Download to read offline



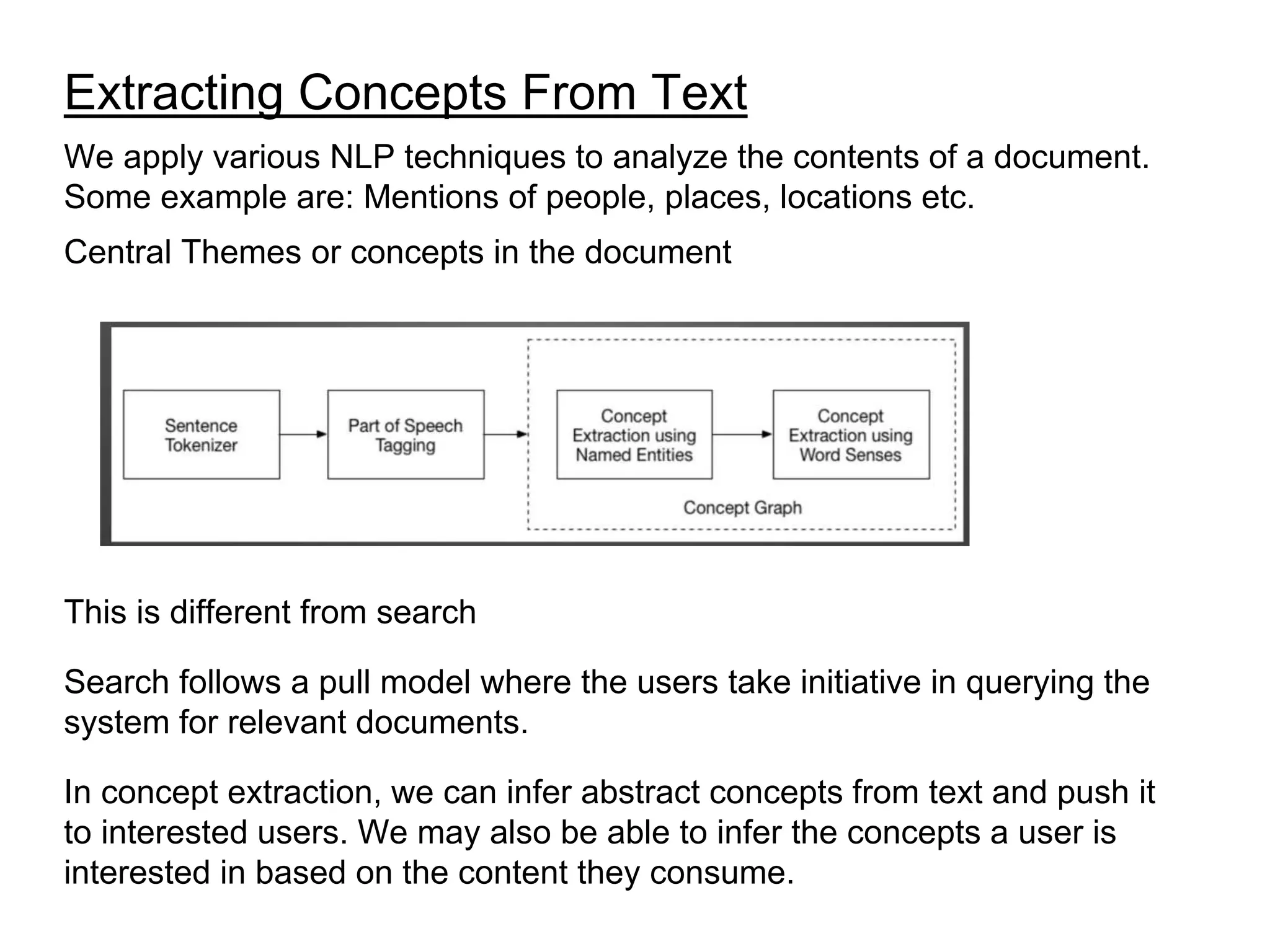



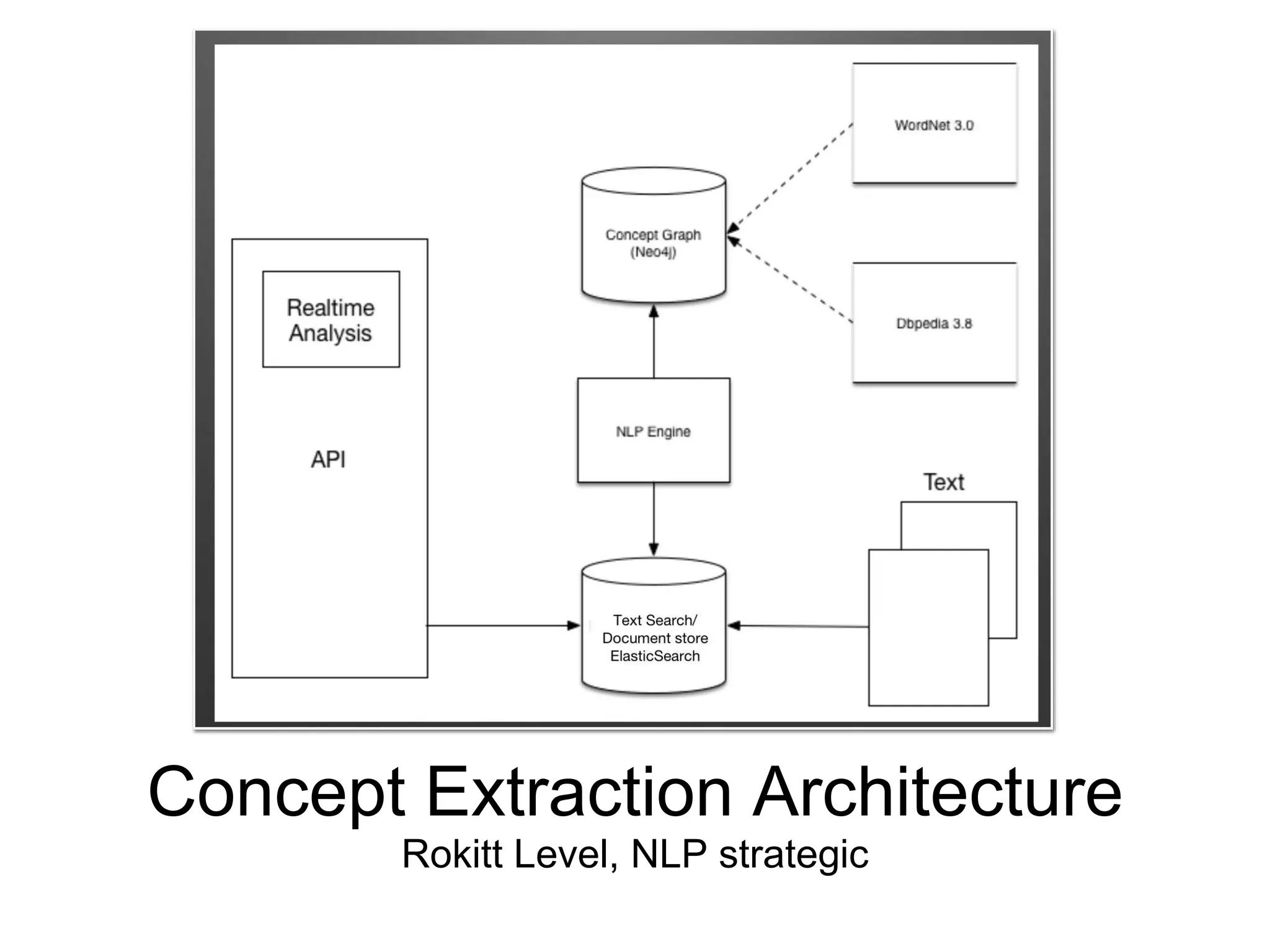



The document discusses various natural language processing (NLP) techniques including implementing search, document level analysis, sentence level analysis, and concept extraction. It provides details on tokenization, word normalization, stop word removal, stemming, evaluating search results, parsing and part-of-speech tagging, entity extraction, word sense disambiguation, concept extraction, dependency analysis, coreference, question parsing systems, and sentiment analysis. Implementation details and useful tools are mentioned for various techniques.















































