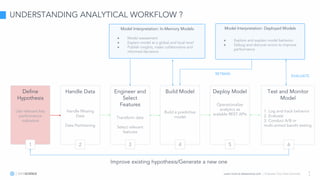
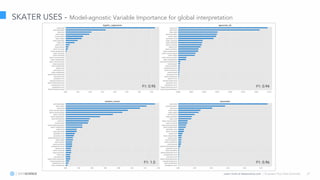
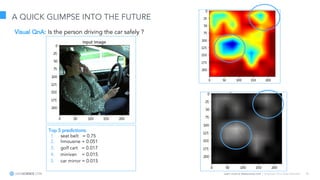
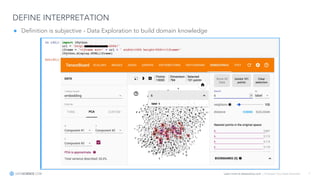
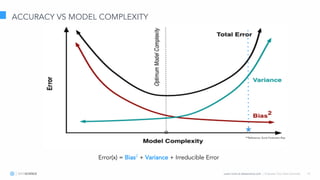
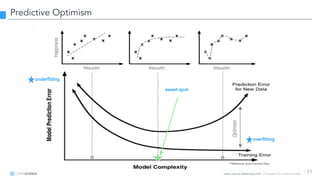
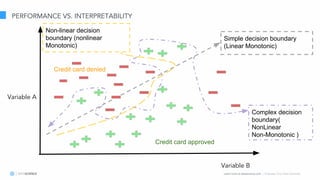
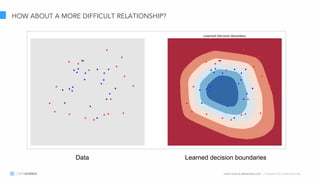
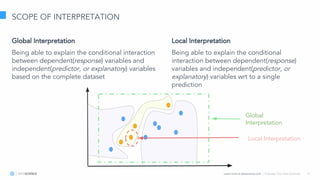
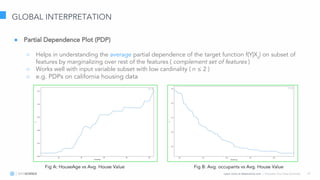
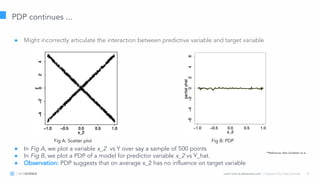
The document discusses model interpretation and the Skater library. It begins with defining model interpretation and explaining why it is needed, particularly for understanding model behavior and ensuring fairness. It then introduces Skater, an open-source Python library that provides model-agnostic interpretation tools. Skater uses techniques like partial dependence plots and LIME explanations to interpret models globally and locally. The document demonstrates Skater's functionality and discusses its ability to interpret a variety of model types.













![Learn more at datascience.com | Empower Your Data Scientists 22
LOCAL INTERPRETATION
● Ability to inspect and evaluate individual prediction in human interpretable format with the help of
surrogate models faithfully
○ ὲ : model explanation function
○ ℒ : measure of fidelity
○ ƒ : is the base model estimator
○ g ⊂ G : a set of interpretable models [ Linear Models, Decision Trees ]
○ ∏x
: proximity measure to define locality around an individual point
○ Ω : to regularize complexity e.g. depth of the tree, learning rate, non-zero weights for linear
models](https://image.slidesharecdn.com/8pramitchoudharylearningtolearnmodelbehavior-171206022810/85/Learning-to-learn-Model-Behavior-How-to-use-human-in-the-loop-to-explain-decisions-22-320.jpg)