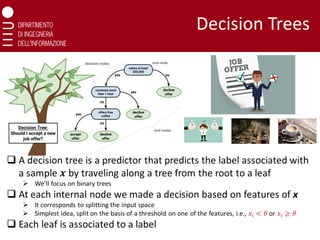
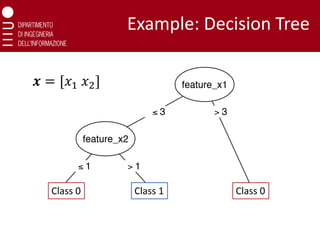
Grow a DecisionTree
Consider a binary classification setting and assume to have a gain
(performances) measure:
Start
❑ A single leaf assigning the most common of the two labels (i.e., the
one of the majority of the samples)
At each iteration
❑ Analyze the effect of splitting a leaf
❑ Among all possible splits select the one leading to a larger gain and
split that leaf (or choose not to split)
5.
• Iterative Dichotomizer3 (ID3)
Find which split (i.e. splitting over which
feature) leads to the maximum gain
Split on xj and recursively call the algorithm
considering the remaining features*
* Split on a feature only once: they are binary
No more
features to use
xj: selected feature
for the split
If real valued features: need to
find threshold, can split on
same feature with different
thresholds
Pruning
❑ Issue ofID3: The tree is typically very large with high risk of overfitting
❑ Prune the tree to reduce its size without affecting too much the performances
9.
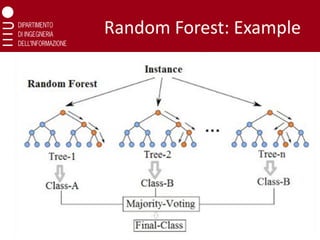
Random Forests (RF)
❑Introduced by Leo Breiman in 2001
❑ Instead of using a single large tree
construct an ensemble of simpler
trees
❑ A Random Forest (RF) is a classifier
consisting of a collection of
decision trees
❑ The prediction is obtained by a
majority voting over the prediction
of the single trees
Random Sampling with
Replacement
Idea:randomly sample from a training dataset with replacement
❑ Assume a training set S of size m: we can build new training sets
by taking at random m samples from S with replacement (i.e., the
same sample can be selected multiple times)
For example, if our training data is [1, 2, 3, 4, 5, 6] then we might sample
sets like [1, 2, 2, 3, 6, 6], [1, 2, 4, 4, 5, 6], [1 1 1 1 1 1], etc…..
i.e., all lists have a length of six but some values can be repeated in the
random selection
❑ Notice that we are not subsetting the training data into smaller
chunks
12.
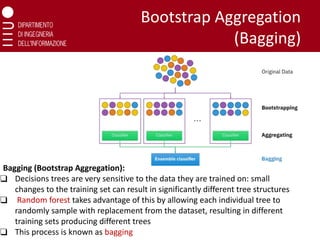
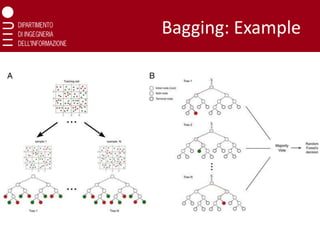
Bootstrap Aggregation
(Bagging)
Bagging (BootstrapAggregation):
❑ Decisions trees are very sensitive to the data they are trained on: small
changes to the training set can result in significantly different tree structures
❑ Random forest takes advantage of this by allowing each individual tree to
randomly sample with replacement from the dataset, resulting in different
training sets producing different trees
❑ This process is known as bagging
Randomization:
Feature Randomnsess
❑ Ina normal decision tree, when it is time to split a node, we consider every
possible feature and pick the one that produces the largest gain
❑ In contrast, each tree in a random forest can pick only from a random subset of
features ( Feature Randomness )
❑ I.e., node splitting in a random forest model is based on a random subset of
features for each tree.
❑ This forces even more variation amongst the trees in the model and ultimately
results in lower correlation across trees and more diversification








![Random Sampling with
Replacement
Idea: randomly sample from a training dataset with replacement
❑ Assume a training set S of size m: we can build new training sets
by taking at random m samples from S with replacement (i.e., the
same sample can be selected multiple times)
For example, if our training data is [1, 2, 3, 4, 5, 6] then we might sample
sets like [1, 2, 2, 3, 6, 6], [1, 2, 4, 4, 5, 6], [1 1 1 1 1 1], etc…..
i.e., all lists have a length of six but some values can be repeated in the
random selection
❑ Notice that we are not subsetting the training data into smaller
chunks](https://image.slidesharecdn.com/12randomforests-250416020059-03e6f20f/85/Random-Forests-for-Machine-Learning-ML-Decision-Tree-11-320.jpg)