Downloaded 202 times

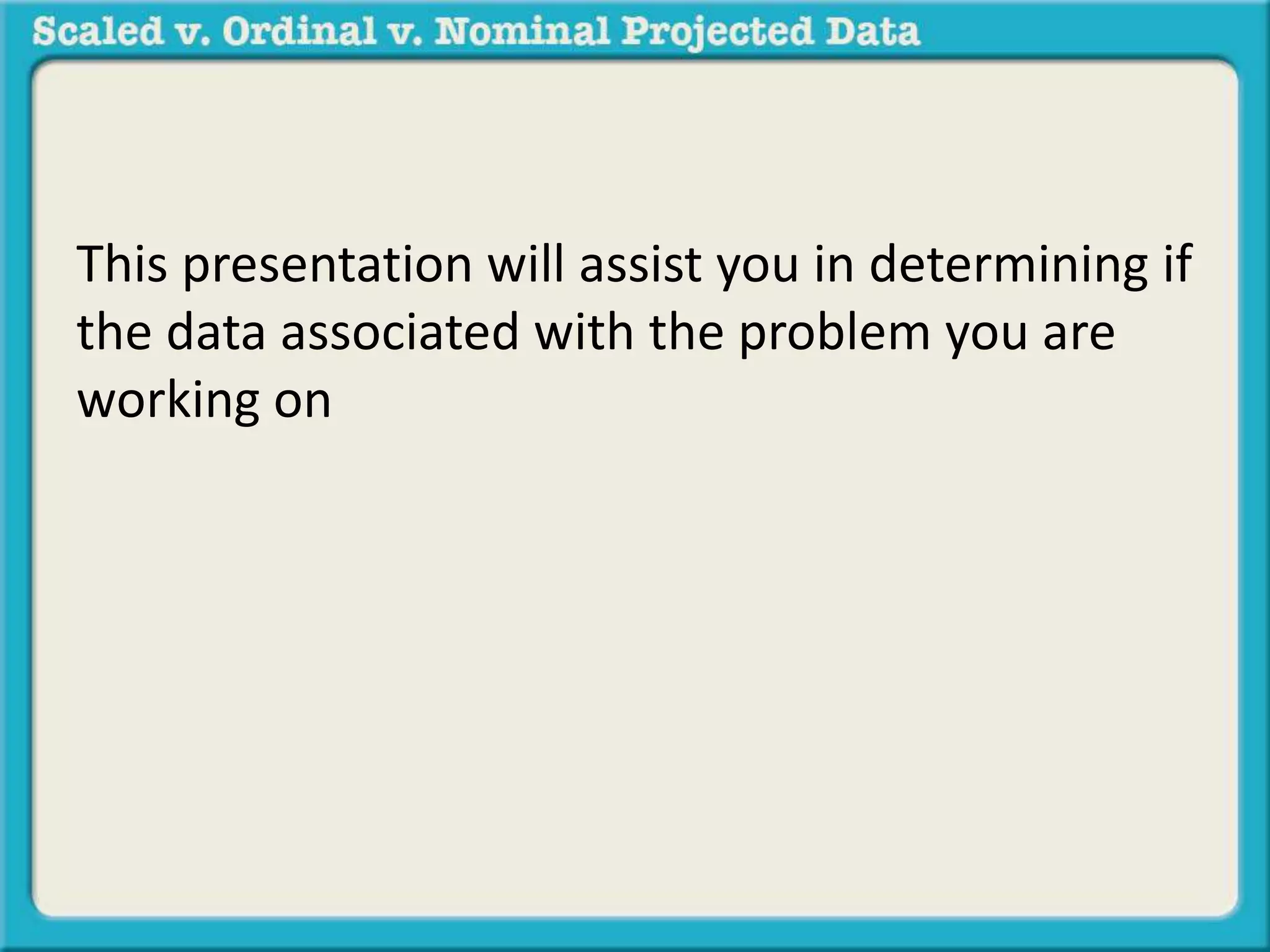






















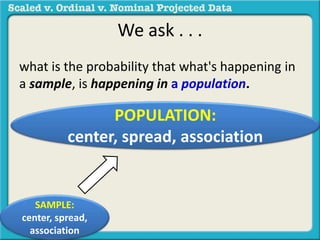















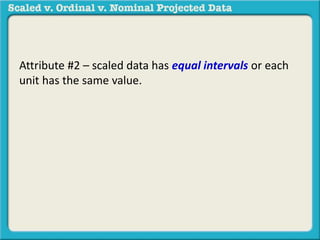



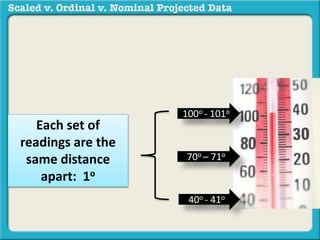




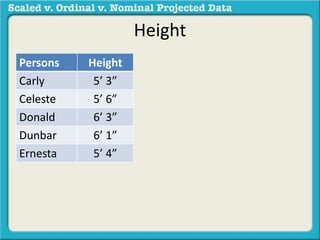



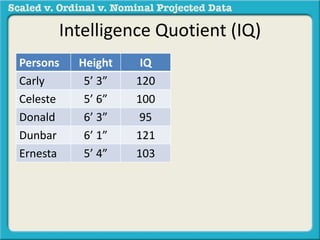
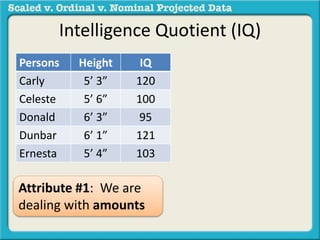
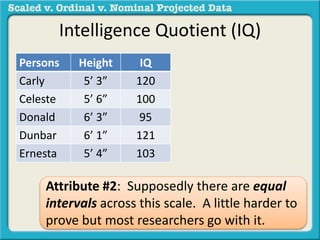

