Download as PDF, PPTX


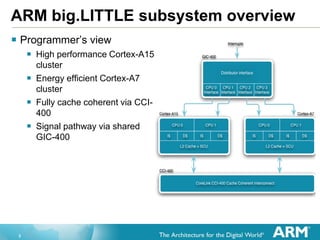

















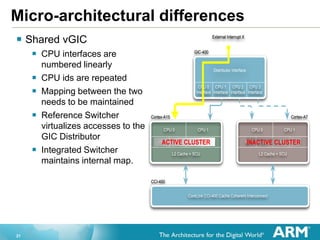



The document discusses the implications of per-CPU switching in ARM's big.LITTLE architecture, covering topics such as execution modes, the reference switcher, interoperability with Linux's operating system power management (OSPM), and micro-architectural differences between CPU clusters. It highlights the mechanics of cluster switching and policies for power management, as well as optimizations necessary for efficiency and cache management. Key points include the importance of the reference switcher in facilitating cluster migration and the challenges posed by asymmetrical topologies and coordination with operating system support.






























![Librosweb Listado Hasta El 30 De Septiembre 2009[1]](https://cdn.slidesharecdn.com/ss_thumbnails/librosweblistadohastael30deseptiembre20091-091023182740-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)












































































