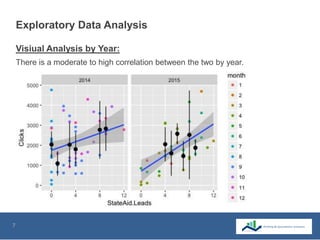
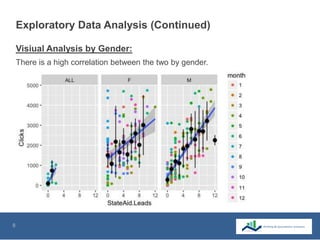
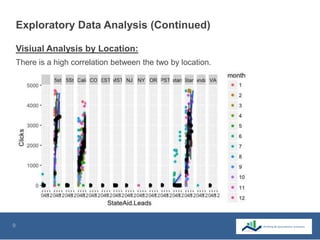
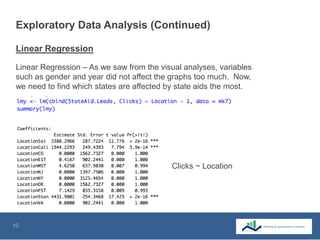
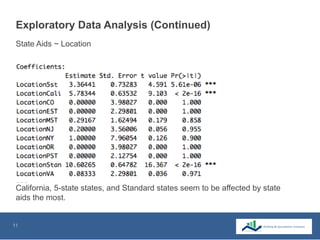
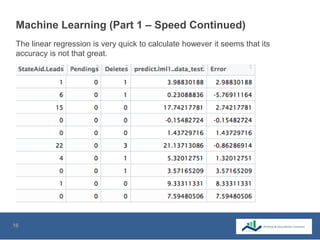
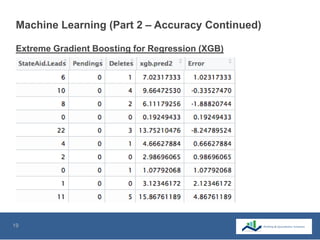
This document summarizes the use of machine learning to optimize advertising campaigns for a media company. It discusses collecting click and conversion data from various sources, cleaning the data, then using exploratory analysis and linear regression to see correlations between clicks, conversions and state aids by year, gender and location. Different machine learning models like linear regression and XGB regression are tested on partitioned training and test sets, with XGB regression showing best accuracy. The models help identify states most affected by state aids and allow limiting ads in those states to reduce state aids while optimizing click to aid ratios. This helps prolong the client contract by increasing pure sales.