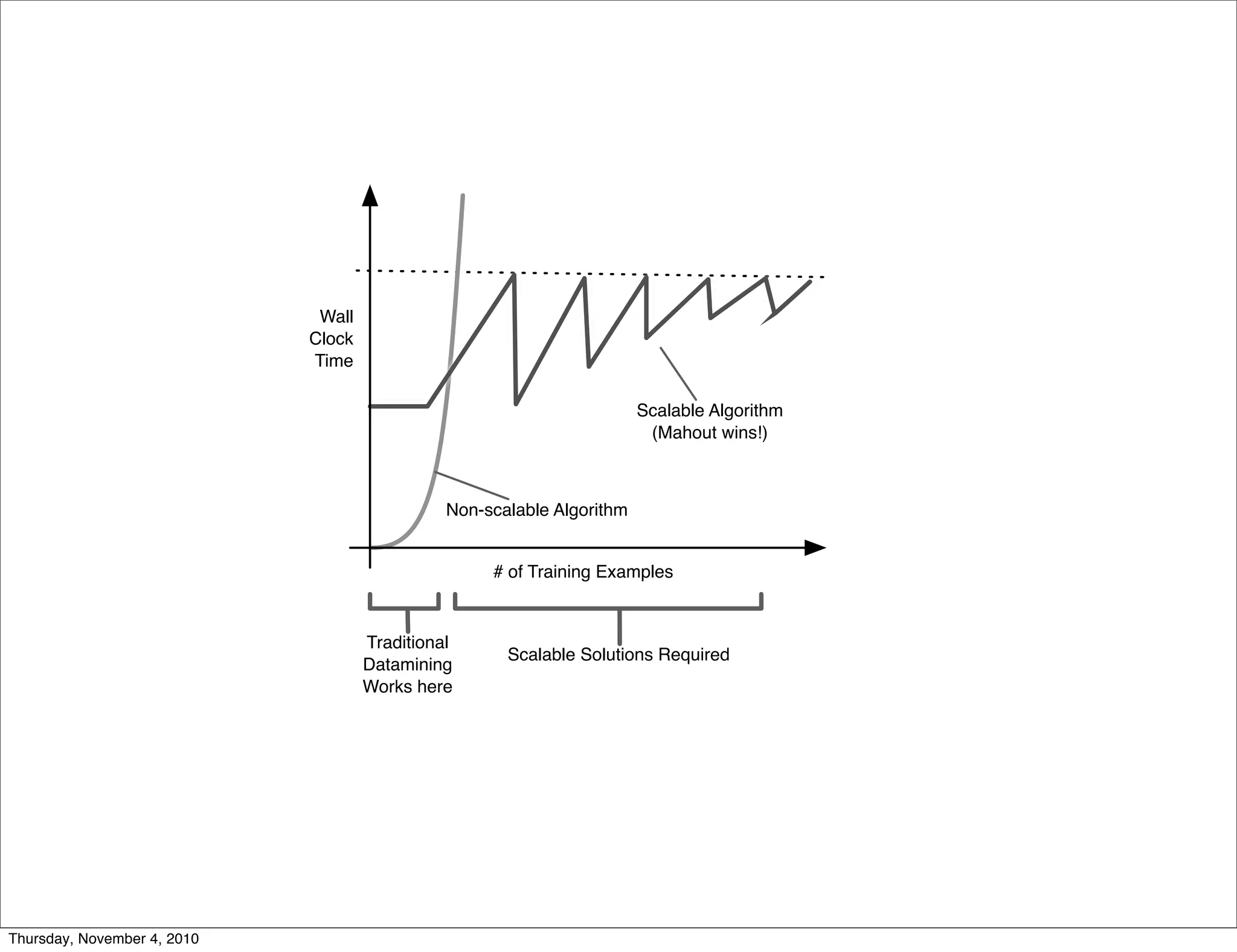
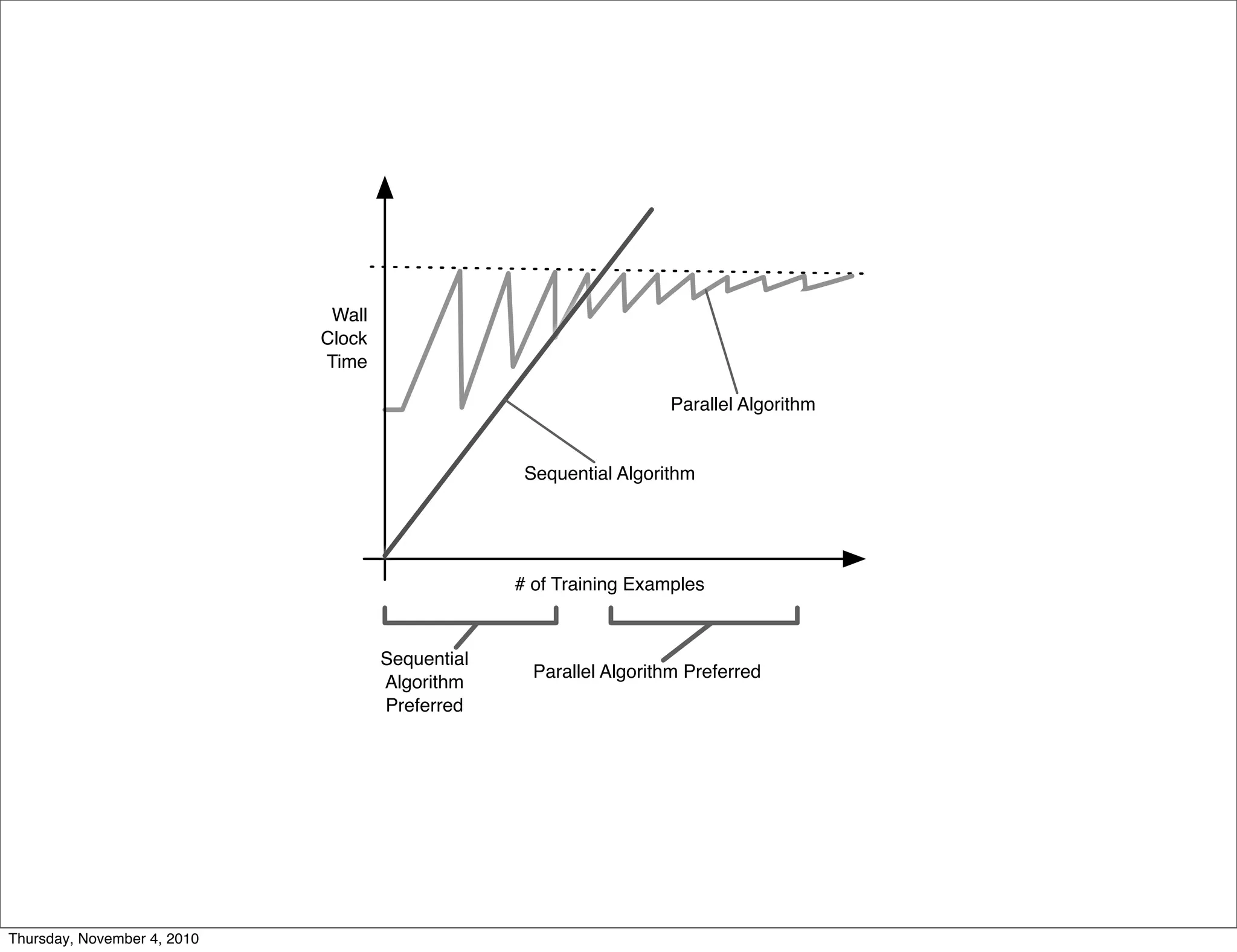
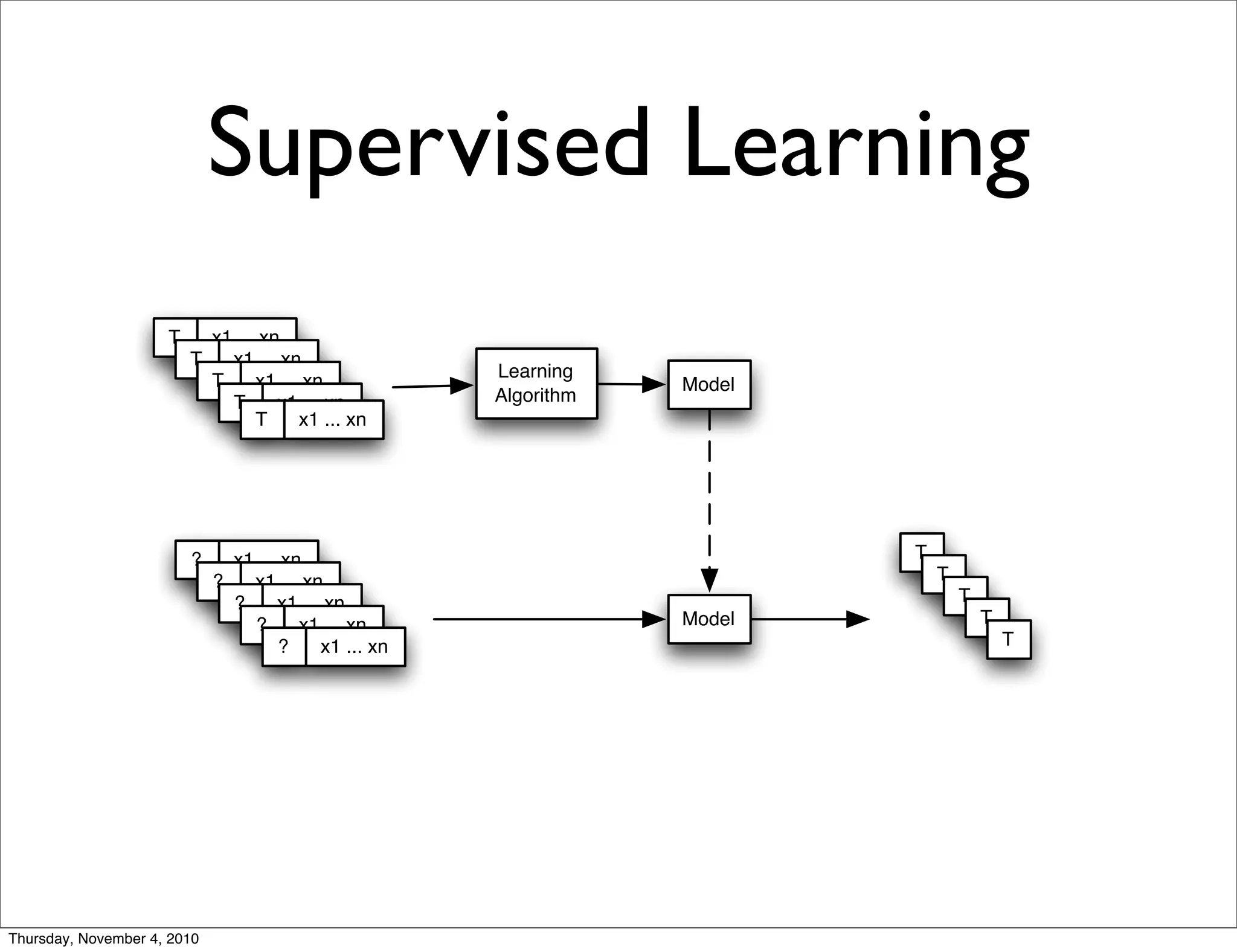
