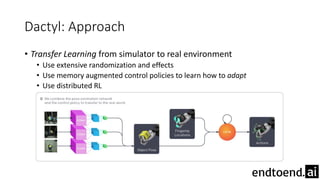
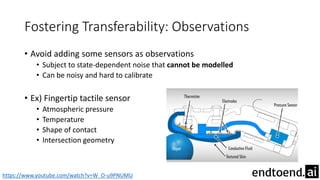
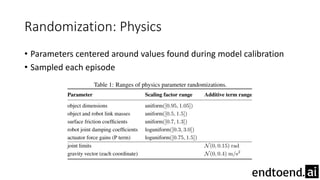
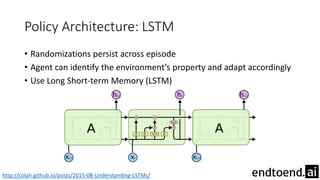
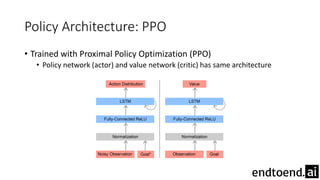
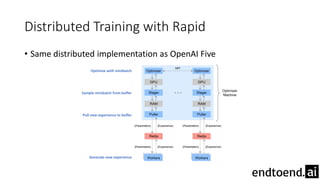
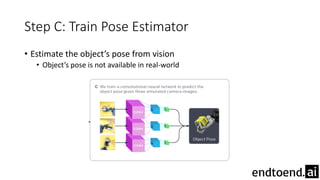
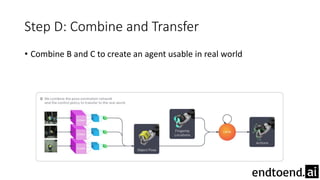
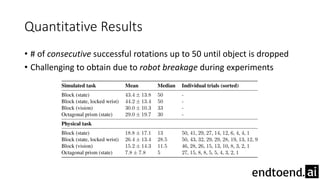
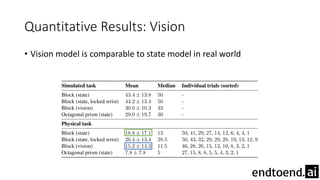
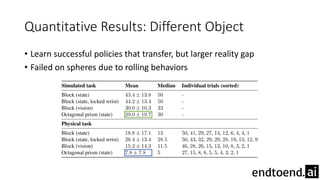
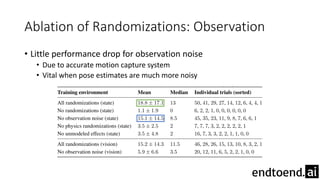
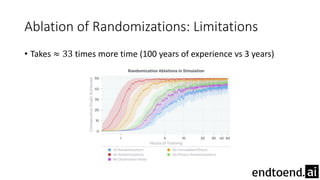
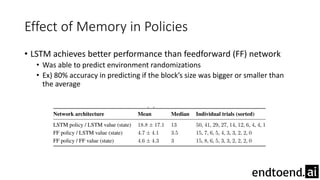
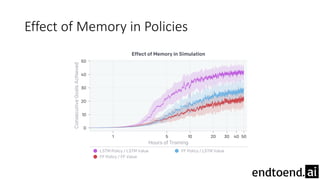
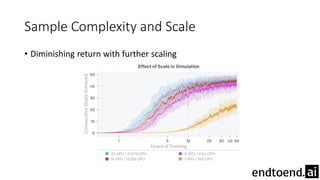
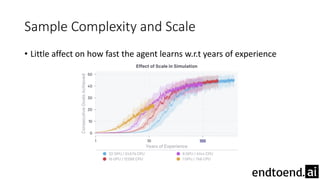
This document summarizes research on training a robot hand to perform dexterous in-hand manipulation tasks. The researchers used a simulation environment to generate large amounts of training data and trained a policy using reinforcement learning and domain randomization. They found the policy could transfer to controlling a real robot hand to successfully reorient objects, even generalizing to new objects. Key aspects that improved transferability included randomizing the simulation, using memory in the policy network, and training a vision model to estimate object pose without sensors.
























![[1312.5602] Playing Atari with Deep Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/playingatariwithdeepreinforcementlearning-180814064557-thumbnail.jpg?width=640&height=640&fit=bounds)










































![[NS][Lab_Seminar_250120]HandDAGT: A Denoising Adaptive Graph Transformer for ...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250120handdagt-250120113035-c191516d-thumbnail.jpg?width=640&height=640&fit=bounds)





















