Downloaded 41 times









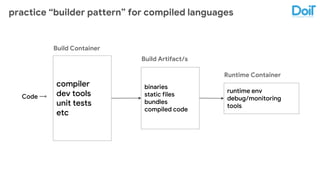

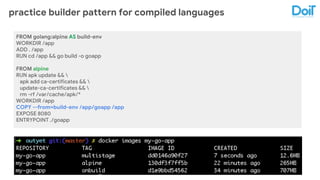

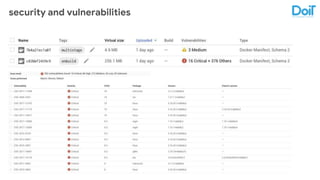





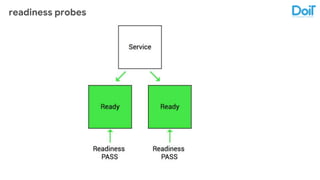
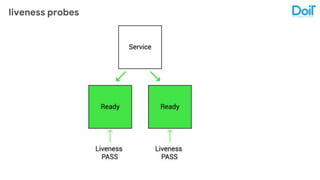




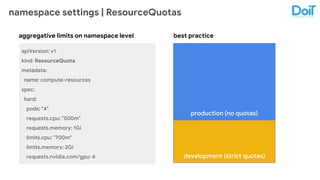

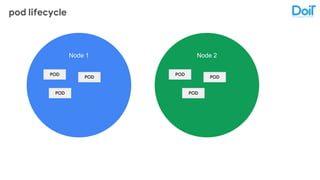
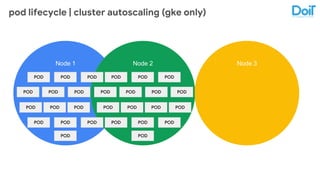


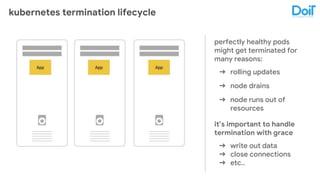
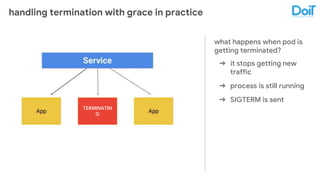
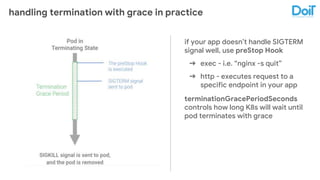




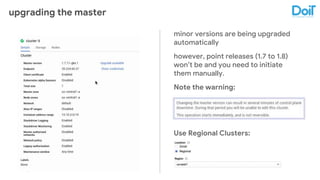
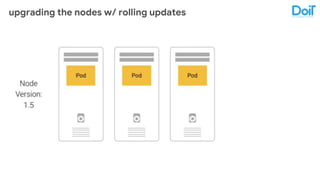



This document outlines best practices for deploying applications using Kubernetes, emphasizing key areas such as container image optimization, namespace organization, health checks, resource requests, and graceful termination. It covers techniques like multistage builds for smaller images, proper use of readiness and liveness probes, and the importance of managing resource limits within namespaces. The document also discusses upgrading Kubernetes clusters with zero downtime and highlights safety measures such as using non-root users within containers.

































