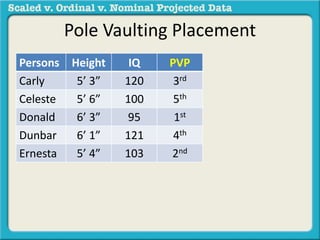

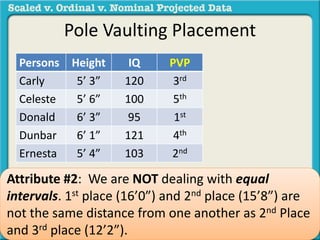
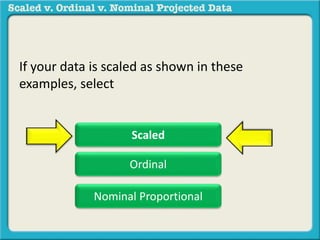








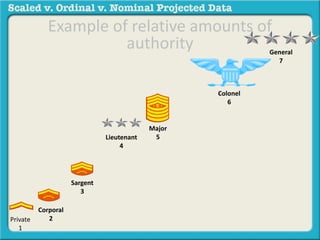
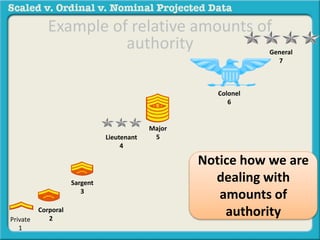
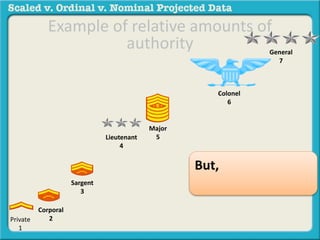
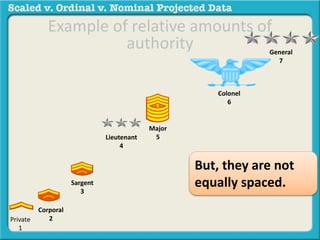
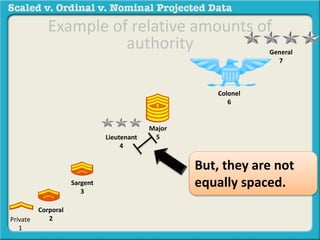
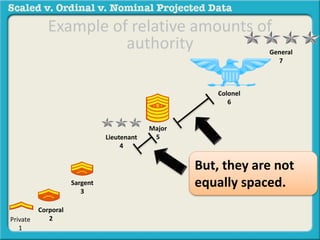


