Downloaded 13 times









![Memory Operands
Memory used to store composite data
Arrays, structures, dynamic data
Uses in arithmetic operations
Load values from memory into registers
Store result from register to memory
Memory is byte addressed
Each address identifies an 8-bit byte
An word, 32 bit data occupy 4bytes
byte [0, 1, 2, 3] 1 word
Byte of an word can be aligned in 2 ways into the memory
Big Endian: Most-significant byte(0) at least address(0) of a word
Little Endian: least-significant byte(3) at least address (0) of a words
Memory
address
1st Byte 2nd Byte 3rd Byte 4th Byte
100
104
108
112
Memory
address
1st Byte 2nd Byte 3rd Byte 4th Byte
100 0 (MSB) 1 2 3 (LSB)
104 4 5 6 7
108 8 9 10 11
112 12 13 14 15
Dr. Prasenjit Dey
9](https://image.slidesharecdn.com/instructionsetarchitecturemips-210531172400/85/Instruction-Set-Architecture-MIPS-9-320.jpg)
![Memory Operand Example
C code:
c = b + A[8];
c, b are in $s1, $s2
base address of A in $s3
A[12] = b + A[8];
Compiled MIPS code:
Array Index = 8
1 item occupy 4 bytes(1 word)
requires offset of (8*4) = 32
lw $t0, 32($s3) # Load Word A[8] into $t0
add $s1, $s2, $t0 # add b and A[8]
lw $t0, 32($s3) # Load Word A[8] into $t0
add $t0, $s2, $t0 # add b and A[8]
sw $t0, 48($s3) # store into A[12]
Dr. Prasenjit Dey
10](https://image.slidesharecdn.com/instructionsetarchitecturemips-210531172400/85/Instruction-Set-Architecture-MIPS-10-320.jpg)











![Swap operations
C code:
Swap procedure (leaf)
void swap(int v[], int i)
{
int temp;
temp = v[i];
v[i] = v[i+1];
v[i+1] = temp;
}
MIPS code:
Save v in $a0, i in $a1, temp in $t0
swap: sll $t1, $a1, 2 # $t1 = i * 4
add $t1, $a0, $t1 # $t1 = v+(i*4) #(address of v[i])
lw $t0, 0($t1) #$t0 = v[i]
lw $t2, 4($t1) #$t2 = v[i+1]
sw $t2, 0($t1) #v[i] = $t2
sw $t0, 4($t1) #v[i+1] = $t0
jr $ra #return to calling routine
Dr. Prasenjit Dey
22](https://image.slidesharecdn.com/instructionsetarchitecturemips-210531172400/85/Instruction-Set-Architecture-MIPS-22-320.jpg)
![Loop Statements
C code:
while (save[i] == k)
i += 1;
Compiled MIPS code:
i in $s0, k in $s1, address of save in $s2
Loop: sll $t1, $s0, 2 #t1 = i*4;byte addressing
add $t1, $t1, $s2 #t1 = base addr. + offset
lw $t0, 0($t1) #load data into $t0
bne $t0, $s1, Exit
addi $s0, $s0, 1
j Loop
Exit:
Dr. Prasenjit Dey
23](https://image.slidesharecdn.com/instructionsetarchitecturemips-210531172400/85/Instruction-Set-Architecture-MIPS-23-320.jpg)













![Demonstration: C Code
ArrayTest(int a[], int size) {
int i;
for (i = 0; i < size; i += 1)
a[i] = 0;
}
Save i, a, size in $t0, $a0, $a1
add $t0, $zero, $zero # i = 0
L1: sll $t1, $t0, 2 # $t1 = i * 4
add $t2, $a0, $t1 # $t2 = &a[i]
sw $zero, 0($t2) # a[i] = 0
addi $t0, $t0, 1 # i = i + 1
slt $t3, $t0, $a1 # $t3 =1 if(i < size)
bne $t3, $zero, L1 # if $t3=1, goto L1
PointerTest(int *a, int size) {
int *p;
for (p = &a[0]; p < &a[size]; p = p + 1)
*p = 0;
}
Save p in $t0
add $t0, $a0, $zero # p = & a[0]
sll $t1, $a1, 2 # $t1 = size * 4
add $t2, $a0, $t1 # $t2 =&a[size]
L2: sw $zero, 0($t2) # a[p] = 0
addi $t0, $t0, 4 # p = p + 4
slt $t3, $t0, $t2 #$t3 =(p<&a[size])
bne $t3, $zero, L2 # if $t3=1, goto L2
Dr. Prasenjit Dey
38
6 instructions inside loop
4 instructions inside loop](https://image.slidesharecdn.com/instructionsetarchitecturemips-210531172400/85/Instruction-Set-Architecture-MIPS-38-320.jpg)



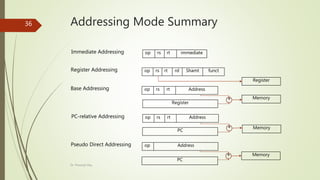
This document provides an overview of the MIPS instruction set architecture (ISA), which is a well-known and widely used architecture established in the 1980s. It covers various aspects of MIPS, including instruction formats, arithmetic operations, register usage, memory operands, and procedure calls, emphasizing design principles that enhance performance and efficiency. The document also includes examples of compiled C code into MIPS assembly language to illustrate these concepts.























































































