Downloaded 103 times







![From Twitter to Pub/Sub
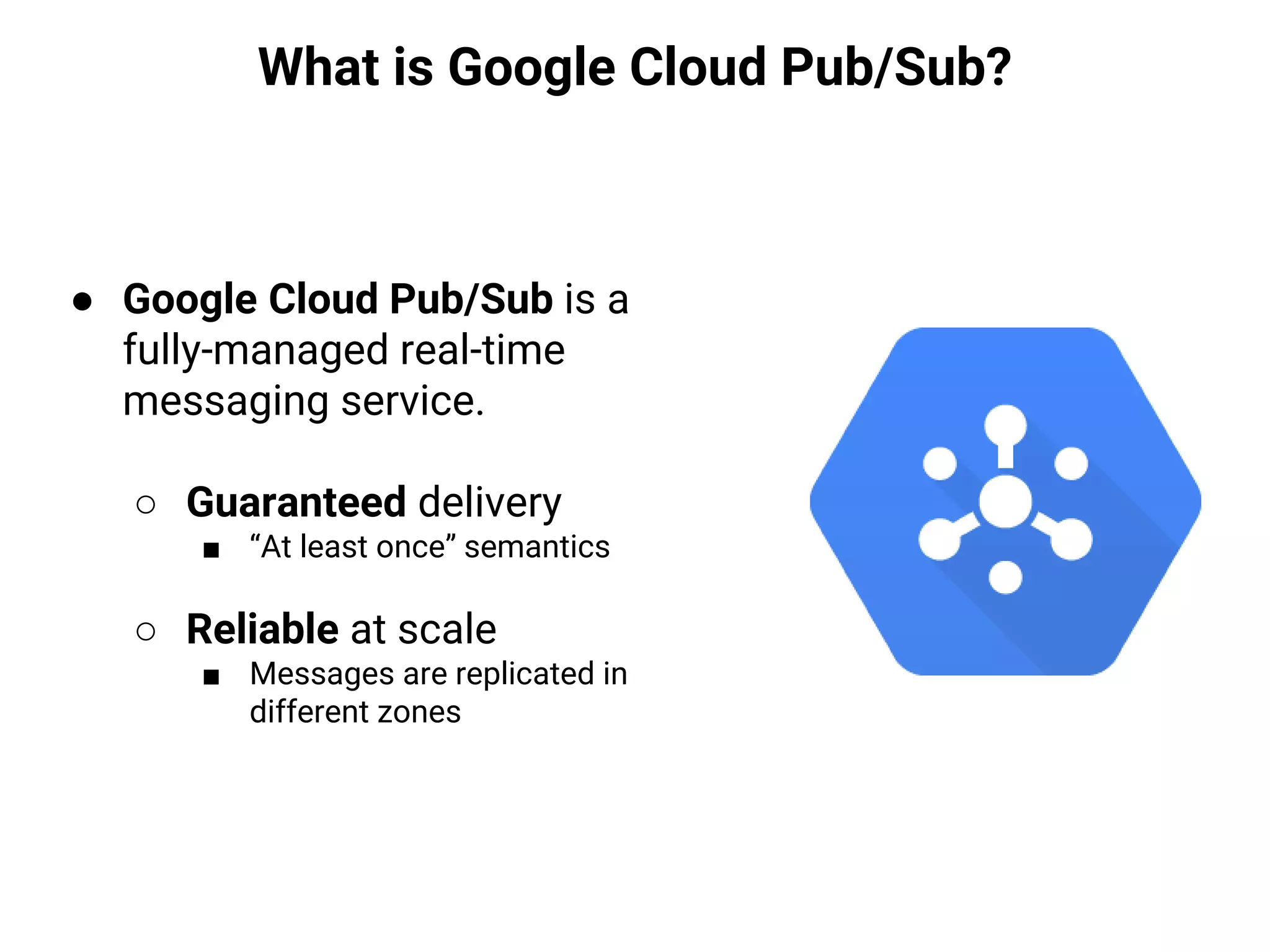
$ gcloud beta pubsub topics create blackfridaytweets
Created topic [blackfridaytweets].
SHELL](https://image.slidesharecdn.com/20170202-lorenzoridi-serverlessdataarchitectureatscaleongooglecloudplatform-170203144020/75/Serverless-Data-Architecture-at-scale-on-Google-Cloud-Platform-17-2048.jpg)
![From Twitter to Pub/Sub
● Simple Python application using the TweePy library
# somewhere in the code, track a given set of keywords
stream = Stream(auth, listener)
stream.filter(track=['blackfriday', [...]])
[...]
# somewhere else, write messages to Pub/Sub
for line in data_lines:
pub = base64.urlsafe_b64encode(line)
messages.append({'data': pub})
body = {'messages': messages}
resp = client.projects().topics().publish(
topic='blackfridaytweets', body=body).execute(num_retries=NUM_RETRIES)
PYTHON](https://image.slidesharecdn.com/20170202-lorenzoridi-serverlessdataarchitectureatscaleongooglecloudplatform-170203144020/75/Serverless-Data-Architecture-at-scale-on-Google-Cloud-Platform-19-2048.jpg)





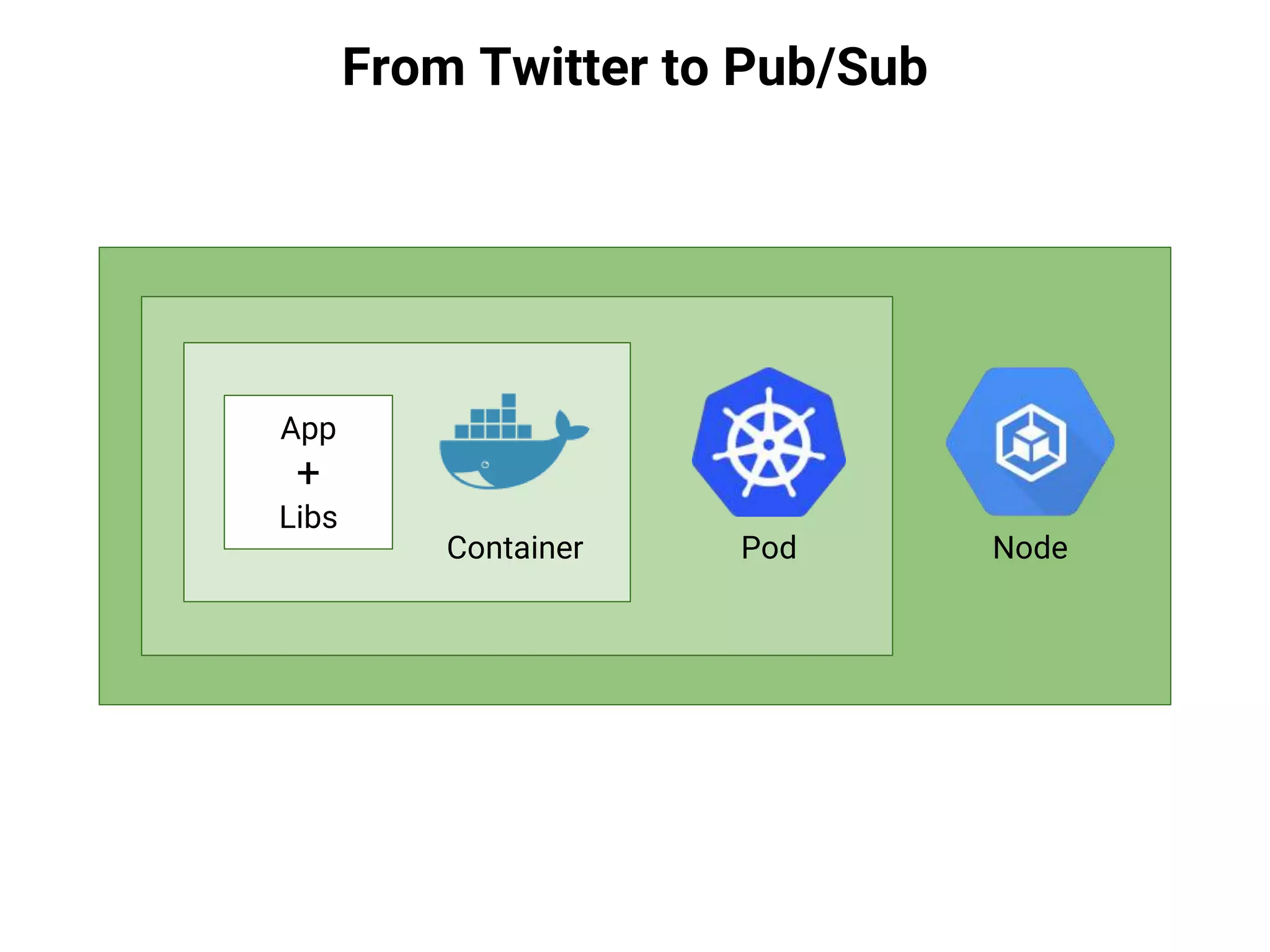
![From Twitter to Pub/Sub
