Download as PDF, PPTX







![Observations (Contd.)
The process gets started by
calling reset(), which returns an
initial observation. So a more
proper way of writing the
previous code with respect to
the episodes and done flag:
CODE:
import gym
env = gym.make('CartPole-v0')
for i_episode in range(20):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} time steps".format(t+1))
break
env.close()
OUTPUT:
[-0.03327757 0.5649743 -0.0374682 -0.87239967]
[-0.02197809 0.7605852 -0.05491619 -1.17662316]
[-0.00676638 0.95637585 -0.07844866 -1.48600365]
[ 0.01236114 1.15236136 -0.10816873 -1.80211802]
[ 0.03540836 1.3485132 -0.14421109 -2.12636579]
[ 0.06237863 1.15508926 -0.18673841 -1.88149287]
Episode finished after 11 time steps](https://image.slidesharecdn.com/reinforcementlearning-190822050702/85/Reinforcement-Learning-using-OpenAI-Gym-13-320.jpg)
![Using Neural Network In
TensorFlow for Reinforcement
Learning (Contd.)
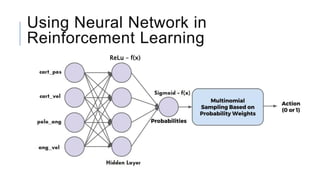
Let's design a simple Neural
Network that takes in the
observation array passes it through
a hidden layer and output
probability for left. (for right = left-1)
CODE:
import tensorflow as tf
import gym
import numpy as np
# PART ONE: NETWORK VARIABLES #
# Observation Space has 4 inputs
num_inputs = 4
num_hidden = 4
# Outputs the probability it should go left
num_outputs = 1
initializer = tf.contrib.layers.variance_scaling_initializer()
# PART TWO: NETWORK LAYERS #
X = tf.placeholder(tf.float32, shape=[None, num_inputs])
hidden_layer_one = tf.layers.dense(X,n um_hidden,activation = tf.nn.relu, kernel_initializer=initializer)
hidden_layer_two = tf.layers.dense(hidden_layer_one, num_hidden, activation=tf.nn.relu, kernel_initializer=initializer)
# Probability to go left
output_layer = tf.layers.dense(hidden_layer_one, num_outputs, activation=tf.nn.sigmoid, kernel_initializer=initializer)
# [ Prob to go left , Prob to go right]
probabilties = tf.concat(axis=1, values=[output_layer, 1 - output_layer])
# Sample 1 randomly based on probabilities
action = tf.multinomial(probabilties, num_samples=1)
init = tf.global_variables_initializer()
# PART THREE: SESSION #
saver = tf.train.Saver()
epi = 50
step_limit = 500
avg_steps = []
env = gym.make("CartPole-v1")
with tf.Session() as sess:
init.run()
for i_episode in range(epi):
obs = env.reset()
for step in range(step_limit):
env.render()
action_val = action.eval(feed_dict={X: obs.reshape(1, num_inputs)})
obs, reward, done, info = env.step(action_val[0][0])
if done:
avg_steps.append(step)
print('Done after {} steps'.format(step))
break
print("After {} episodes the average cart steps before done was {}".format(epi, np.mean(avg_steps)))
env.close()Note: 2x zoom required.](https://image.slidesharecdn.com/reinforcementlearning-190822050702/85/Reinforcement-Learning-using-OpenAI-Gym-16-320.jpg)

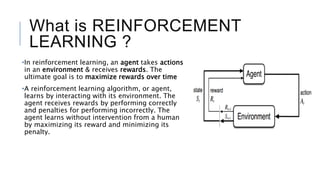
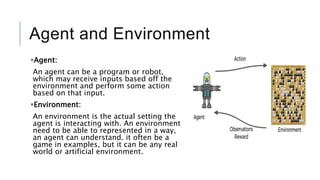
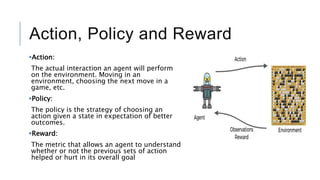
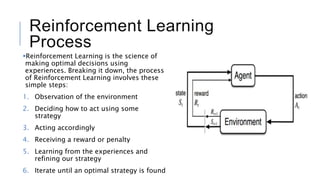
An agent interacts with an environment to maximize rewards. Reinforcement learning algorithms learn through trial and error by taking actions and receiving rewards or penalties. The document discusses reinforcement learning concepts like the agent, environment, actions, policy, and rewards. It also summarizes OpenAI Gym, a toolkit for developing and comparing reinforcement learning algorithms with different environments like CartPole. Code examples are provided to interact with environments using a hardcoded policy and a basic neural network.










































































