Downloaded 111 times


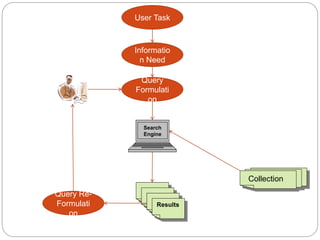
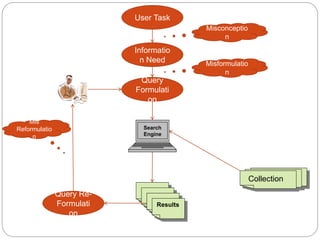





















This document discusses building an inverted index to efficiently support information retrieval on large document collections. It describes tokenizing documents, building a dictionary of normalized terms, and creating postings lists that map each term to the documents it appears in. Inverted indexes allow skipping linear scanning and support flexible queries by indexing term locations. The document also covers calculating precision and recall to measure system effectiveness.






























































