App
+
Libs
Container Pod
apiVersion: v1
kind: ReplicationController
metadata:
[...]
Spec:
replicas: 1
template:
metadata:
labels:
name: twitter-stream
spec:
containers:
- name: twitter-to-pubsub
image: gcr.io/codemotion-2016-demo/pubsub_pipeline
env:
- name: PUBSUB_TOPIC
value: ...
YAML](https://image.slidesharecdn.com/20170202-lorenzoridi-serverlessdataarchitectureatscaleongooglecloudplatform-170203144020/75/Serverless-Data-Architecture-at-scale-on-Google-Cloud-Platform-28-2048.jpg)
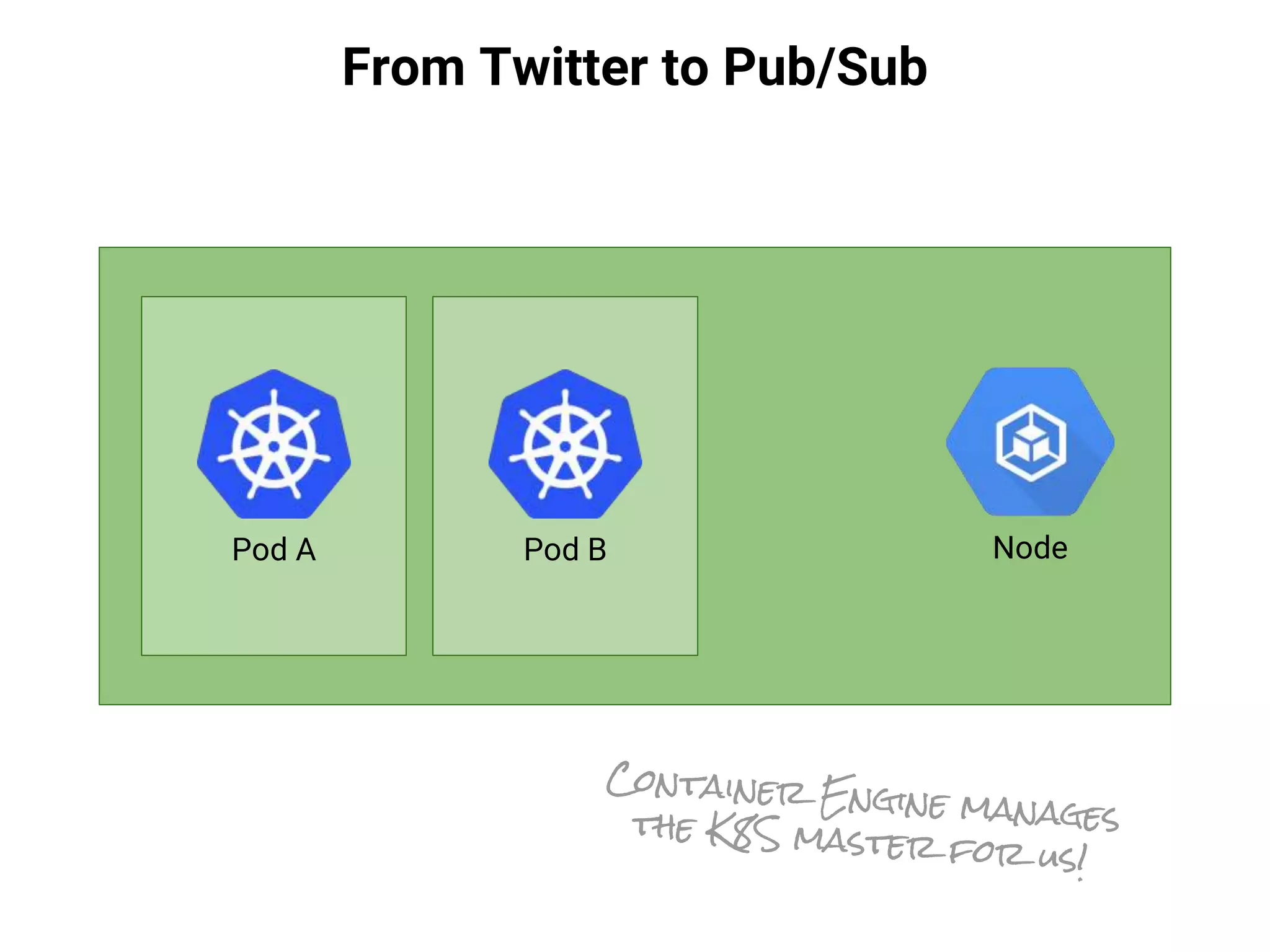
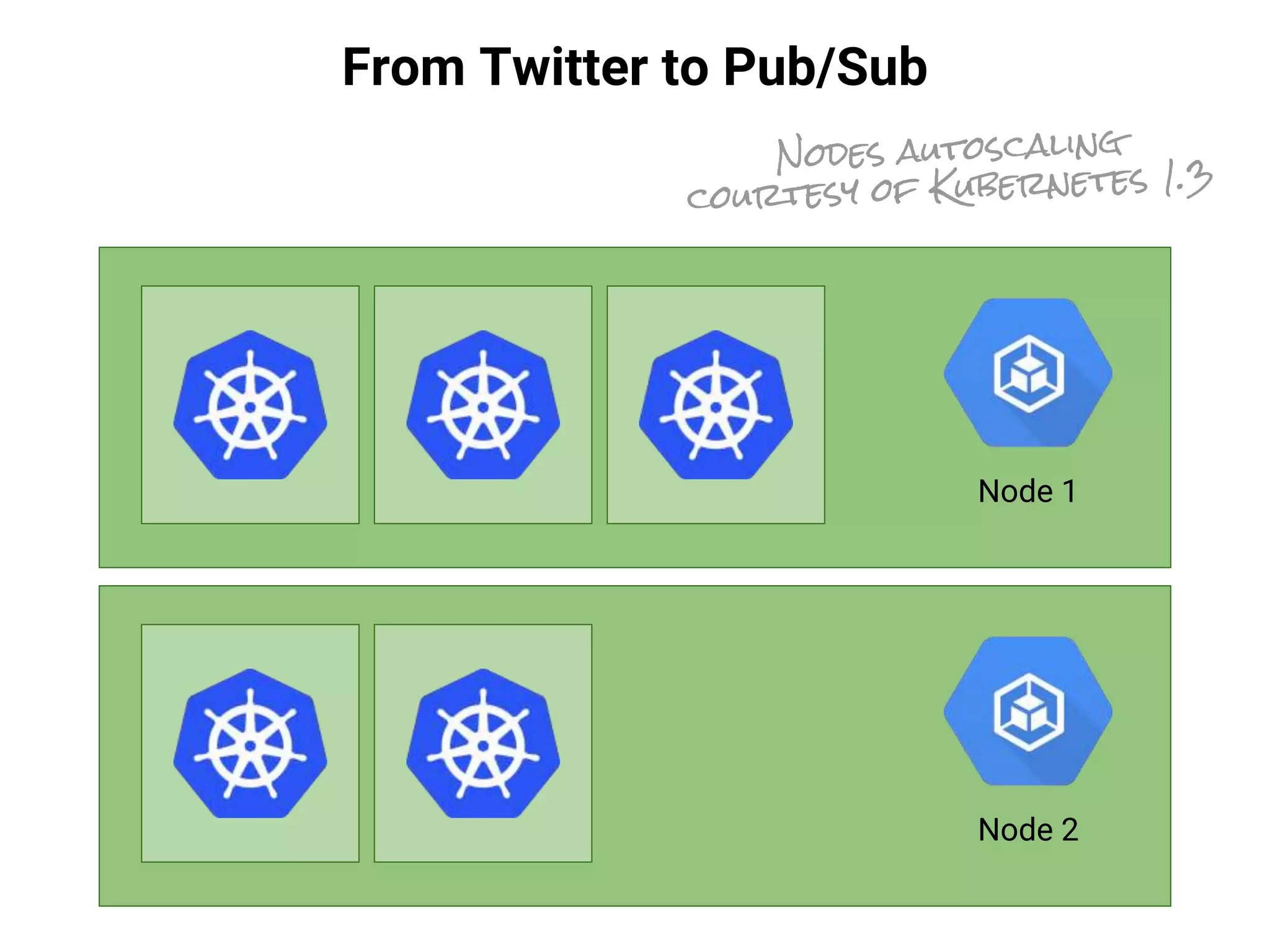
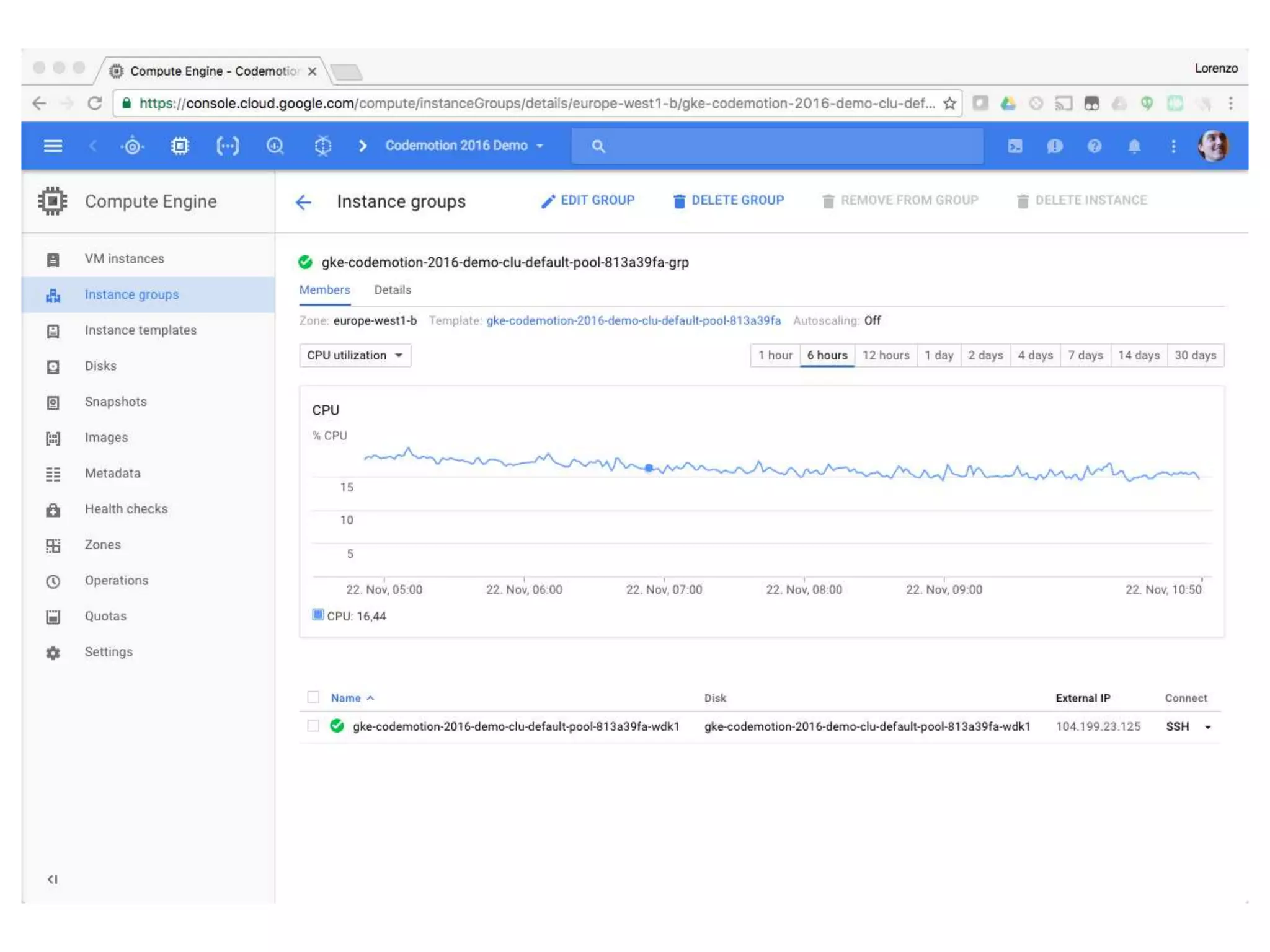
![From Twitter to Pub/Sub
$ gcloud container clusters create codemotion-2016-demo-cluster
Creating cluster cluster-1...done.
Created [...projects/codemotion-2016-demo/.../clusters/codemotion-2016-demo-cluster].
$ gcloud container clusters get-credentials codemotion-2016-demo-cluster
Fetching cluster endpoint and auth data.
kubeconfig entry generated for cluster-1.
$ kubectl create -f ~/git/kube-pubsub-bq/pubsub/twitter-stream.yaml
replicationcontroller “twitter-stream” created.