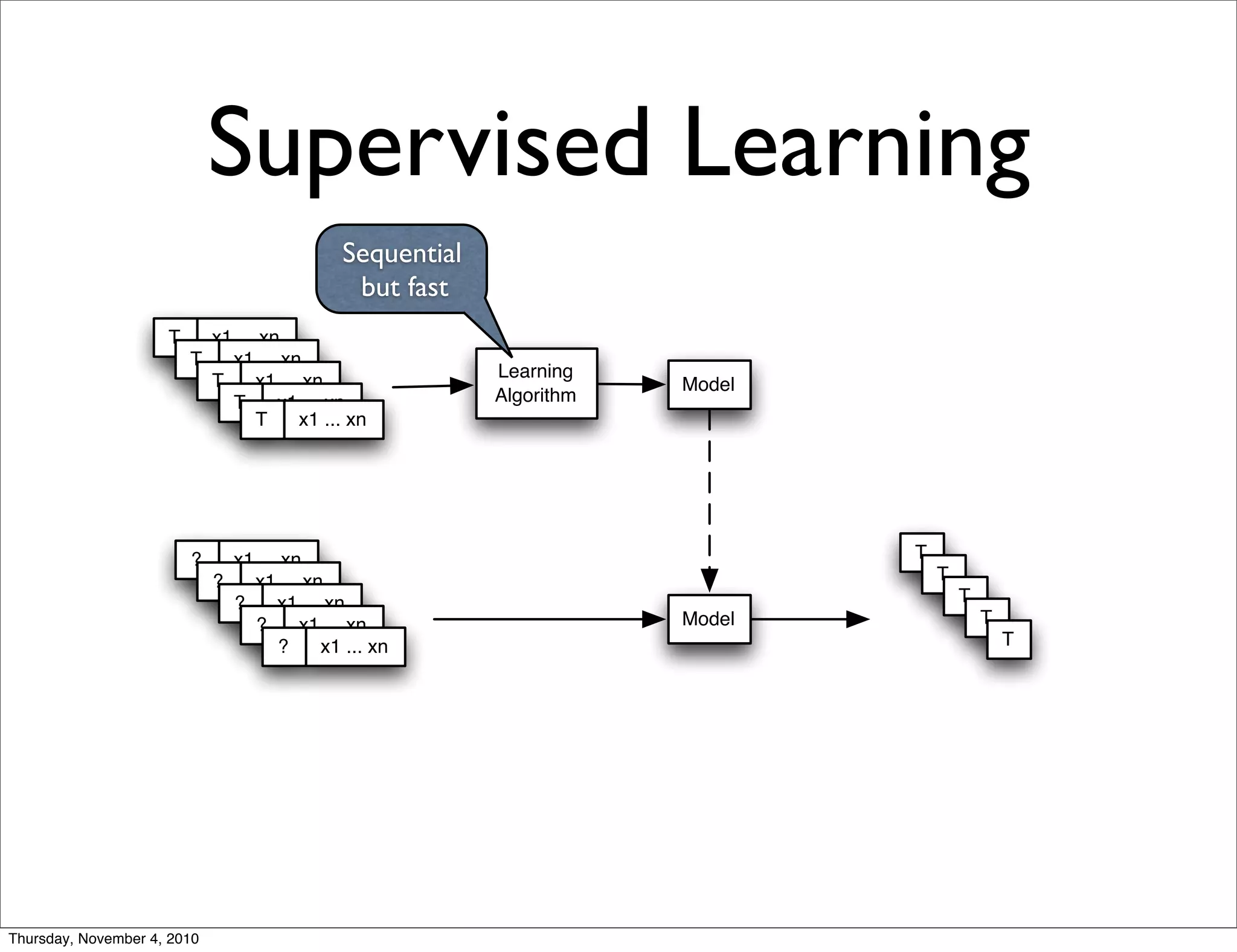
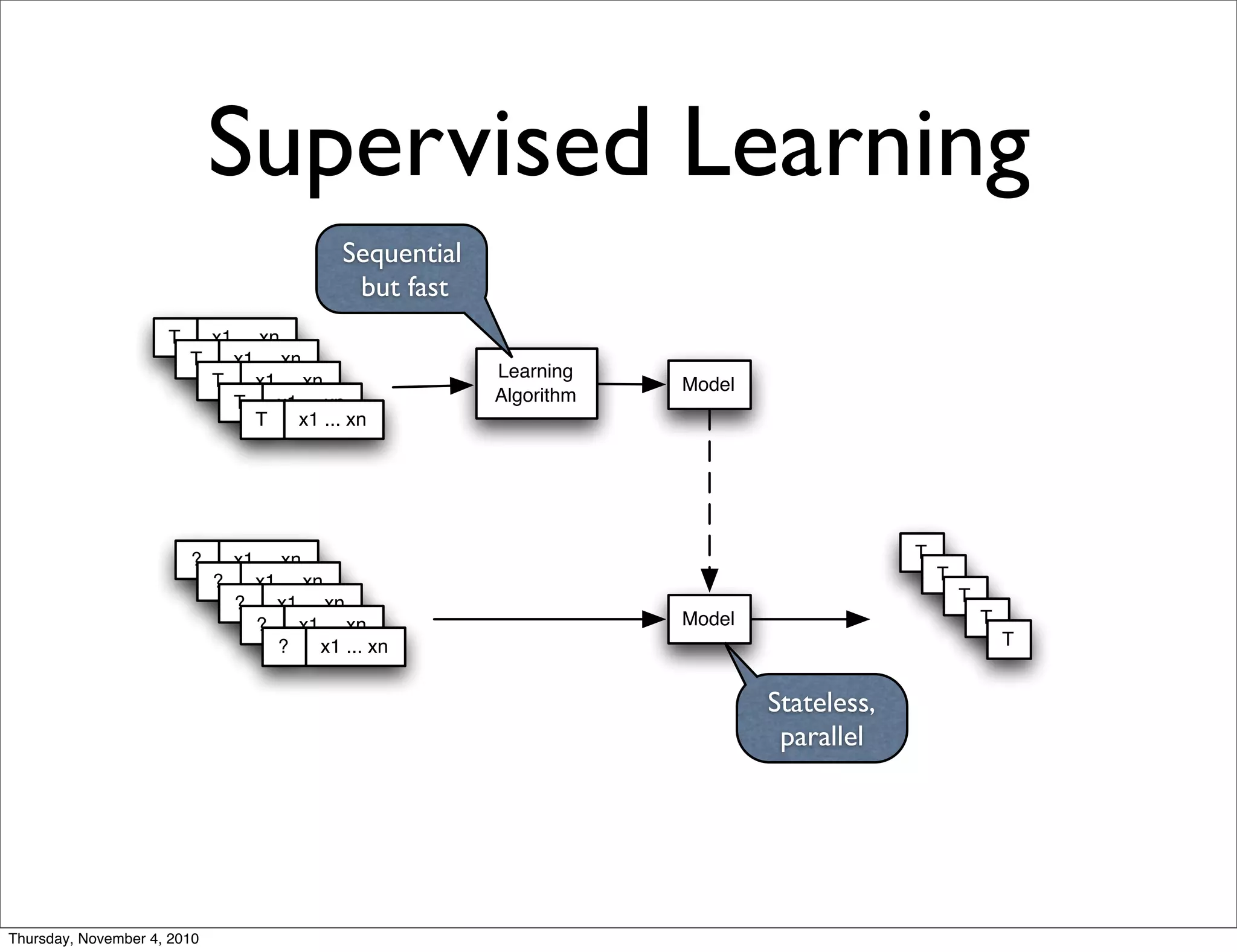
