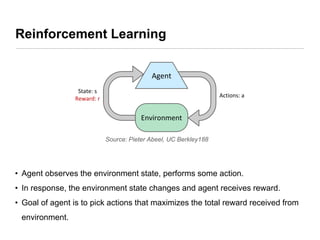
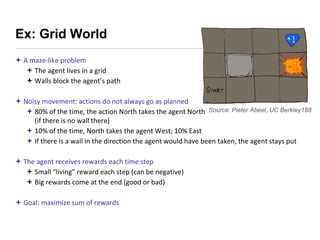
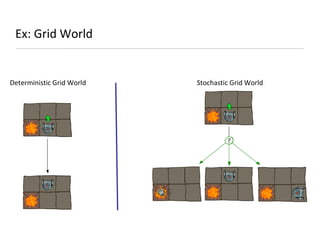
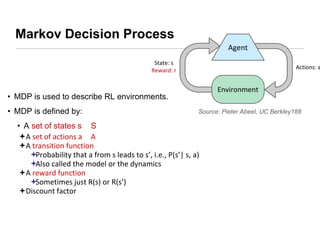
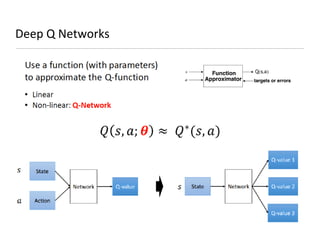
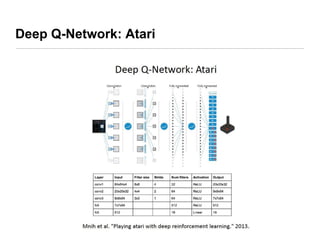
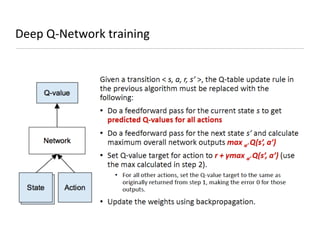
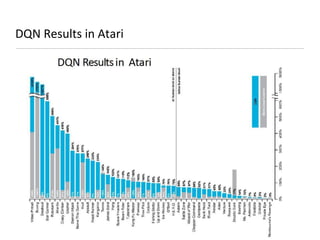
This document presents an introduction to deep reinforcement learning, outlining its foundational concepts, types, and mechanisms. It explains how agents interact with their environment to maximize rewards through various methods, including model-based and model-free learning techniques like Q-learning. The document also discusses the challenges of approximating Q-values in complex environments and introduces deep Q-networks as a solution.































![[1808.00177] Learning Dexterous In-Hand Manipulation](https://cdn.slidesharecdn.com/ss_thumbnails/learningdextrousinhandmanipulation-180814000608-thumbnail.jpg?width=640&height=640&fit=bounds)












































