SHELL](https://image.slidesharecdn.com/20170202-lorenzoridi-serverlessdataarchitectureatscaleongooglecloudplatform-170203144020/75/Serverless-Data-Architecture-at-scale-on-Google-Cloud-Platform-33-2048.jpg)
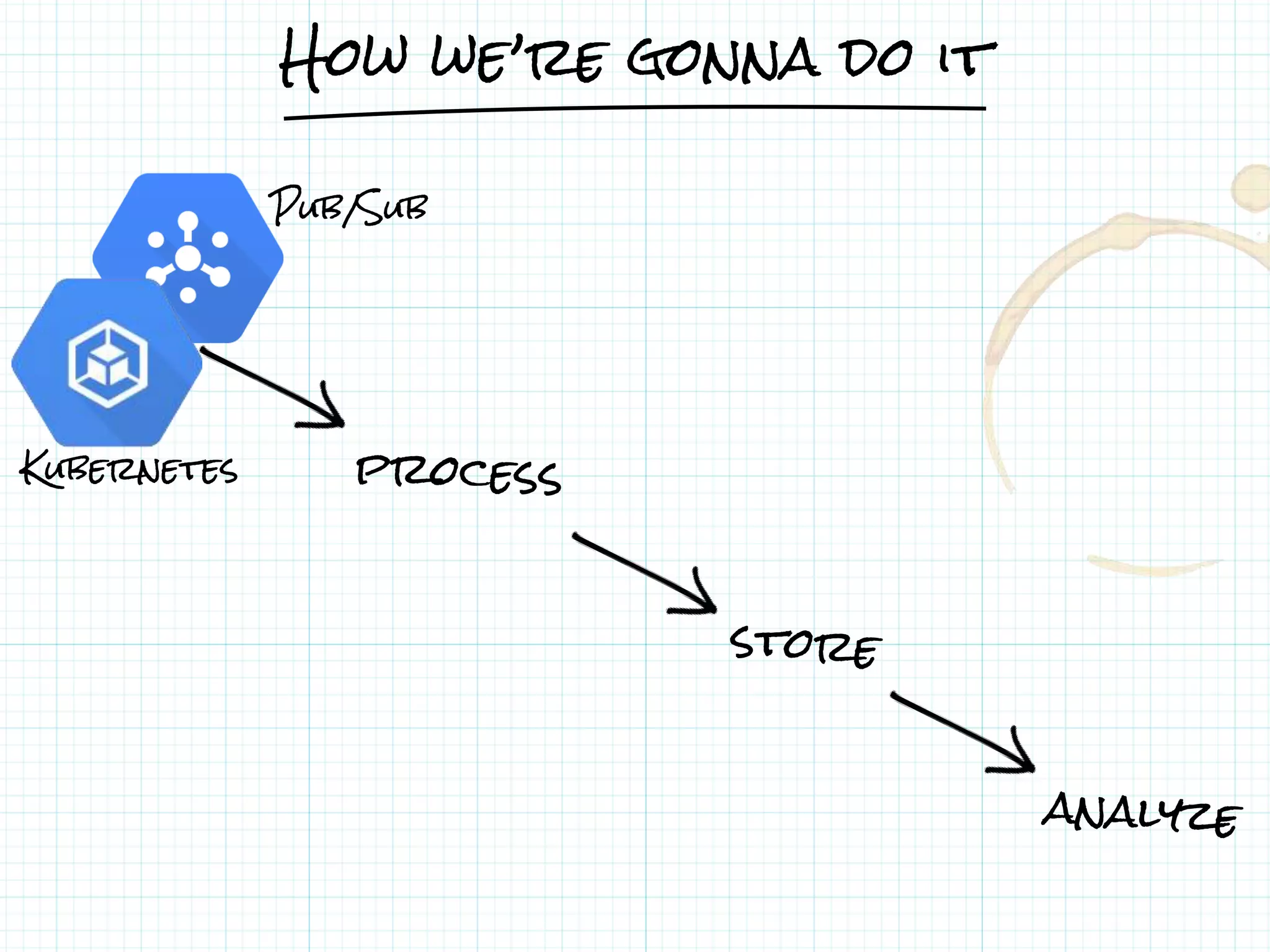
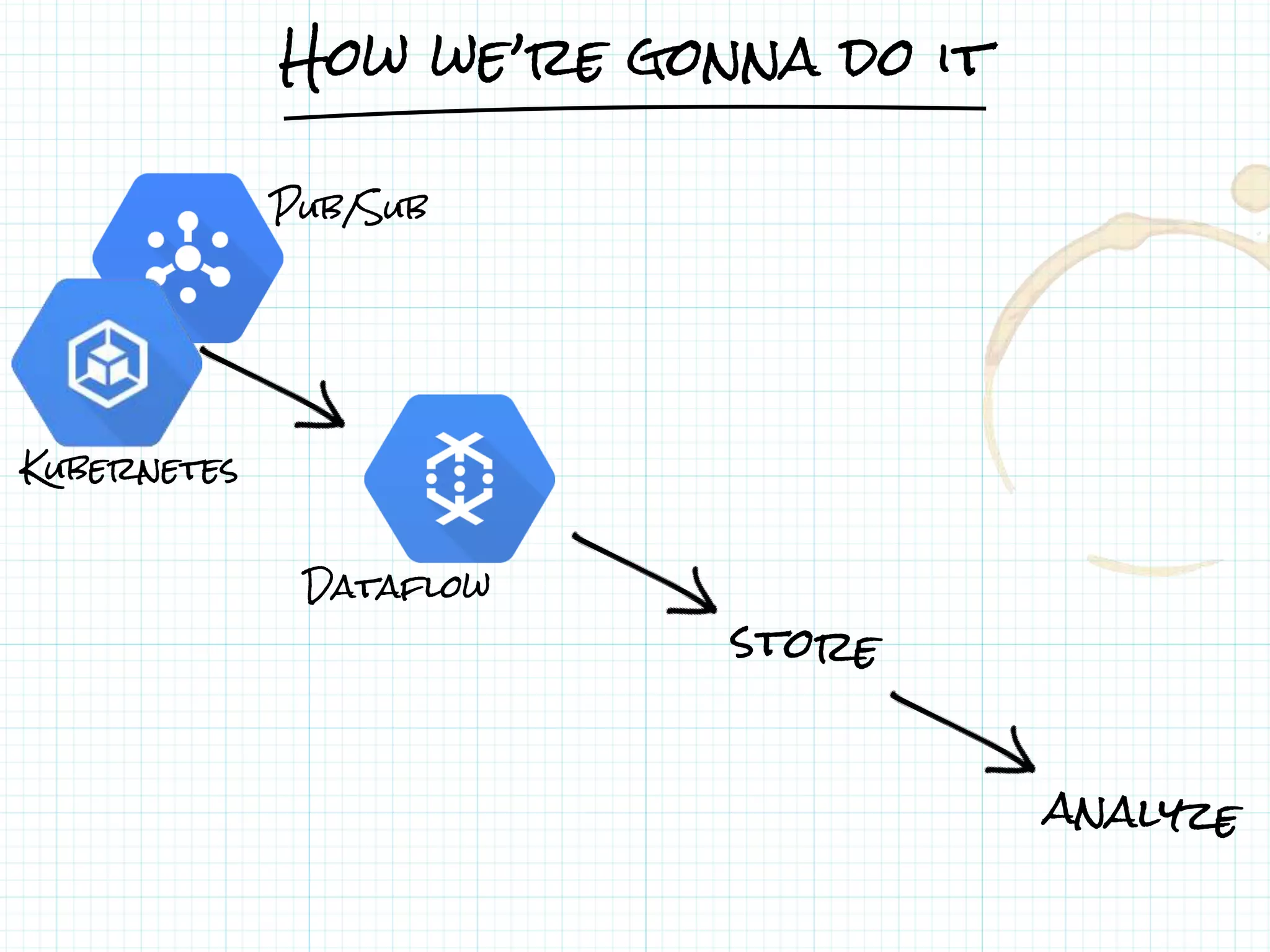
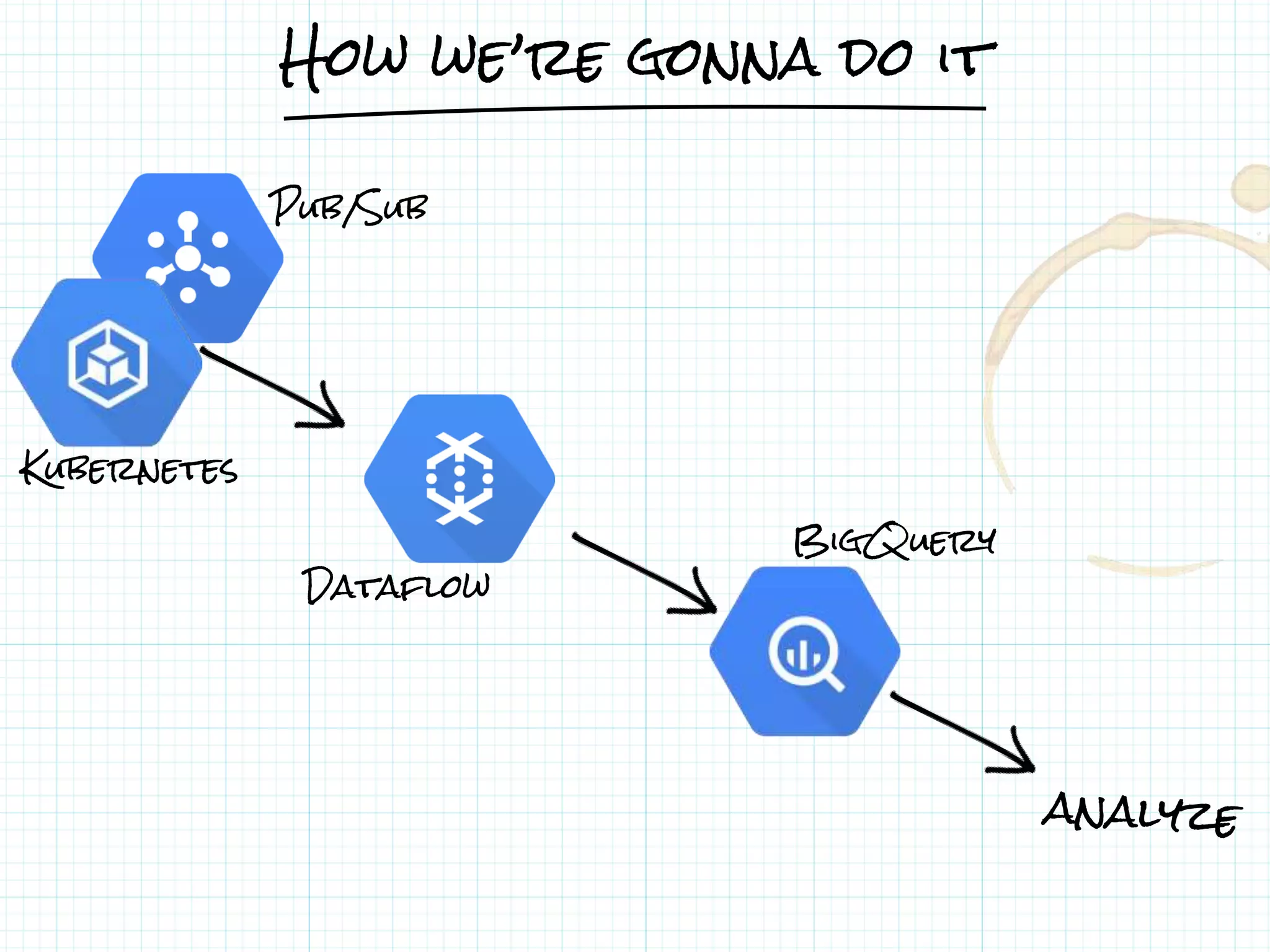
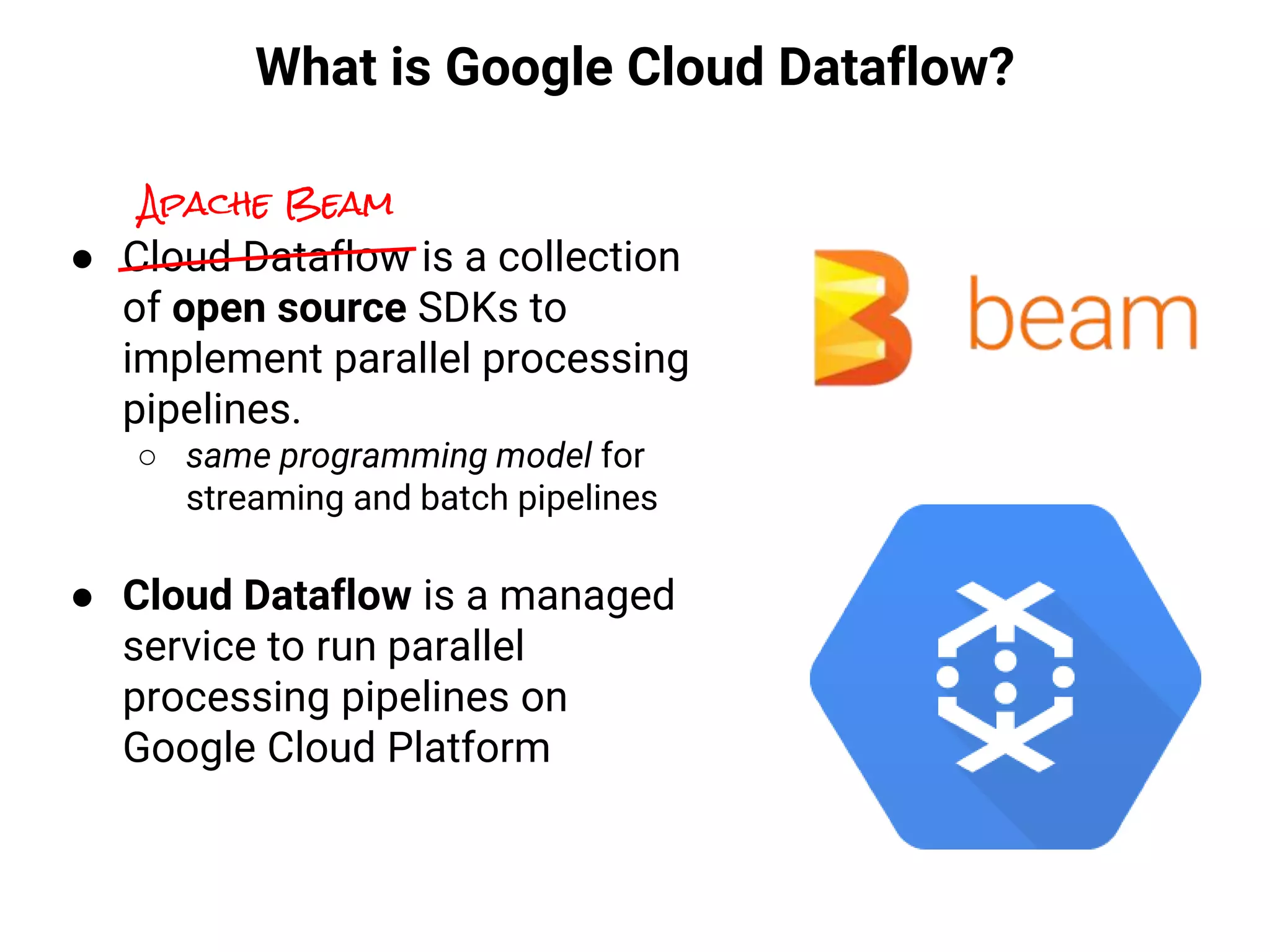

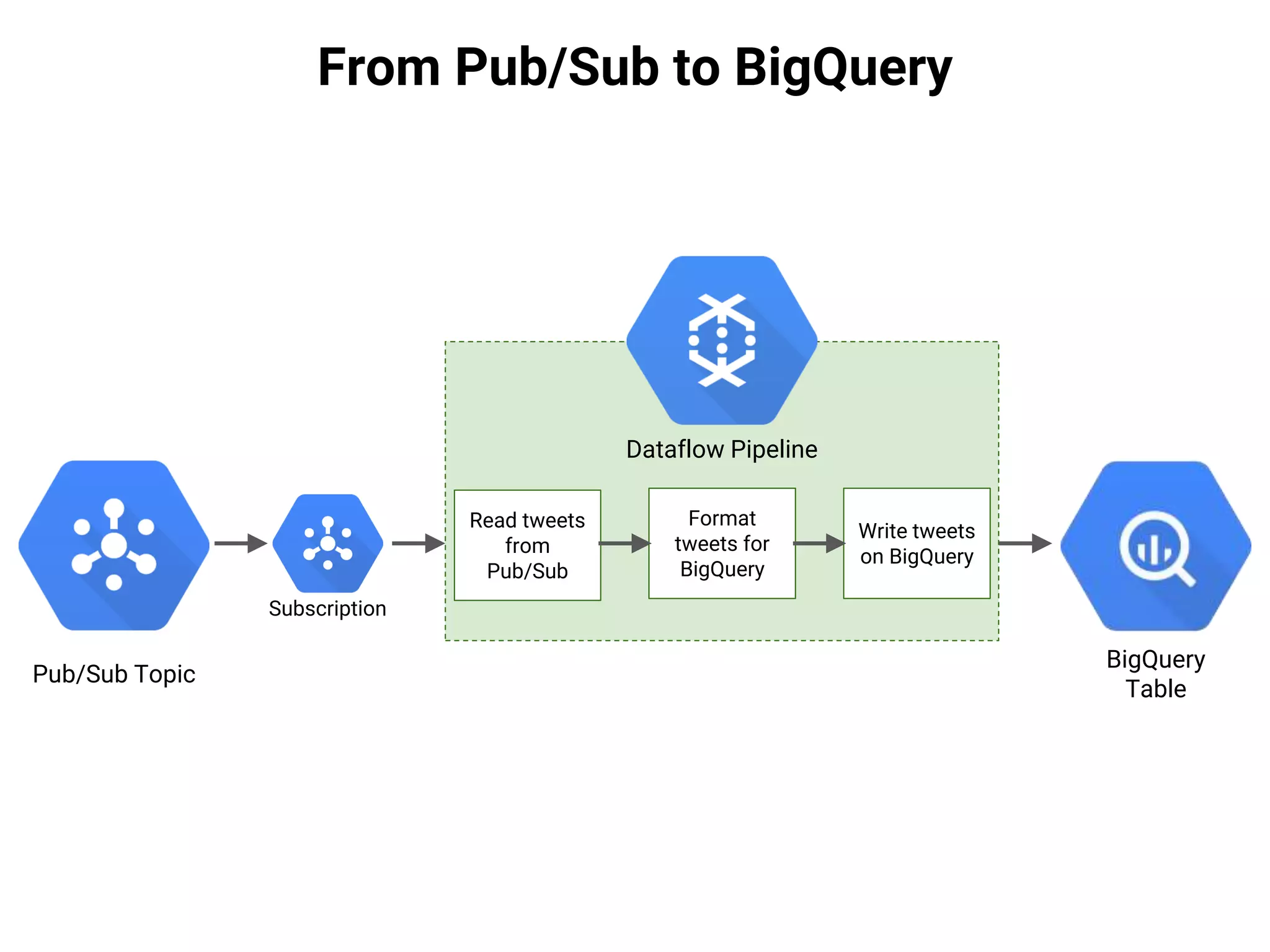
![From Pub/Sub to BigQuery
● A Dataflow pipeline is a Java program.
// TwitterProcessor.java
public static void main(String[] args) {
Pipeline p = Pipeline.create();
PCollection<String> tweets = p.apply(PubsubIO.Read.topic("...blackfridaytweets"));
PCollection<TableRow> formattedTweets = tweets.apply(ParDo.of(new DoFormat()));
formattedTweets.apply(BigQueryIO.Write.to(tableReference));
p.run();
}
JAVA](https://image.slidesharecdn.com/20170202-lorenzoridi-serverlessdataarchitectureatscaleongooglecloudplatform-170203144020/75/Serverless-Data-Architecture-at-scale-on-Google-Cloud-Platform-41-2048.jpg)

![From Pub/Sub to BigQuery
● Use Maven to build, deploy or update the Pipeline.
$ mvn compile exec:java -Dexec.mainClass=it.noovle.dataflow.TwitterProcessor
-Dexec.args="--streaming"
[...]