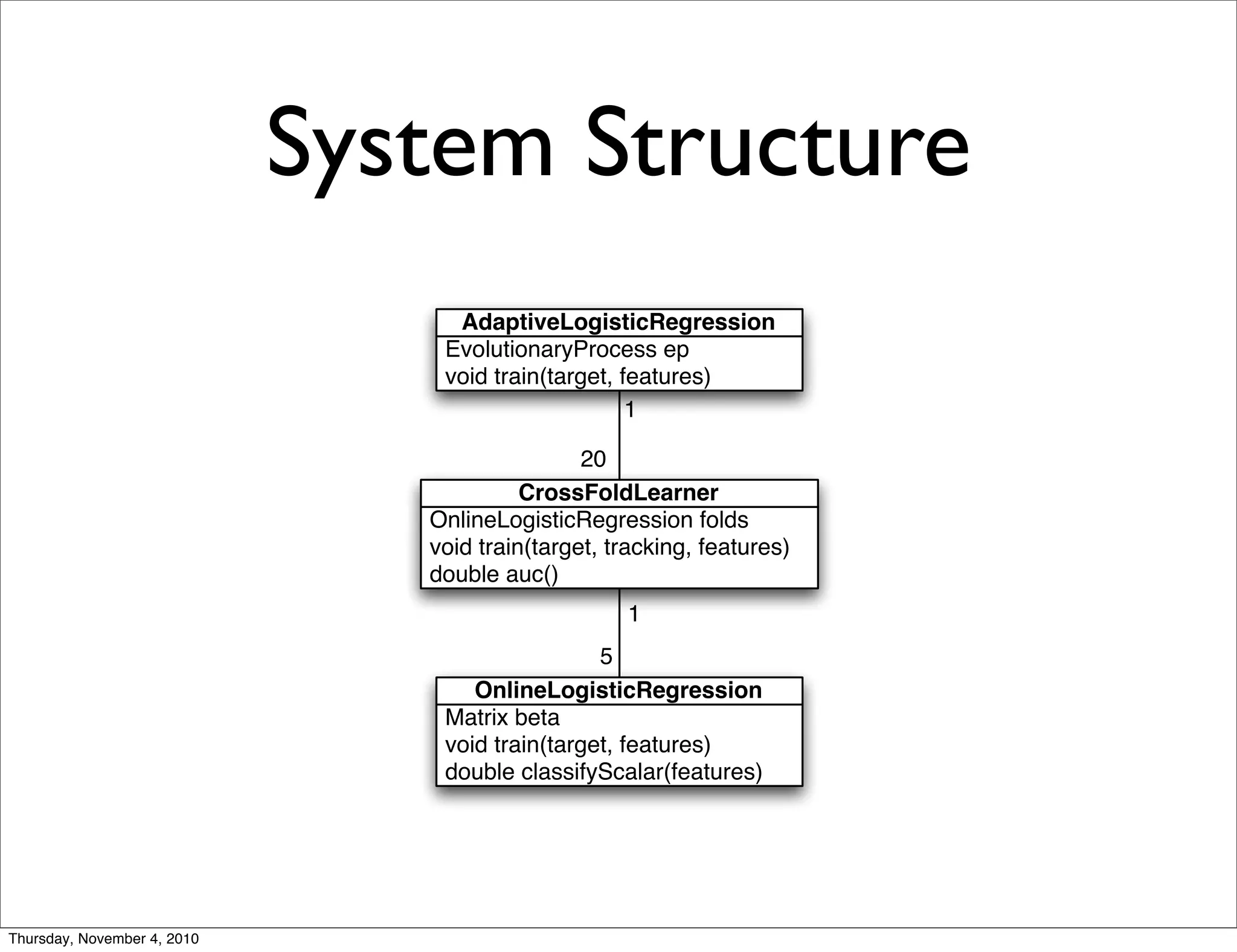
Apache Mahout is a scalable machine learning library. It provides recommendations, clustering, and supervised learning algorithms. A new stochastic gradient descent classifier allows for highly scalable classification with sparse, high-dimensional data. The document outlines Mahout's scalable algorithms and speed improvements through optimizations like evolutionary parameter tuning and multithreading.
















![Speed?
