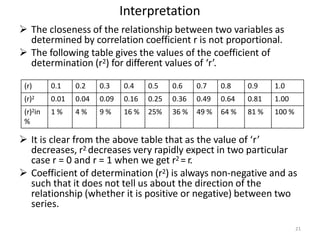
This document discusses correlation and defines it as the statistical relationship between two variables, where a change in one variable results in a corresponding change in the other. It describes different types of correlation including positive, negative, simple, partial and multiple. Methods for studying correlation are also outlined, including scatter diagrams and Karl Pearson's coefficient of correlation (represented by r), which quantifies the strength and direction of the linear relationship between two variables from -1 to 1. The coefficient of determination (r2) is also introduced, which expresses the proportion of variance in one variable that is predictable from the other.