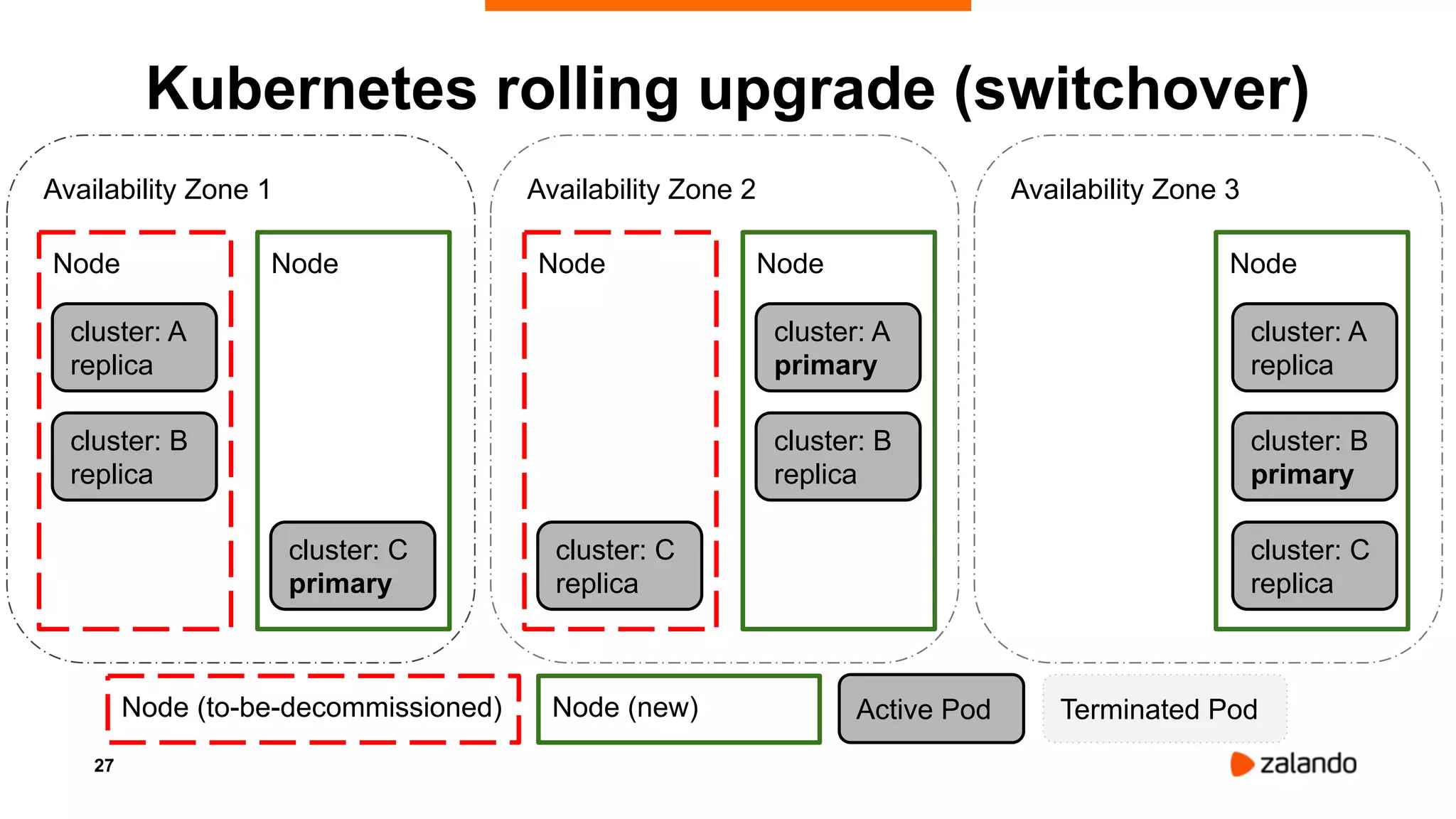
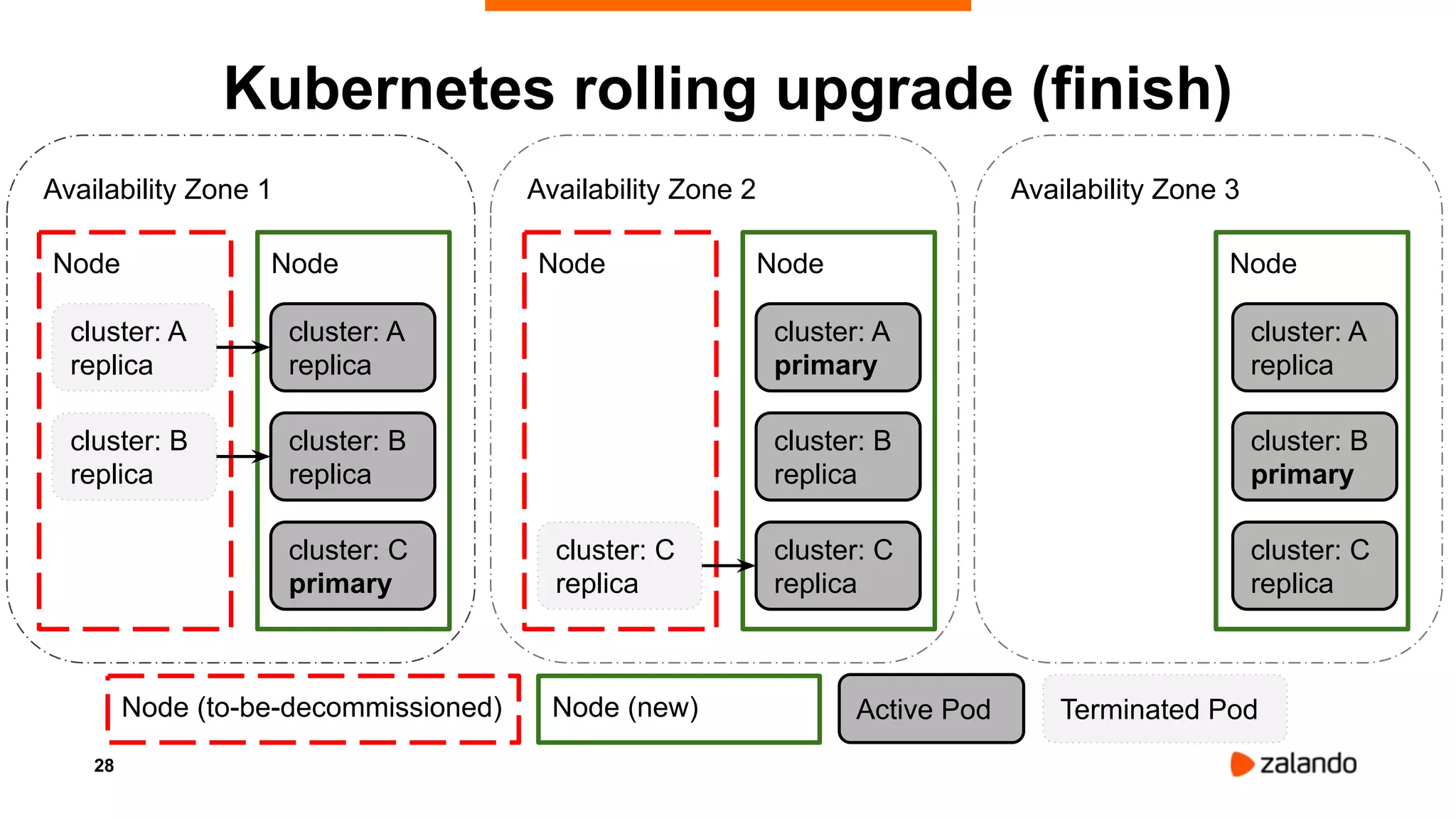
Alexander Kukushkin discusses the implementation of PostgreSQL on Kubernetes at Zalando, focusing on the use of Spilo and Patroni for high availability and management of over 1000 PostgreSQL clusters. The presentation covers Kubernetes architecture, problem-solving strategies, and the features of Zalando's PostgreSQL operator to automate cluster management. Key challenges include AWS infrastructure limitations, disk space management, and ensuring efficient resource utilization in a cloud environment.





















![36
● Postgres log:
server process (PID 10810) was terminated by signal 9: Killed
● dmesg -T:
[Wed Jul 31 01:35:35 2019] Memory cgroup out of memory: Kill process 14208
(postgres) score 606 or sacrifice child
[Wed Jul 31 01:35:35 2019] Killed process 14208 (postgres) total-vm:2972124kB,
anon-rss:68724kB, file-rss:1304kB, shmem-rss:2691844kB
[Wed Jul 31 01:35:35 2019] oom_reaper: reaped process 14208 (postgres), now
anon-rss:0kB, file-rss:0kB, shmem-rss:2691844kB
Out-Of-Memory Killer](https://image.slidesharecdn.com/slides20190910acidsess9-190919050818/75/PGConf-ASIA-2019-Bali-PostgreSQL-on-K8S-at-Zalando-Alexander-Kukushkin-36-2048.jpg)



























































![[EWTT2022] Strategi Implementasi Database dalam Microservice Architecture.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ewtt2022strategiimplementasidatabasedalammicroservicearchitecture-231219102438-d44c1626-thumbnail.jpg?width=640&height=640&fit=bounds)




























![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)




