Download to read offline





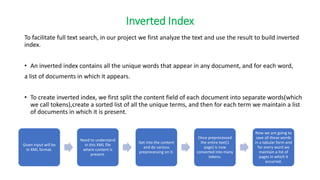













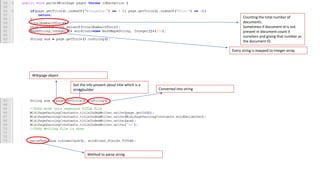
![Content Handler Interface
• void startDocument():- Called at the beginning of a document.
• void endDocument():- Called at the end of a document.
• void startElement(string uri, string localName, string qName, string Attributes atts):- Called at the beginning of
an element.
• void endElement(string uri, string localName, string qName):- Called at the end of an element.
• void characters(char[] ch, int start, int length):- Called when character data is encountered.](https://image.slidesharecdn.com/seminarpresentation6920-240426122701-904a5e3b/85/Text-based-search-engine-on-a-fixed-corpus-and-utilizing-indexation-and-ranking-algorithms-21-320.jpg)




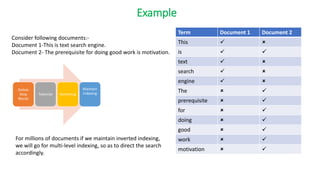
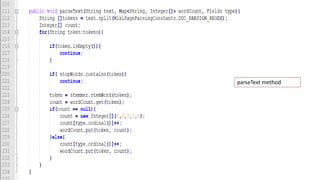
![High Level Design
Module 2:-
Consider a wikipage
• Step 1- Split the text into tokens
• Step 2-Remove stop words
• Step 3- Stem the word
• Step 4- Maintain count where each word occurred(Maintain Hashmap)
Key Value
Particular
word
Integer[]
{0,0,0,0,0}
Title
Infobox
External
Links
Category
Text](https://image.slidesharecdn.com/seminarpresentation6920-240426122701-904a5e3b/85/Text-based-search-engine-on-a-fixed-corpus-and-utilizing-indexation-and-ranking-algorithms-27-320.jpg)
















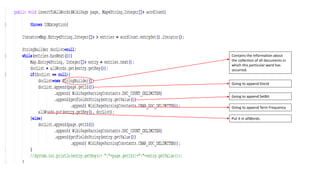

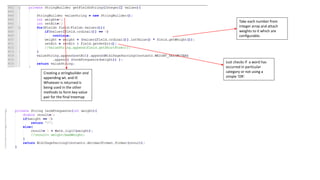

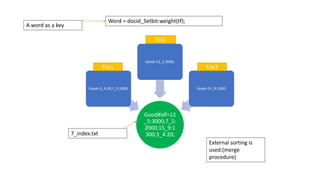


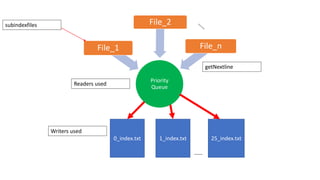




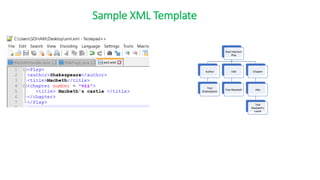
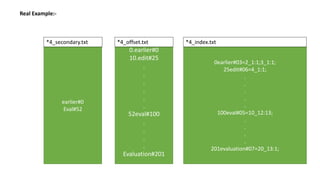
![Creating indexes to inverted indexes:-
Word1#lineStart
Word20#lineStart
Word#lineStart
Word#idf=[doc_id
List]
*_secondary.txt *_offset.txt *_index.txt](https://image.slidesharecdn.com/seminarpresentation6920-240426122701-904a5e3b/85/Text-based-search-engine-on-a-fixed-corpus-and-utilizing-indexation-and-ranking-algorithms-69-320.jpg)


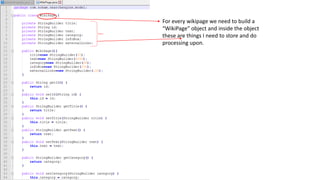
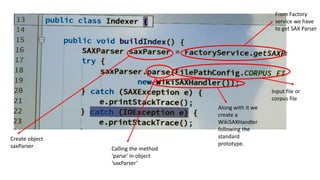
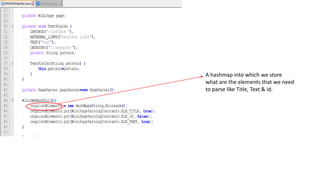
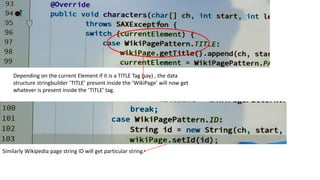
This document outlines the design and implementation of a search engine prototype that processes millions of Wikipedia XML pages to retrieve the top 10 relevant documents for user queries. It covers the construction of an inverted index and the necessary text preprocessing steps such as tokenization, stop word removal, and stemming. Additionally, it details both DOM and SAX parsers for reading XML, emphasizing the efficient handling of large datasets.
































