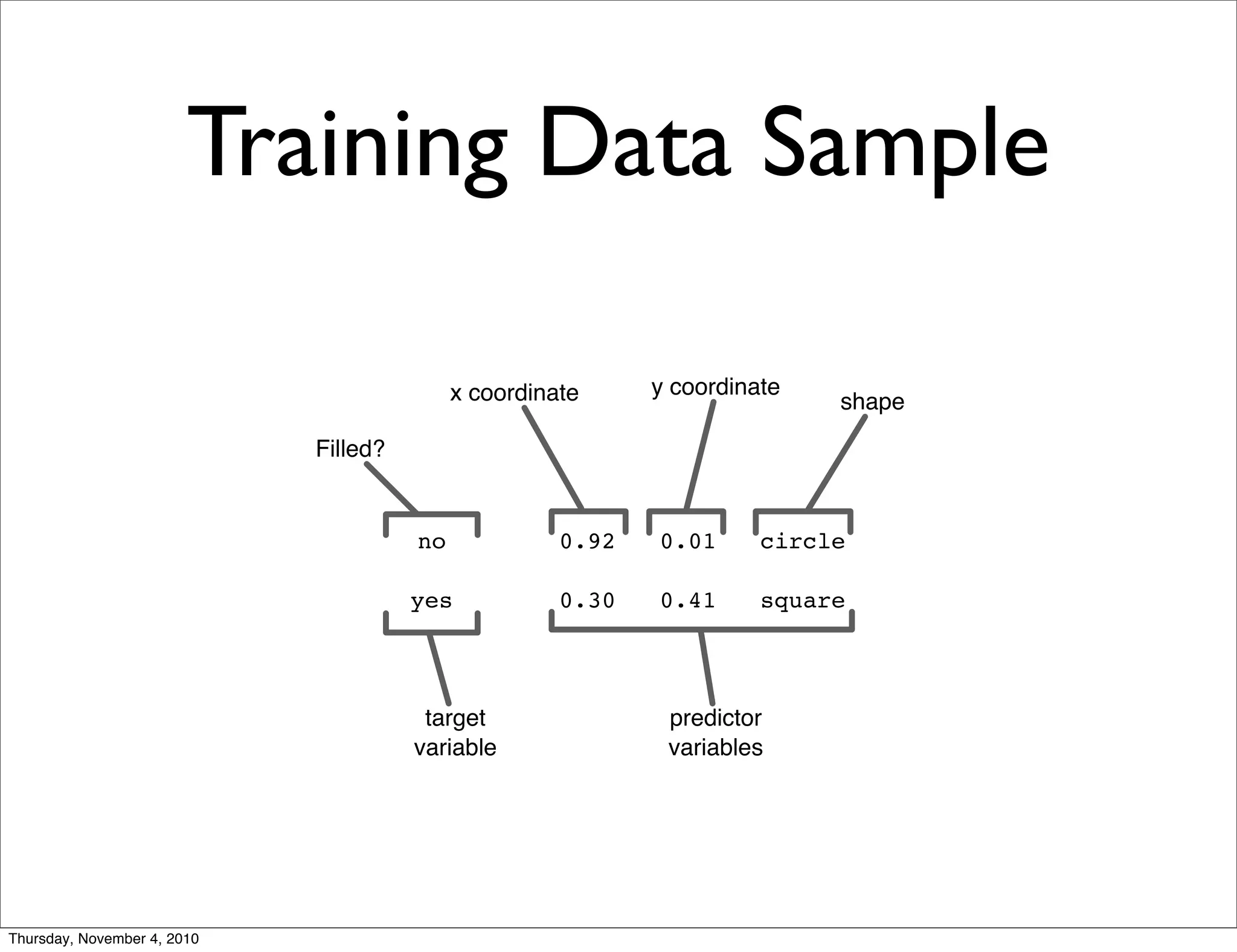
• Encoding API for hashed feature vectors
• String, byte[] or double interfaces
• String allows simple parsing
• byte[] and double allows speed
• Abstract interactions supported
Thursday, November 4, 2010](https://image.slidesharecdn.com/sdforum-11-04-2010-101104215537-phpapp02/75/Sdforum-11-04-2010-25-2048.jpg)
































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