INFO: To cancel the job using the 'gcloud' tool, run:
> gcloud alpha dataflow jobs --project=codemotion-2016-demo cancel 2016-11-
19_15_49_53-5264074060979116717
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 18.131s
[INFO] Finished at: Sun Nov 20 00:49:54 CET 2016
[INFO] Final Memory: 28M/362M
[INFO] ------------------------------------------------------------------------
SHELL](https://image.slidesharecdn.com/20170202-lorenzoridi-serverlessdataarchitectureatscaleongooglecloudplatform-170203144020/75/Serverless-Data-Architecture-at-scale-on-Google-Cloud-Platform-43-2048.jpg)

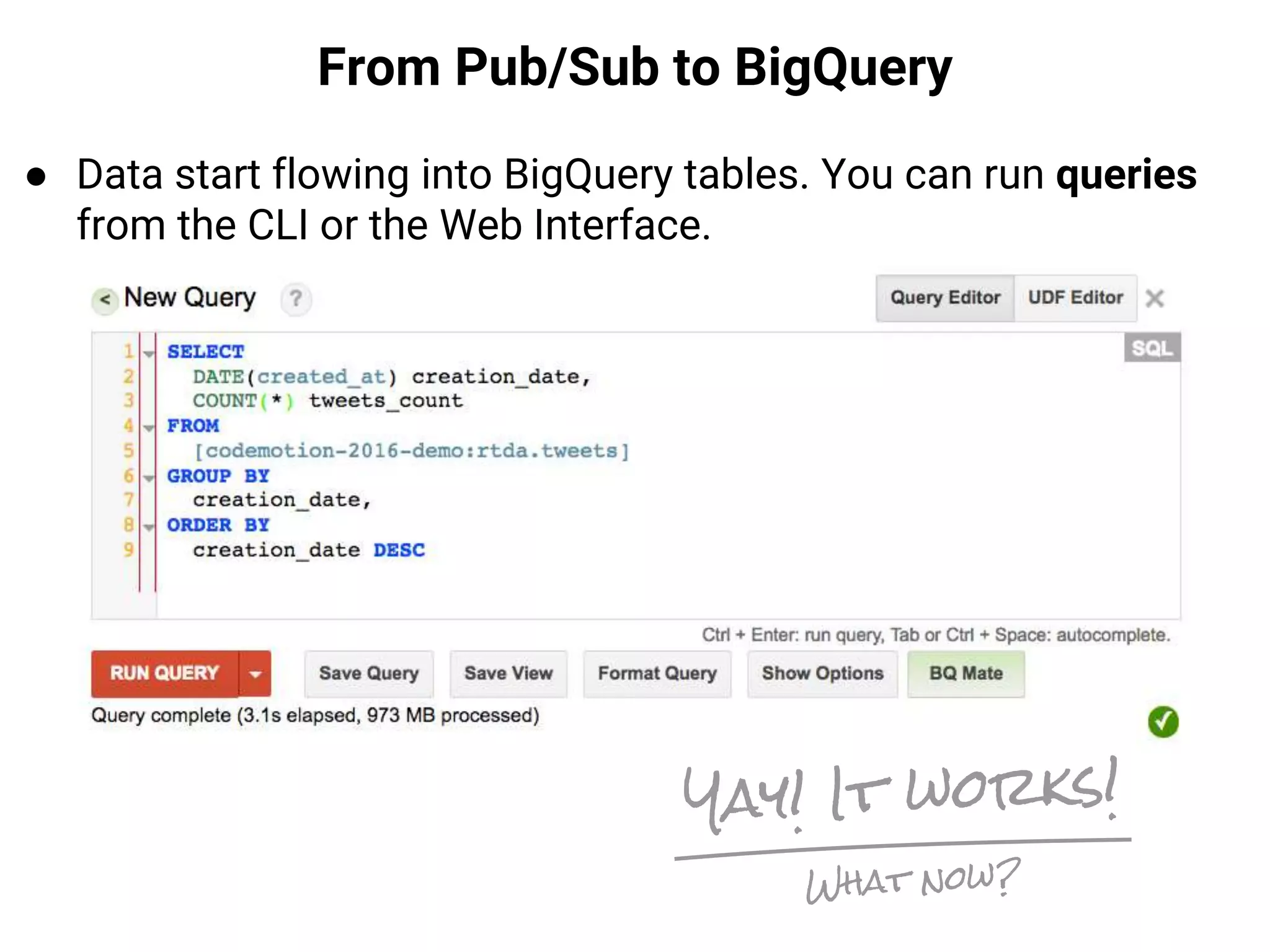
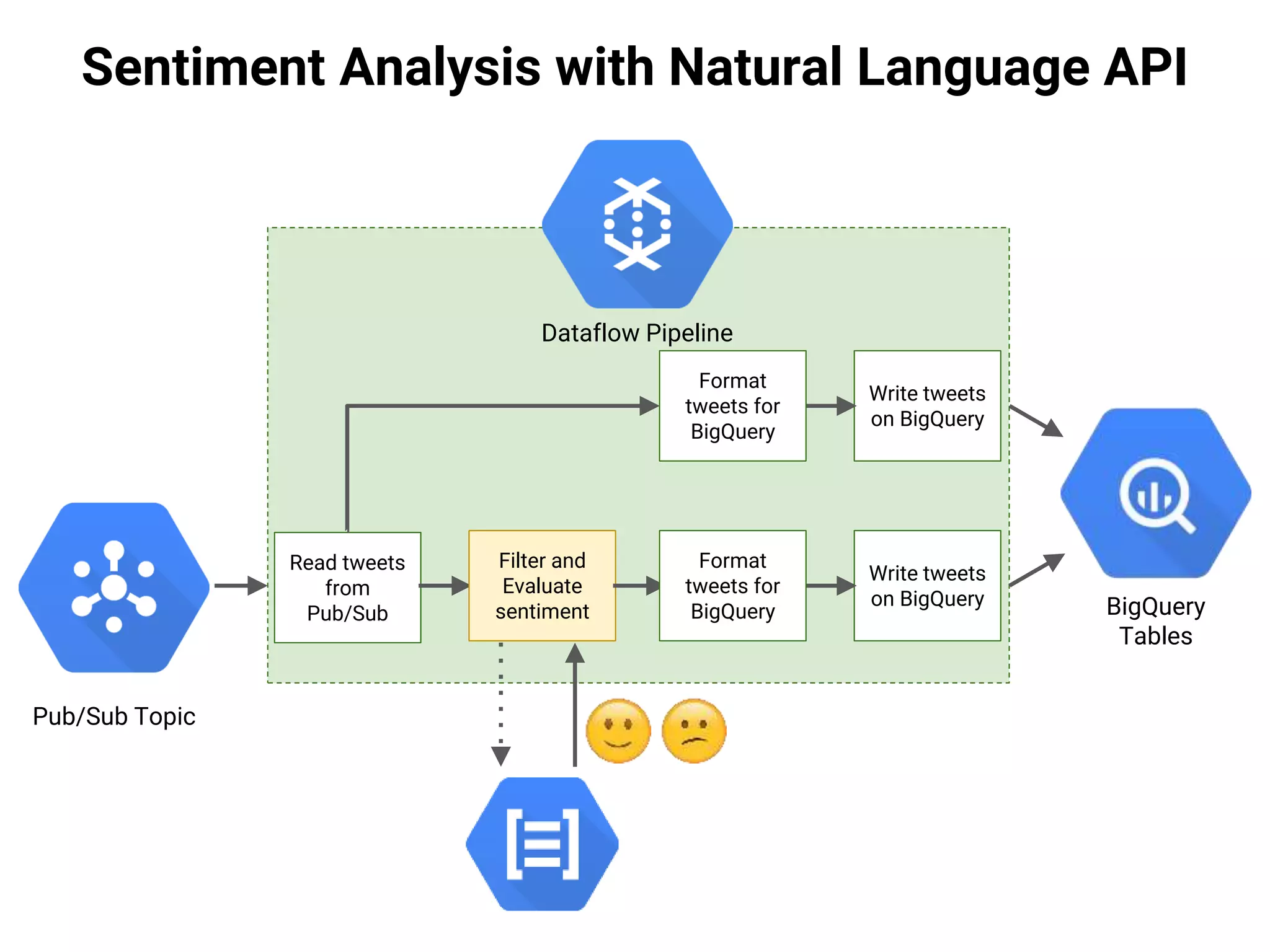
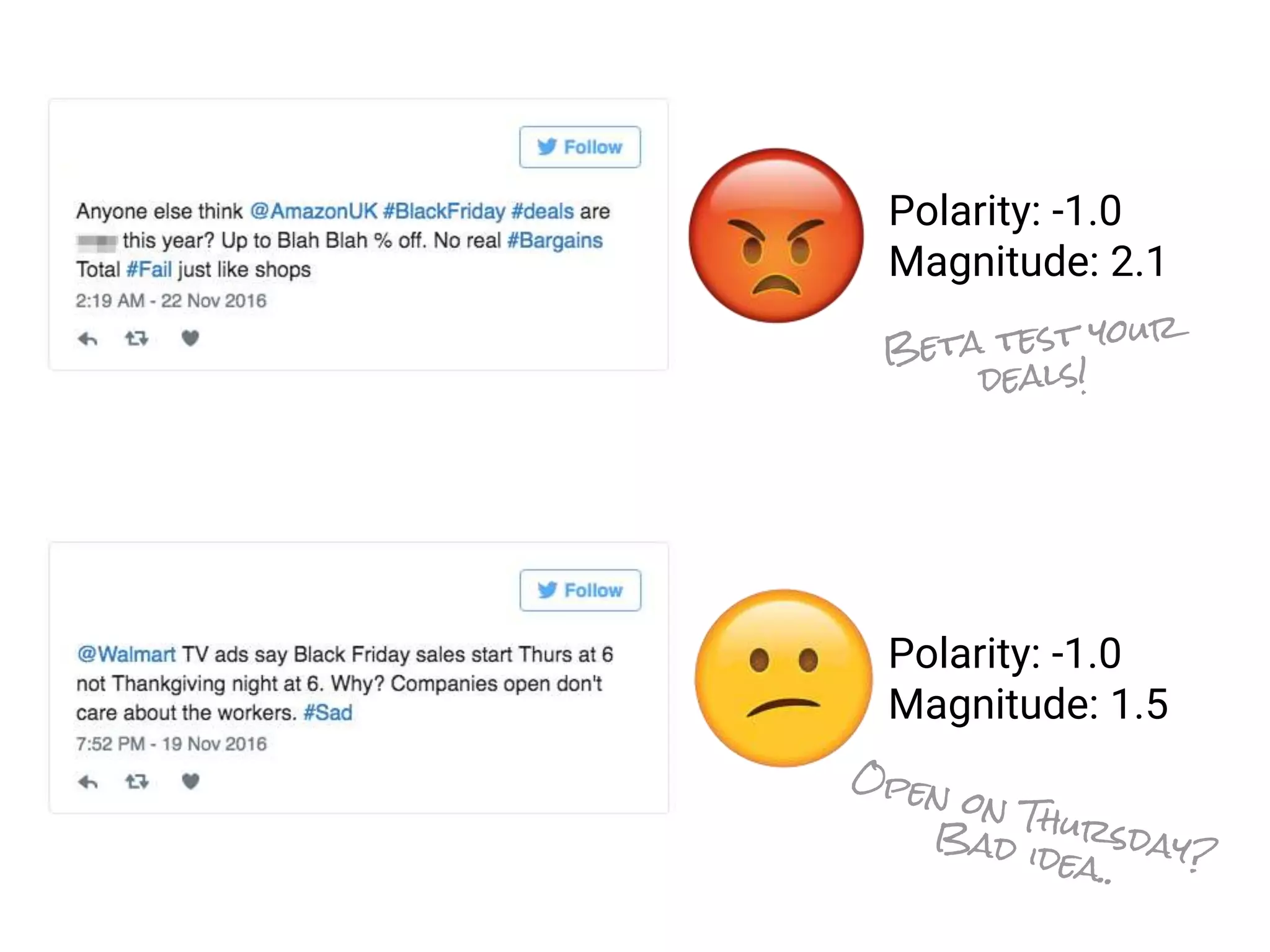
![Sentiment Analysis with Natural Language API
Polarity: [-1,1]
Magnitude: [0,+inf)
Text](https://image.slidesharecdn.com/20170202-lorenzoridi-serverlessdataarchitectureatscaleongooglecloudplatform-170203144020/75/Serverless-Data-Architecture-at-scale-on-Google-Cloud-Platform-51-2048.jpg)
![Sentiment Analysis with Natural Language API
Polarity: [-1,1]
Magnitude: [0,+inf)
Text
sentiment = polarity x magnitude](https://image.slidesharecdn.com/20170202-lorenzoridi-serverlessdataarchitectureatscaleongooglecloudplatform-170203144020/75/Serverless-Data-Architecture-at-scale-on-Google-Cloud-Platform-52-2048.jpg)
![From Pub/Sub to BigQuery
● We just add the additional necessary steps.
