Downloaded 46 times








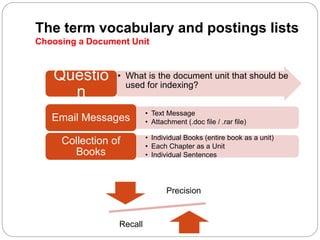








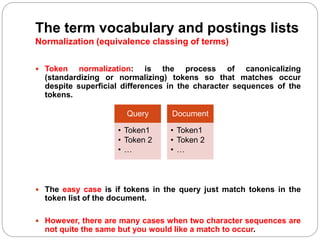








The document discusses processing Boolean queries in an information retrieval system using an inverted index. It describes the steps to process a simple conjunctive query by locating terms in the dictionary, retrieving their postings lists, and intersecting the lists. More complex queries involving OR and NOT operators are also processed in a similar way. The document also discusses optimizing query processing by considering the order of accessing postings lists.






























































































