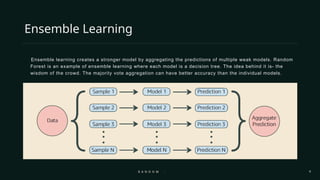
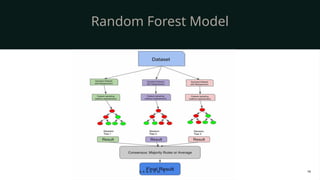
Random Forest is one of the most powerful and widely used machine learning algorithms in both academia and industry. As the name suggests, it is literally a “forest” made up of many individual “decision trees.” Just like a forest is stronger and more resilient than a single tree, Random Forest leverages the combined strength of multiple decision trees to create a model that is more accurate, robust, and resistant to overfitting.
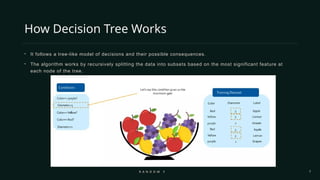
To understand Random Forest, we should first recall how a decision tree works. A decision tree is a flowchart-like structure where data is split into branches based on certain conditions. It is easy to interpret, but the major drawback is that a single tree often becomes too specific to the training data, leading to overfitting and poor performance on unseen data. Random Forest solves this problem by building many trees and combining their outputs, making the overall model generalize much better.
The “randomness” in Random Forest comes from two main ideas:
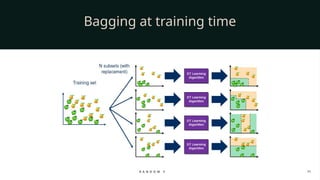
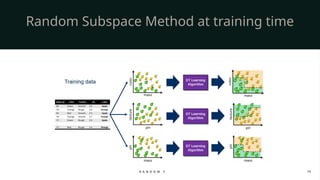
Random Sampling of Data (Bagging): Each tree is trained on a random subset of the dataset. This is done using bootstrapping, where we sample data with replacement. As a result, every tree sees a slightly different version of the dataset.
Random Selection of Features: When splitting a node, instead of considering all features, Random Forest chooses a random subset of features. This ensures that not all trees look alike and promotes diversity in the forest.
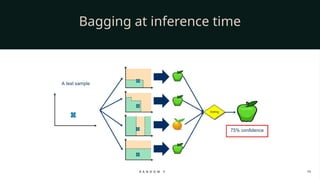
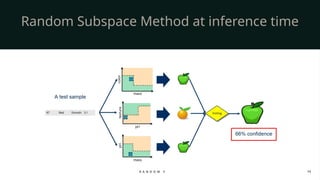
When it comes to making predictions, Random Forest works through majority voting in classification tasks and averaging in regression tasks. For example, if we are classifying whether an email is spam or not, each tree gives its vote, and the final decision is based on the majority. If we are predicting house prices, each tree outputs a predicted value, and the Random Forest takes the average.
The advantages of Random Forest are numerous. It handles large datasets with higher dimensionality very effectively, works well with both categorical and numerical features, and is robust against noise and missing values. Unlike linear models, it does not assume any specific distribution of data and can capture non-linear relationships very naturally.
In real-world scenarios, Random Forest is used in a wide range of applications. In finance, it helps in credit scoring and fraud detection. In healthcare, it is used for disease prediction and medical image classification. In e-commerce, it powers recommendation systems and customer segmentation. Because of its flexibility, Random Forest is often the first algorithm data scientists try when faced with a new problem.
However, Random Forest is not without limitations. It requires more computational power and memory compared to a single decision tree. The model can also become less interpretable as the number of trees increases, since it is harder to explain hundreds of trees compared to one. Still, techniques like feature importance ranking allow us to gain insights into which
























































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)


![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)