// TwitterProcessor.java
public static void main(String[] args) {
Pipeline p = Pipeline.create();
PCollection<String> tweets = p.apply(PubsubIO.Read.topic("...blackfridaytweets"));
PCollection<String> sentTweets = tweets.apply(ParDo.of(new DoFilterAndProcess()));
PCollection<TableRow> formSentTweets = sentTweets.apply(ParDo.of(new DoFormat()));
formSentTweets.apply(BigQueryIO.Write.to(sentTableReference));
PCollection<TableRow> formattedTweets = tweets.apply(ParDo.of(new DoFormat()));
formattedTweets.apply(BigQueryIO.Write.to(tableReference));
p.run();
}
JAVA
PCollection<String> sentTweets = tweets.apply(ParDo.of(new DoFilterAndProcess()));
PCollection<TableRow> formSentTweets = sentTweets.apply(ParDo.of(new DoFormat()));
formSentTweets.apply(BigQueryIO.Write.to(sentTableReference));](https://image.slidesharecdn.com/20170202-lorenzoridi-serverlessdataarchitectureatscaleongooglecloudplatform-170203144020/75/Serverless-Data-Architecture-at-scale-on-Google-Cloud-Platform-54-2048.jpg)
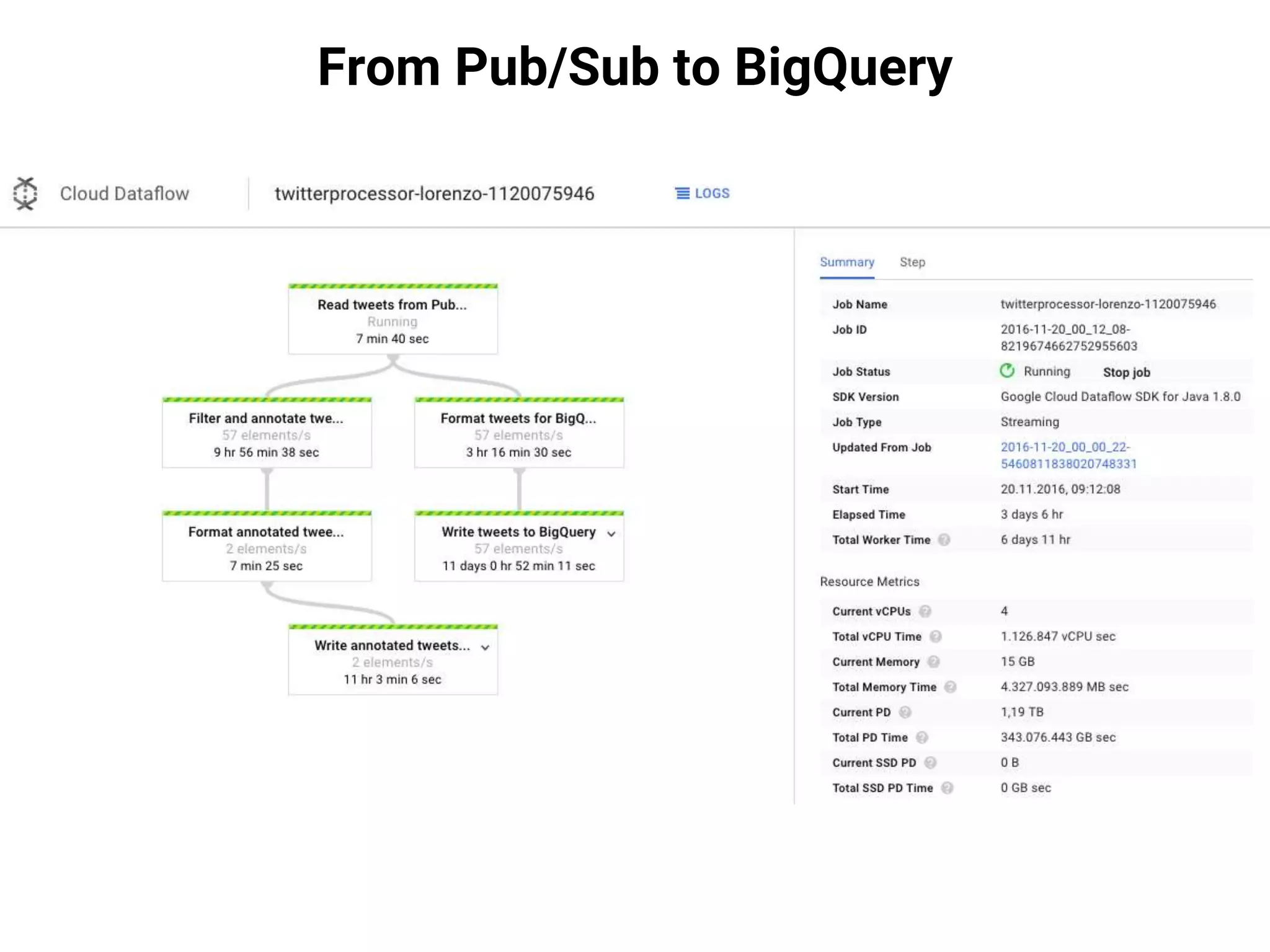
![From Pub/Sub to BigQuery
● The update process preserves all in-flight data.
$ mvn compile exec:java -Dexec.mainClass=it.noovle.dataflow.TwitterProcessor
-Dexec.args="--streaming --update --jobName=twitterprocessor-lorenzo-1107222550"
[...]
INFO: To cancel the job using the 'gcloud' tool, run:
> gcloud alpha dataflow jobs --project=codemotion-2016-demo cancel 2016-11-
19_15_49_53-5264074060979116717
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 18.131s
[INFO] Finished at: Sun Nov 20 00:49:54 CET 2016
[INFO] Final Memory: 28M/362M
[INFO] ------------------------------------------------------------------------
