
Downloaded 16 times





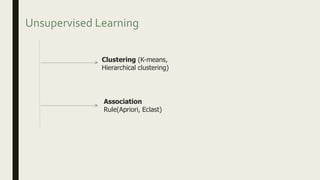

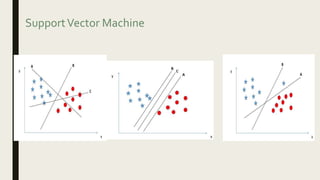
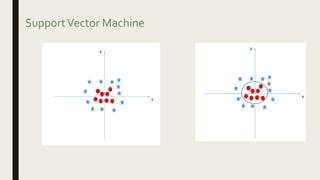





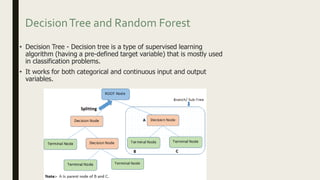






















































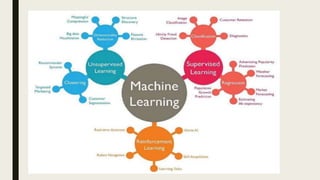















This document provides an overview of major data mining algorithms, including supervised learning techniques like decision trees, random forests, support vector machines, naive Bayes, and logistic regression. Unsupervised techniques discussed include clustering algorithms like k-means and EM, as well as association rule learning using the Apriori algorithm. Application areas and advantages/disadvantages of each technique are described. Libraries for implementing these algorithms in Python and R are also listed.







































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)















