Downloaded 93 times




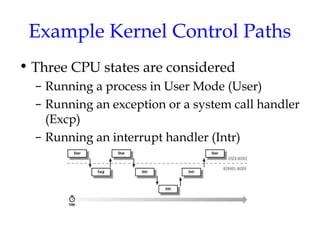












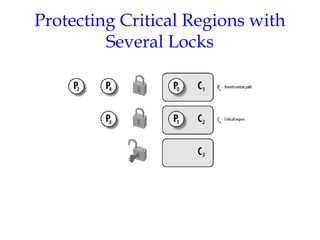



















This document discusses kernel synchronization in Linux. It begins by outlining kernel control paths and when synchronization is necessary, such as to prevent race conditions when kernel control paths are interleaved. It then describes various synchronization primitives like spin locks, semaphores, and RCU. Examples are given of how these primitives can be used to synchronize access to kernel data structures. Interrupt-aware versions of synchronization primitives are also outlined. The document concludes with examples of how race conditions are prevented for specific data structures and operations in the kernel.























































