SHELL](https://image.slidesharecdn.com/20170202-lorenzoridi-serverlessdataarchitectureatscaleongooglecloudplatform-170203144020/75/Serverless-Data-Architecture-at-scale-on-Google-Cloud-Platform-55-2048.jpg)
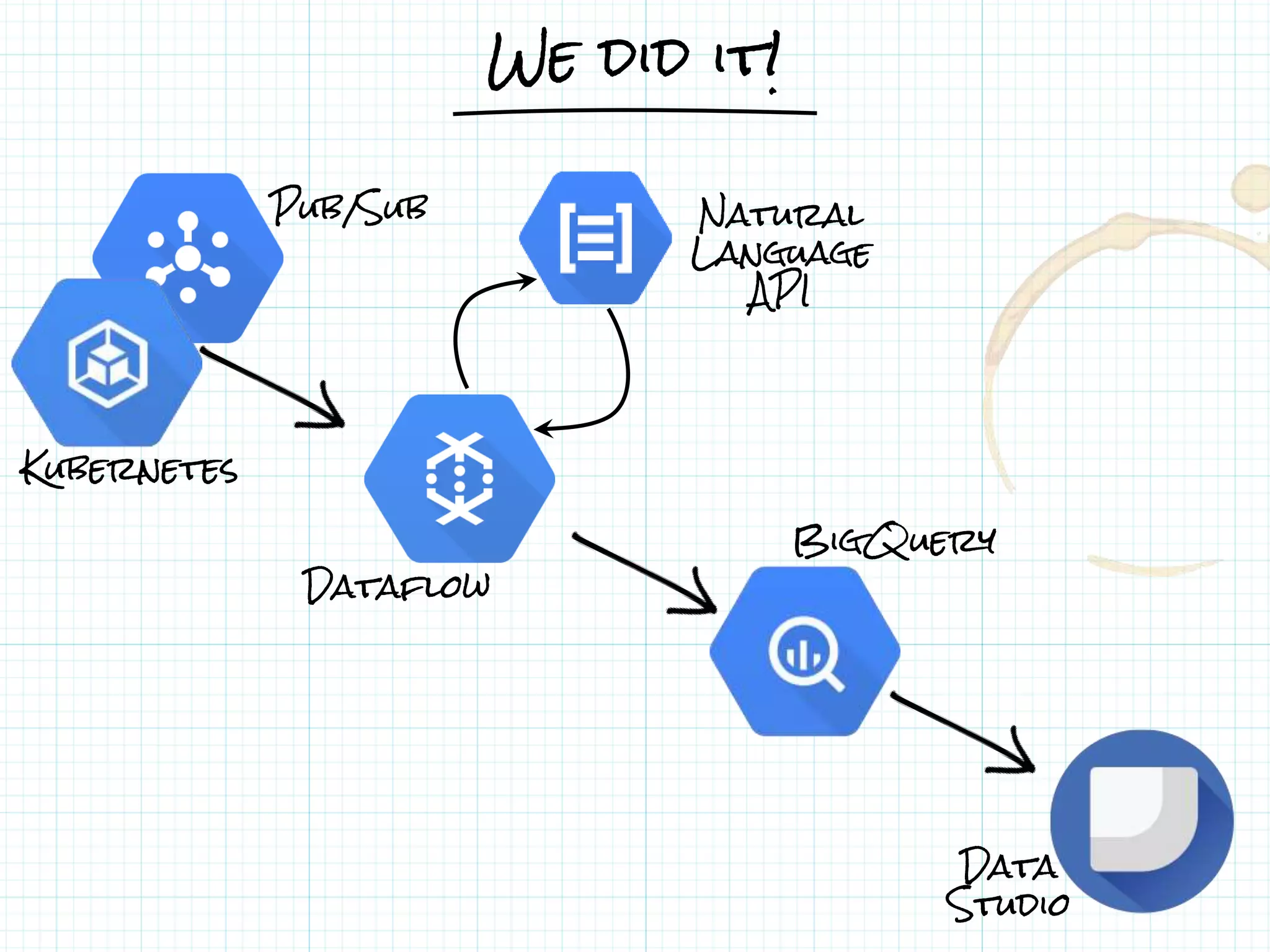
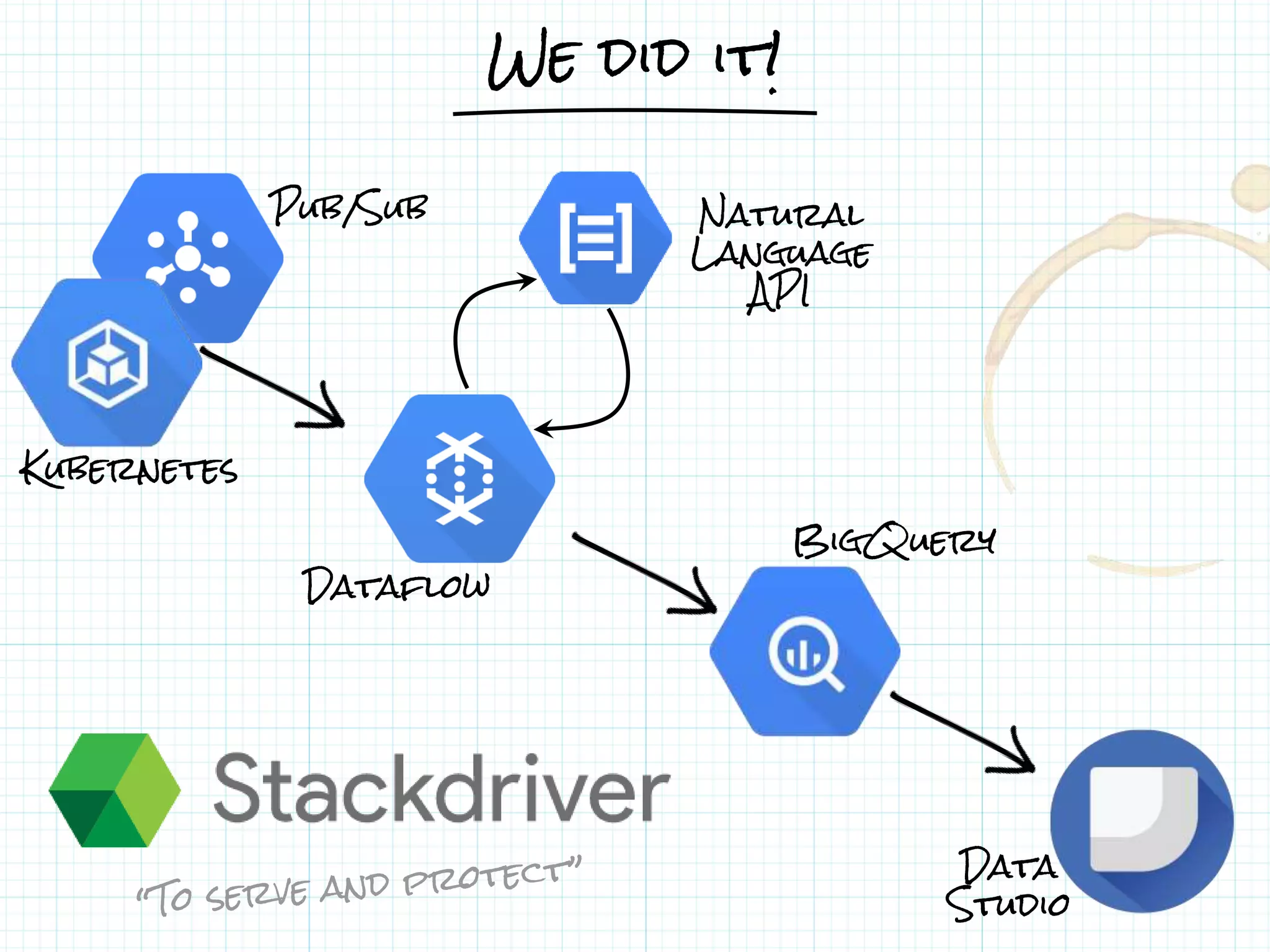



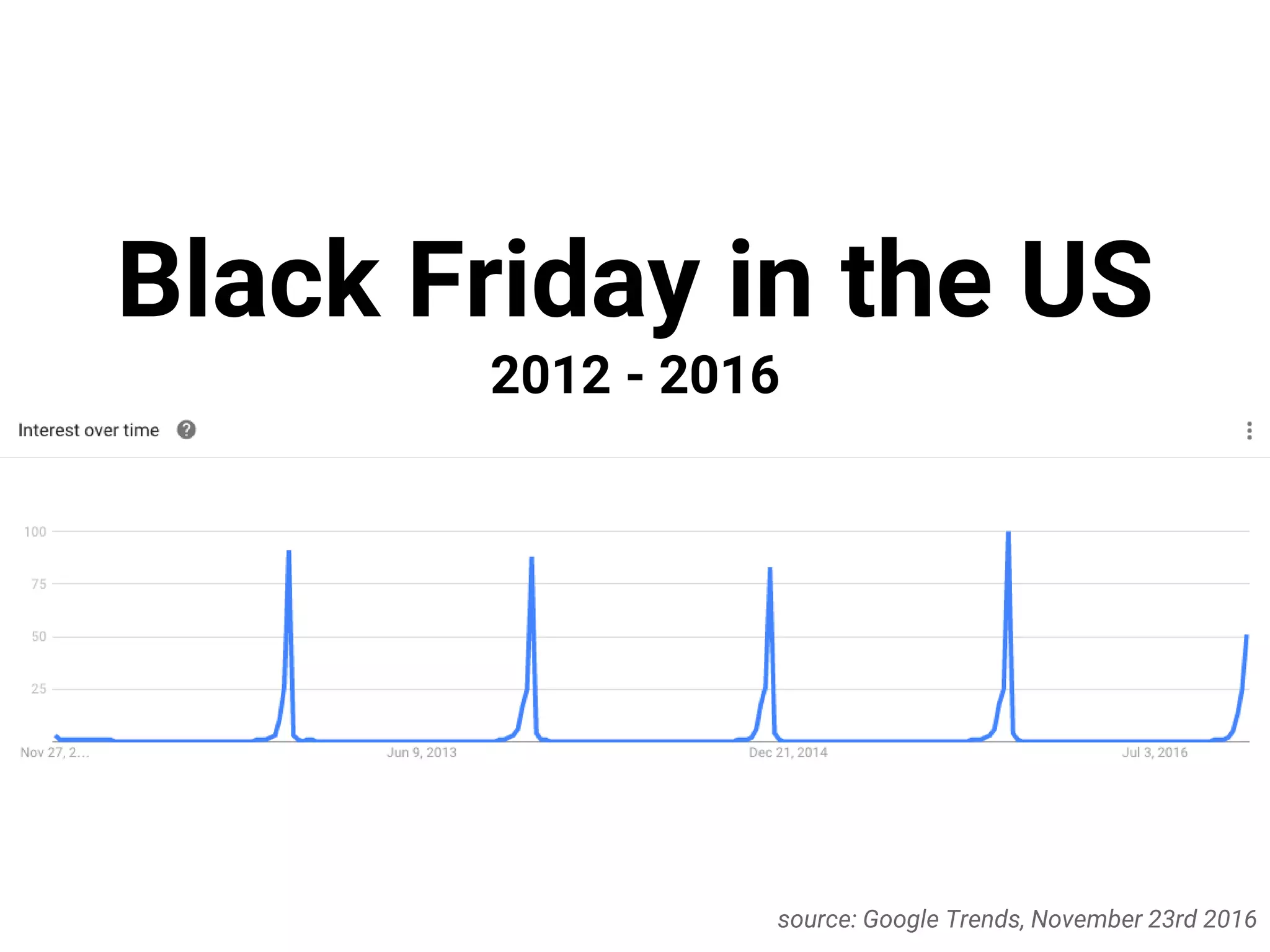
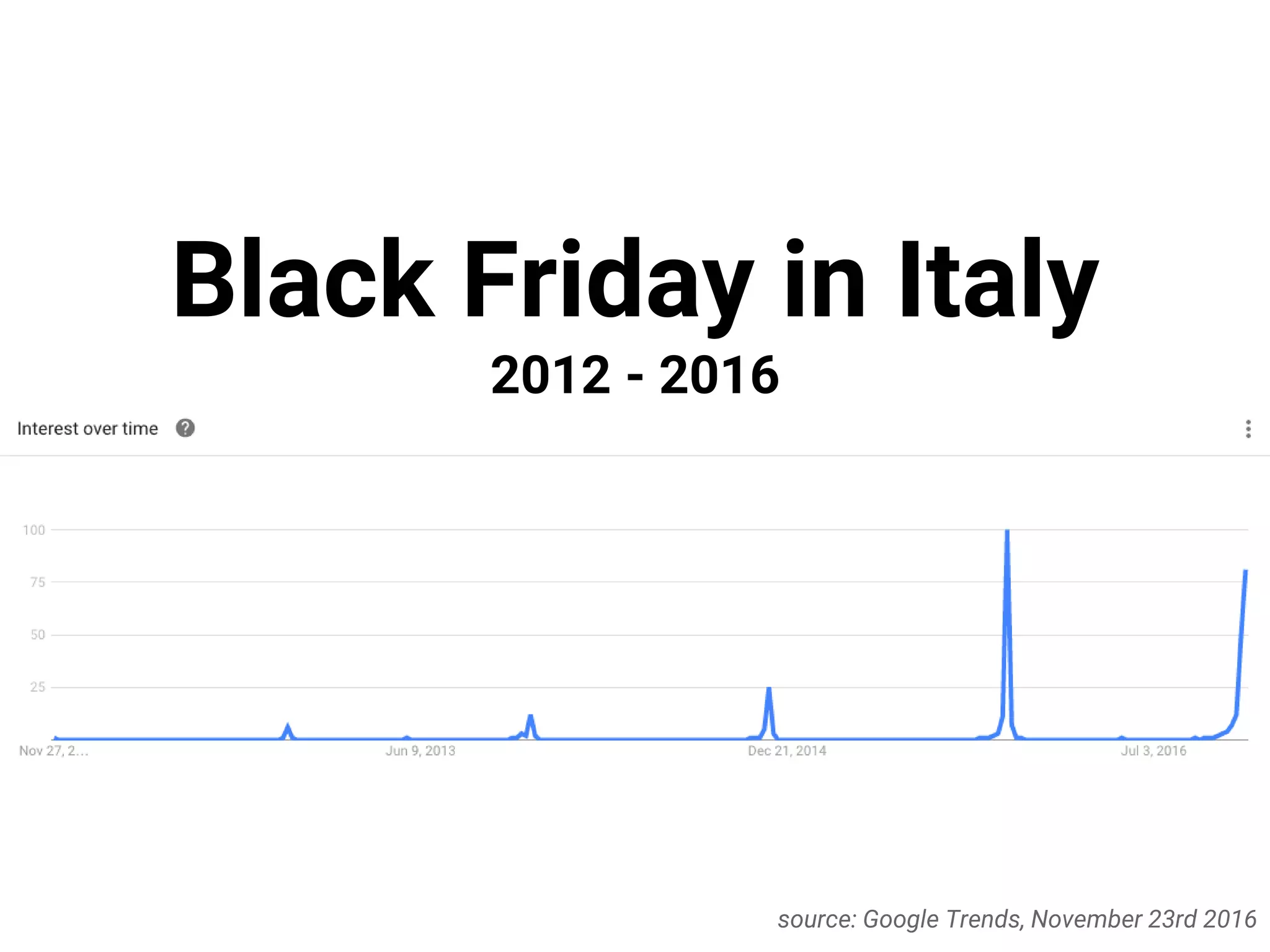
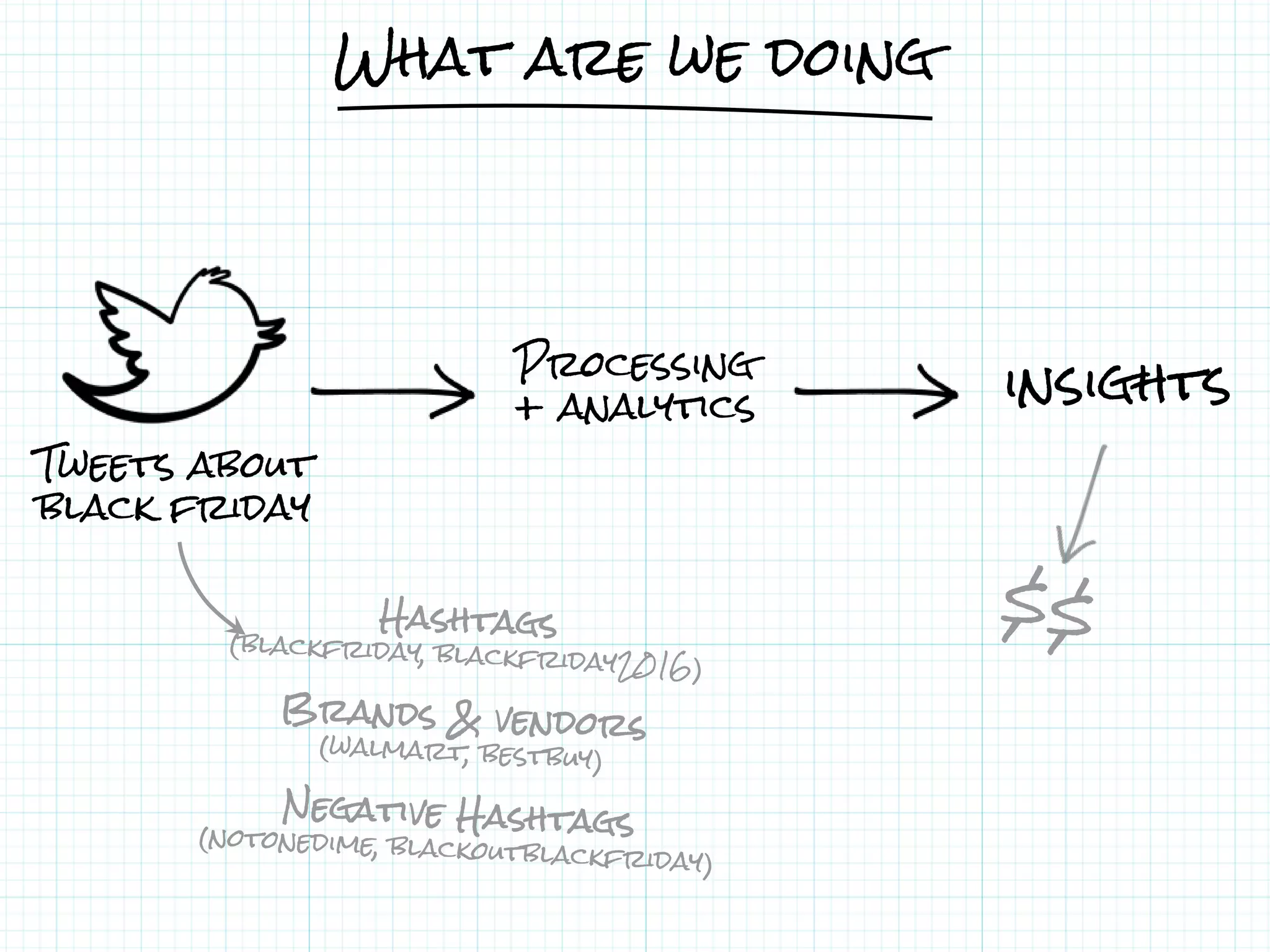
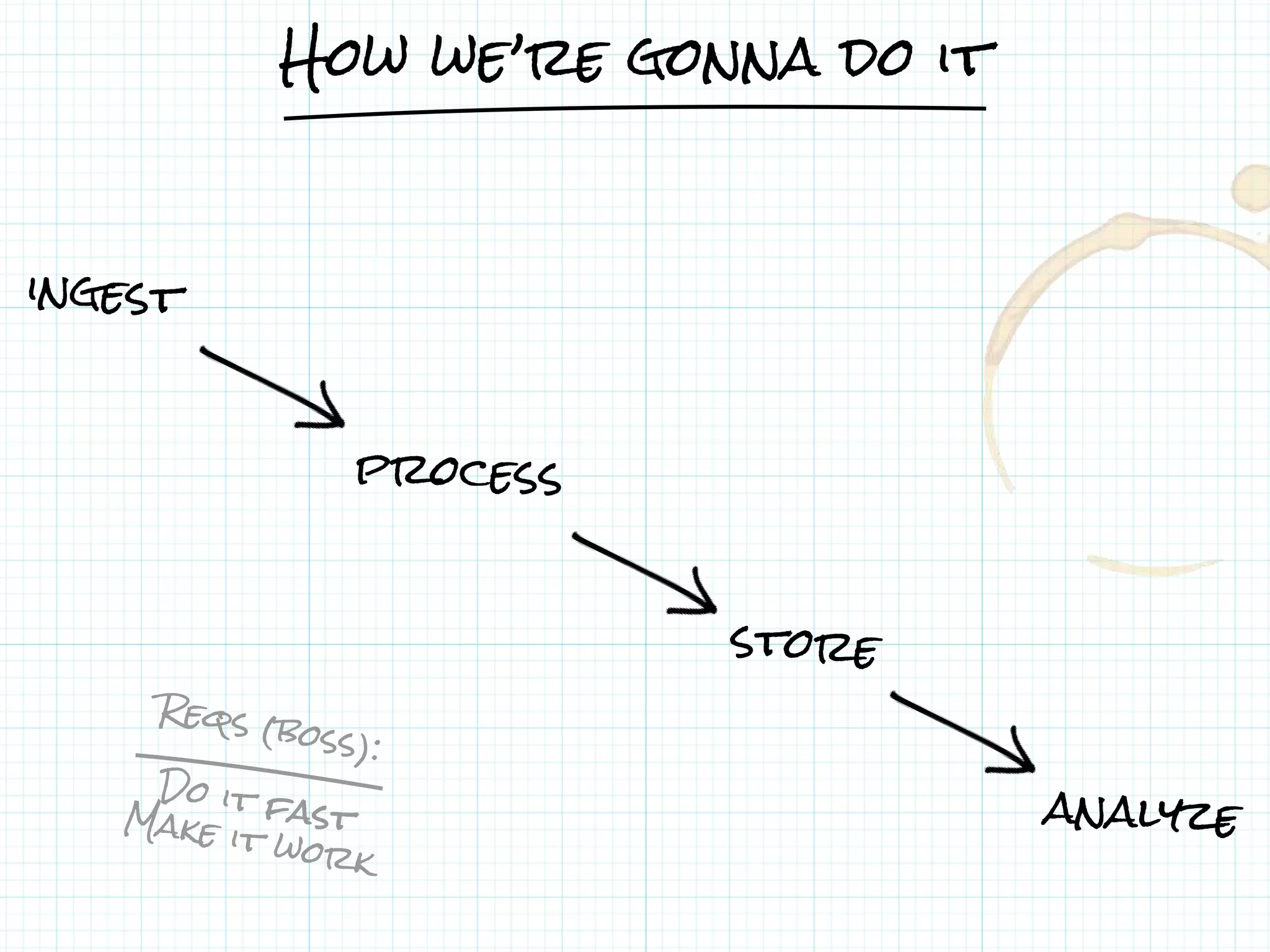
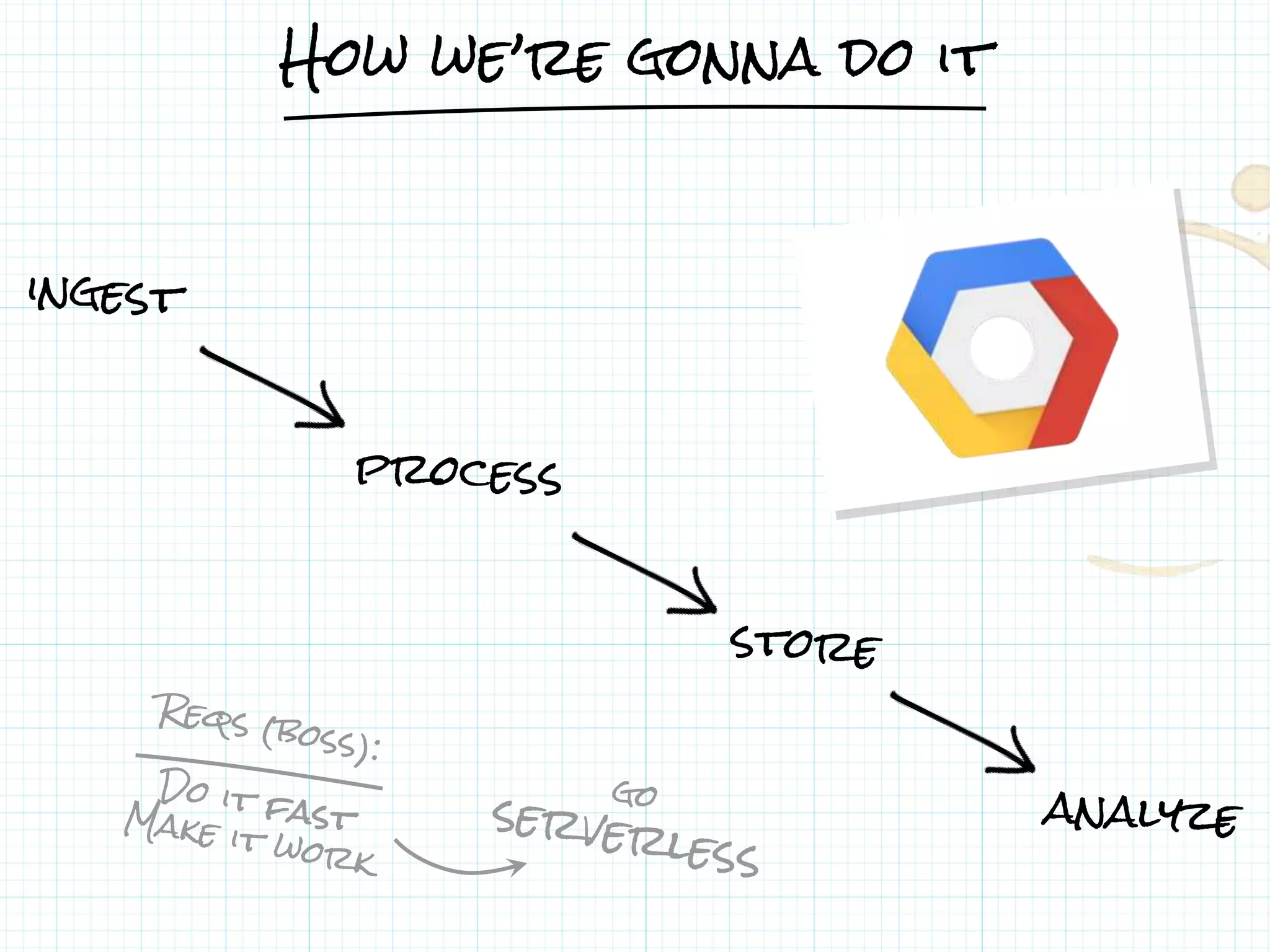
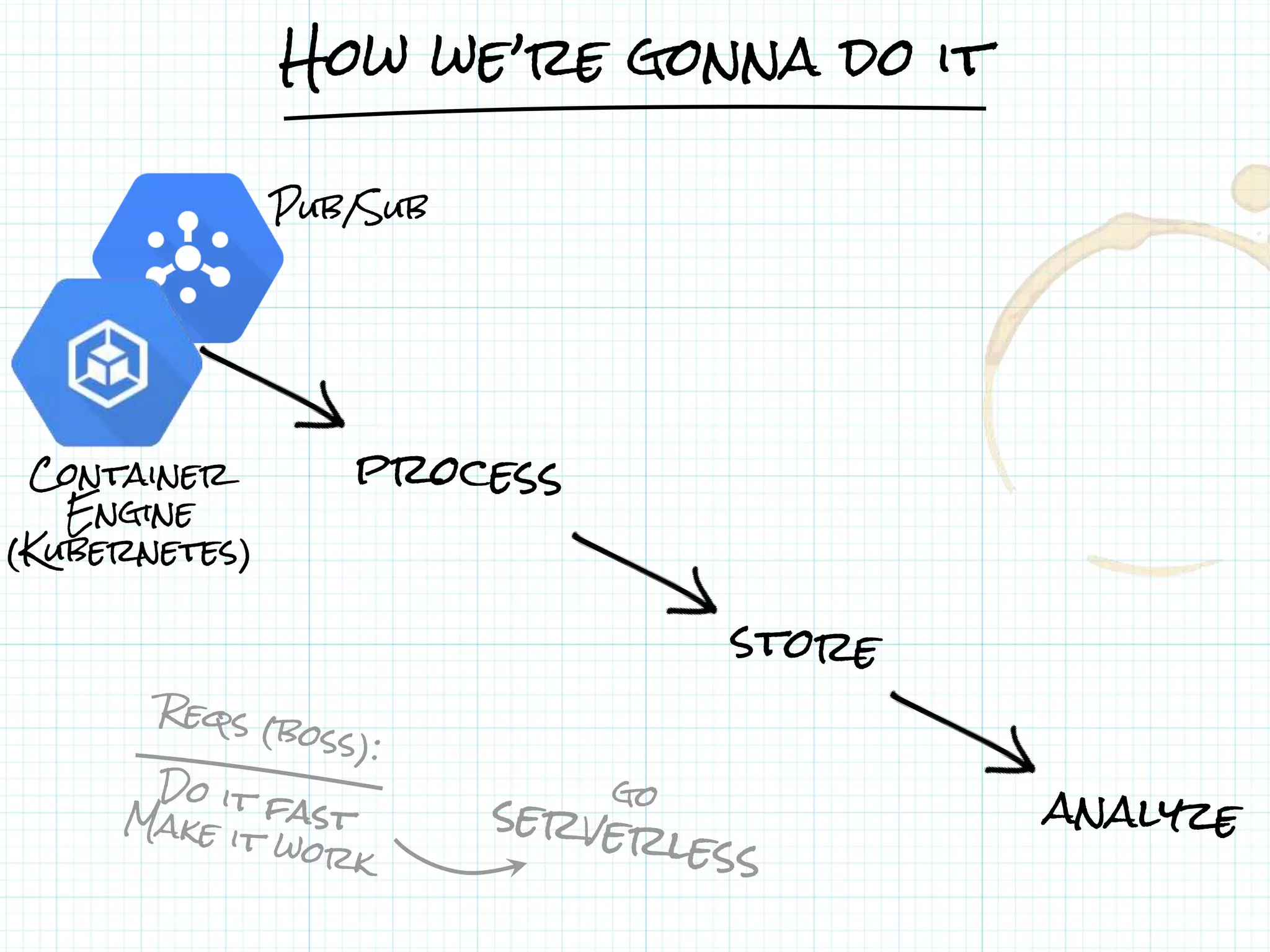
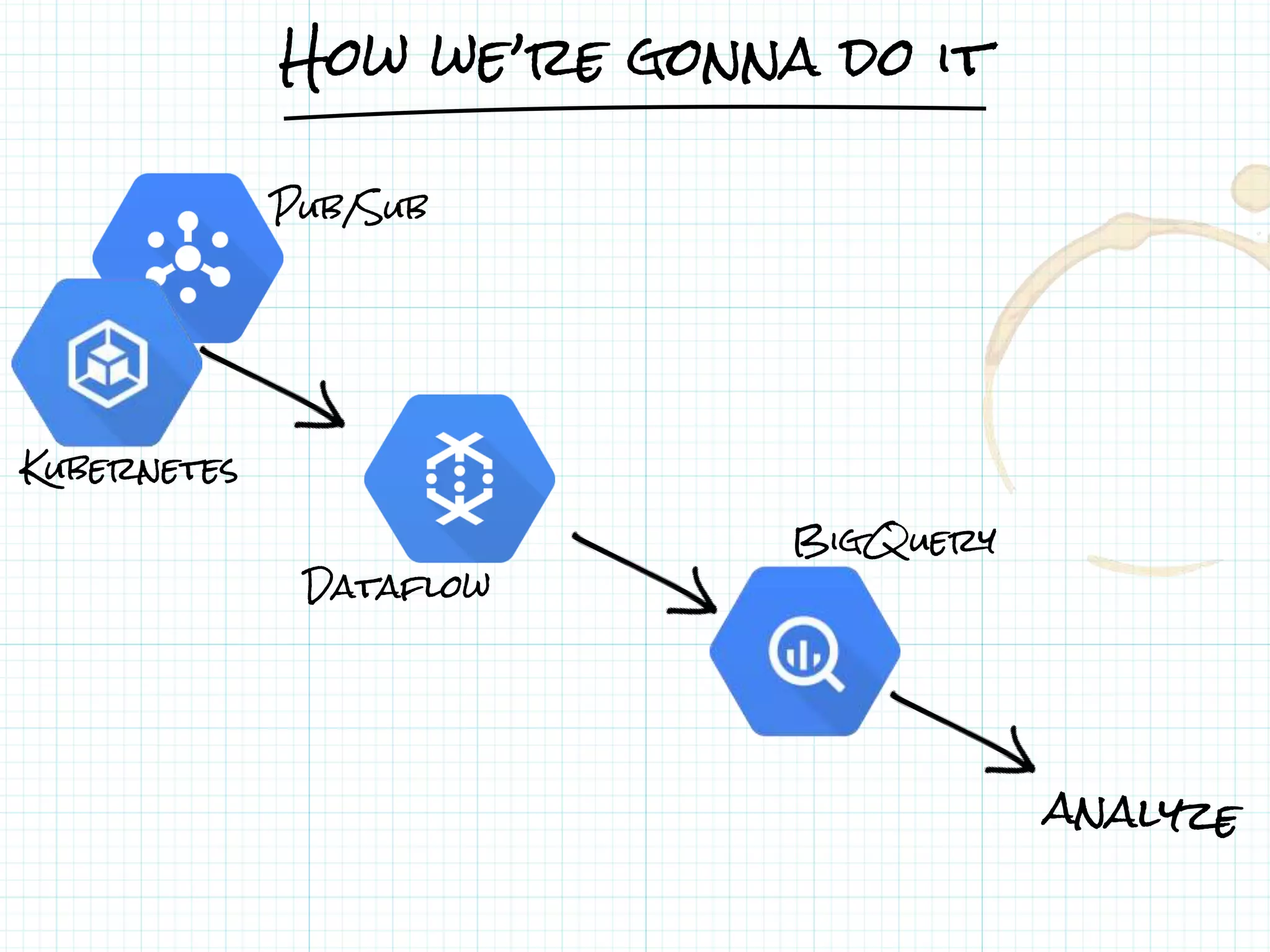
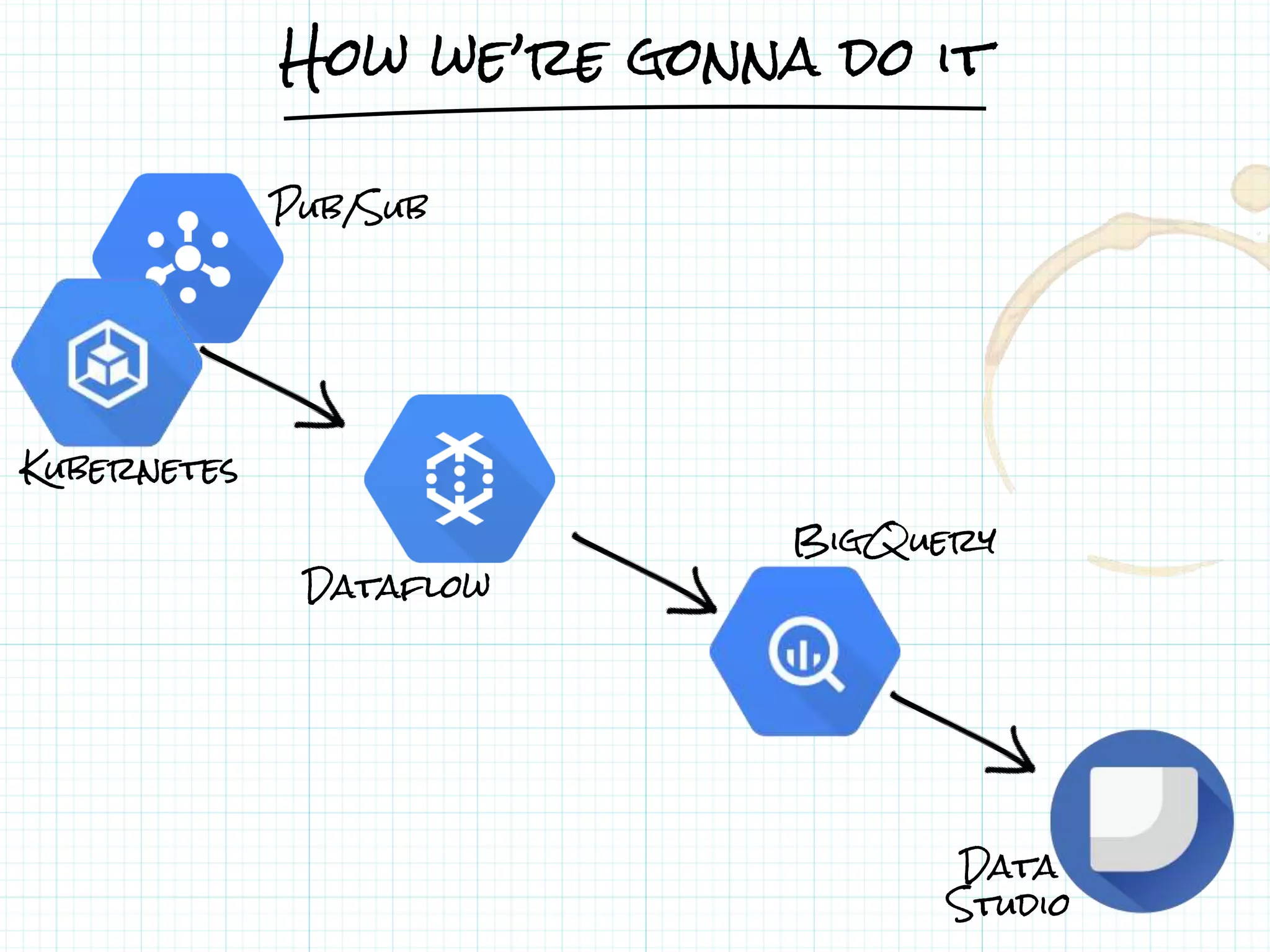
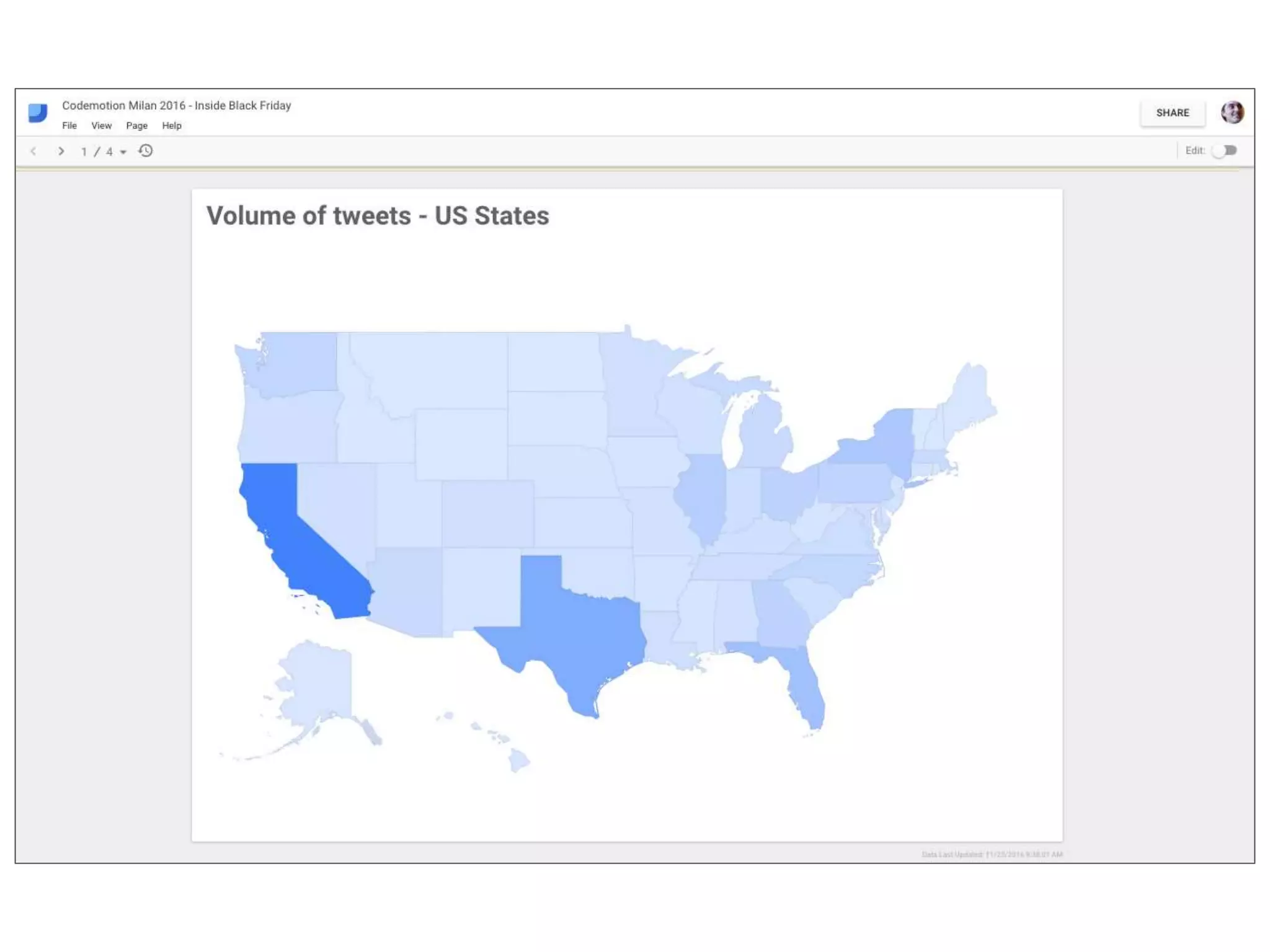
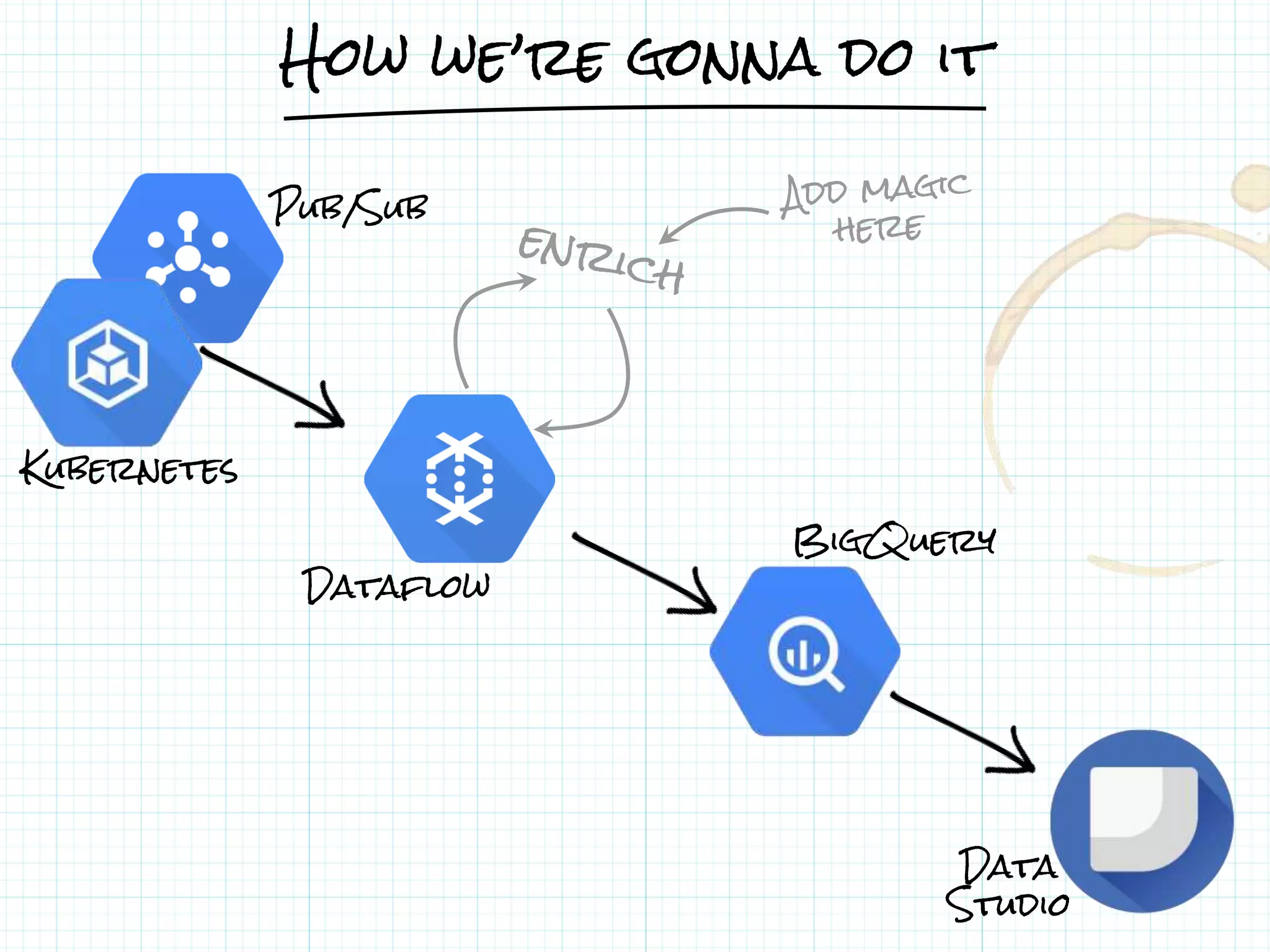
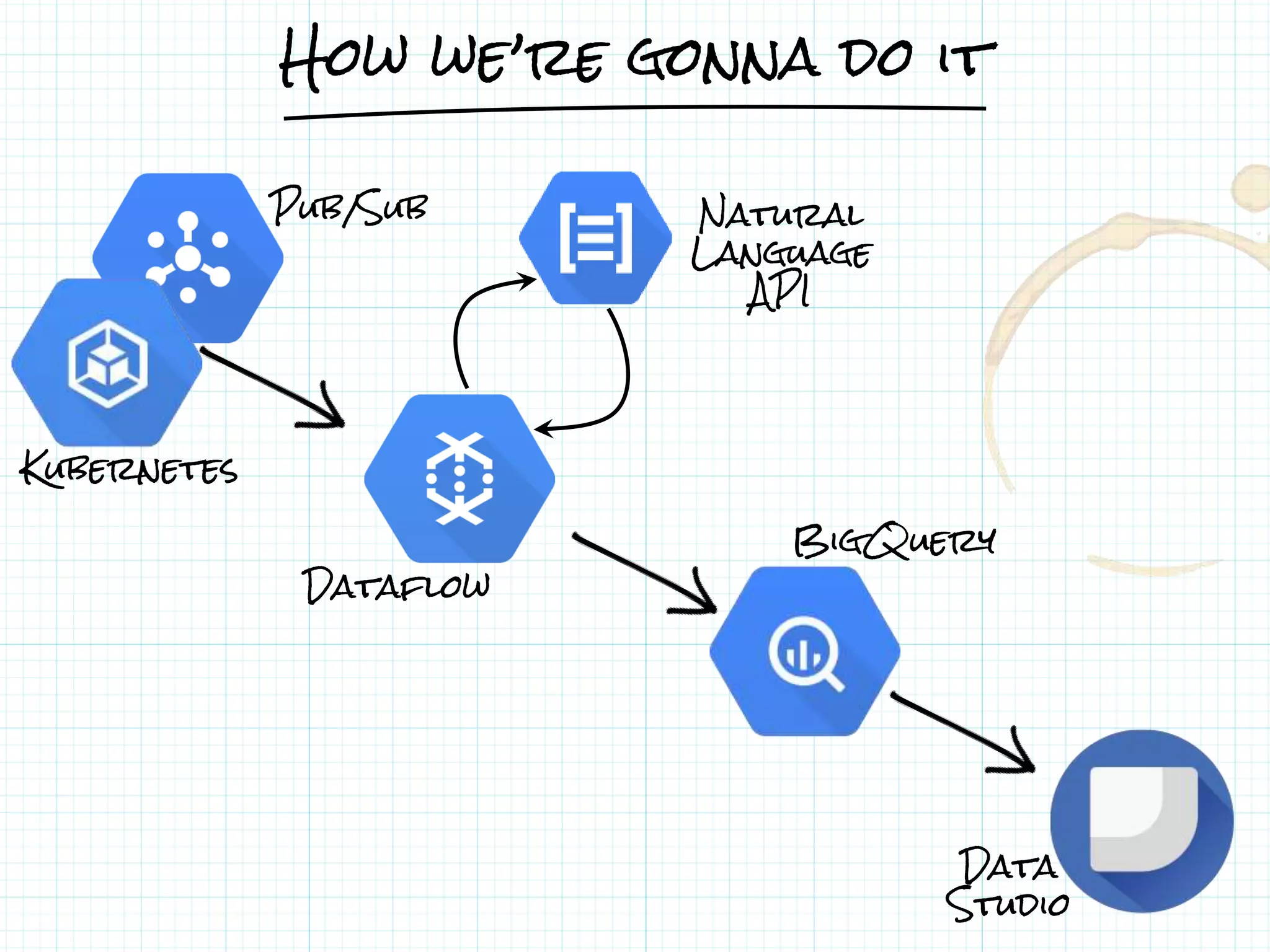
This document describes a serverless data architecture for processing tweets about Black Friday and performing sentiment analysis using Google Cloud Platform services. It involves collecting tweets from Twitter using Pub/Sub, running containers on Kubernetes, processing the data with Dataflow pipelines that write to BigQuery tables, and using the Natural Language API for sentiment analysis. The full pipeline is demonstrated in a live demo.




![[Giovanni Galloro] How to use machine learning on Google Cloud Platform](https://cdn.slidesharecdn.com/ss_thumbnails/mlcapabilitiesongcp-190115085455-thumbnail.jpg?width=640&height=640&fit=bounds)
































































![[Sponsored] C3.ai description](https://cdn.slidesharecdn.com/ss_thumbnails/c3deckmeetupnovember252019v2-191128092146-thumbnail.jpg?width=640&height=640&fit=bounds)





