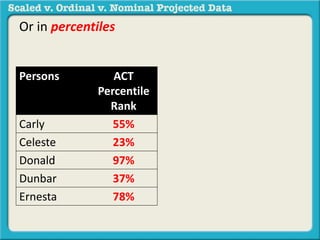























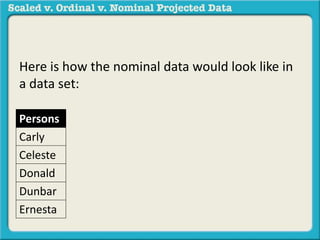
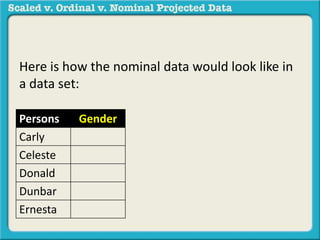
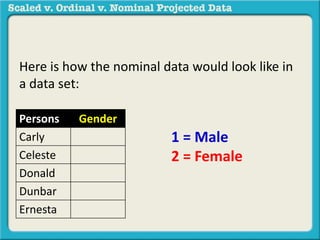

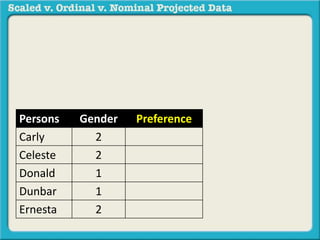

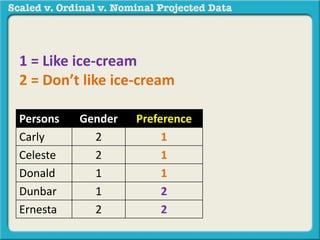
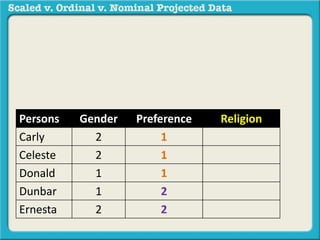
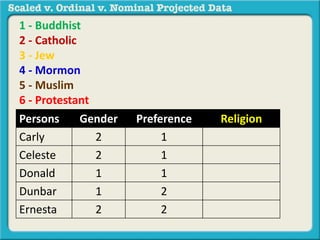
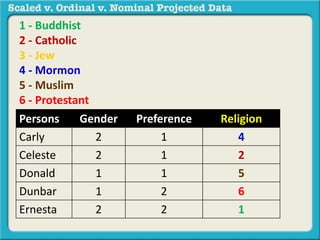





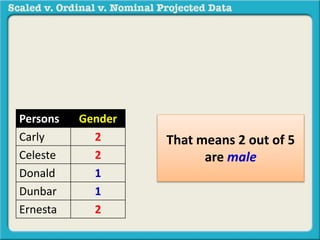
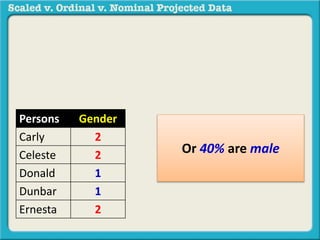




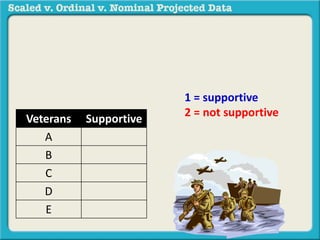






The document discusses different types of data used in statistical analysis: scaled, ordinal, and nominal data. Scaled data represents quantities where the intervals between values are equal, such as temperature or test scores. Ordinal data uses numbers to represent relative rankings, like placing in an event, but the intervals are not equal. The document uses examples to illustrate the properties of scaled and ordinal data and explains how to determine if a given data set is scaled or ordinal.










































































































