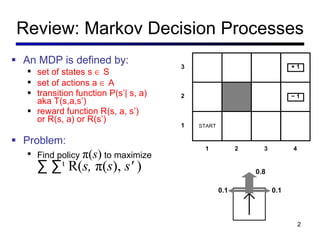
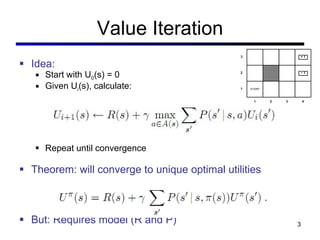
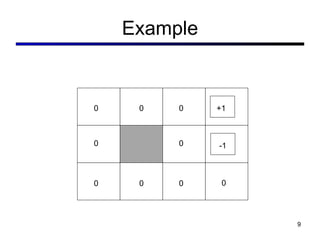
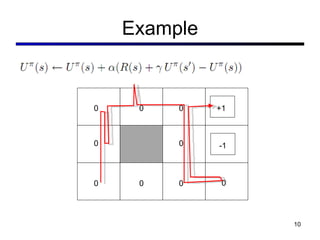
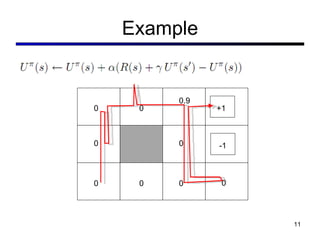
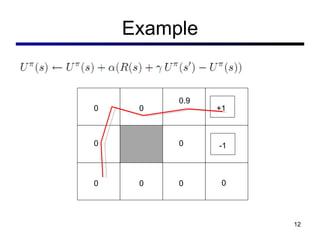
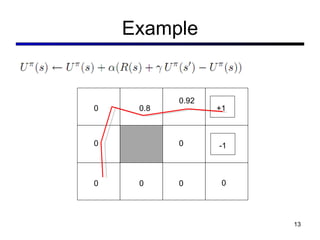
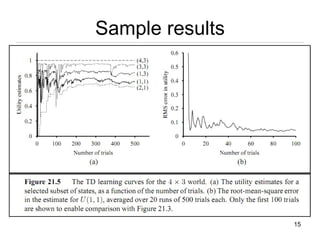
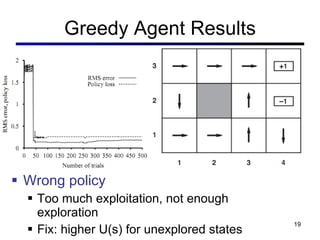
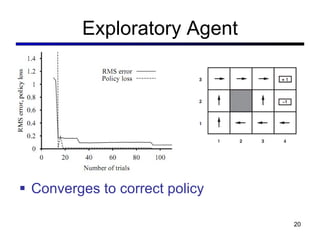
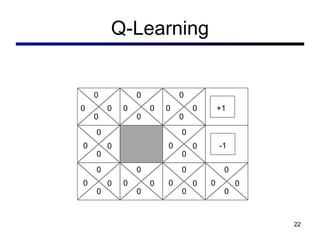
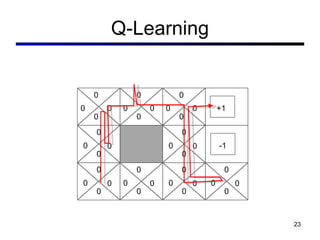
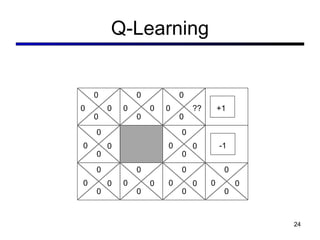
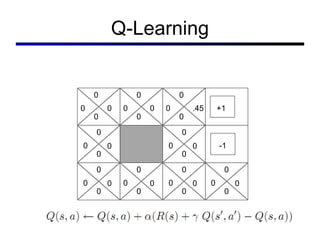
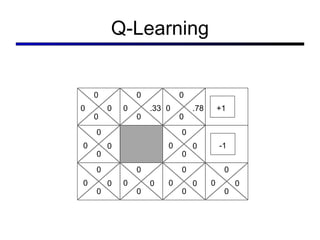
This document discusses reinforcement learning and Markov decision processes (MDPs). It introduces key concepts like states, actions, rewards, policies, value functions, and model-based vs model-free reinforcement learning. It also covers specific algorithms like Q-learning, temporal difference learning, and using linear function approximation to generalize value functions to new states based on their features. The document uses examples like backgammon, animal learning, and Pacman to illustrate reinforcement learning concepts and techniques.