Downloaded 612 times












![[1] Zebo Peng. (2010). General format, “Superscalar Architecture – IDA”, Lecture 3
Introduction to Parallel Architectures.
[2] William M. Johnson, “Super-Scalar Processor Design”, Stanford University
Since 1989
[3] James E. Smith (1995), “The Microarchitecture of Superscalar Processors”,
senior member IEEE
[4] Subbarao Palacharla, “Complexity -Effective Superscalar Processors”,
UNIVERSITY OF WISCONSIN—MADISON, Since 1998
[5] Alaa Alameldeen and Haitham Akkary, "The Microarchitecture of Superscalar
Processors", Portland State University, since 2014
[5] http://www.techterms.com/definition/superscalar
[6] https://www.google.com.bd/search?q=superscalar+archit
ecture&newwindow=1&tbm=isch&tbo=u&source=univ&sa=X&ei
=Ll1oU9umJNWHuASgwoDACA&ved=0CDUQsAQ&biw=1048&bih=921 23
Citation](https://image.slidesharecdn.com/superscalararchitectureaiub-140507233557-phpapp02/85/Superscalar-Architecture_AIUB-23-320.jpg)


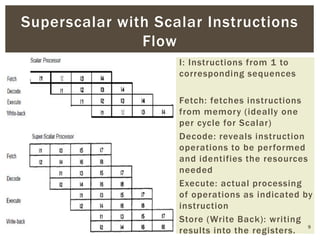
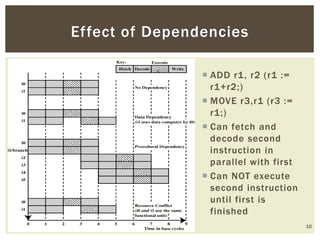
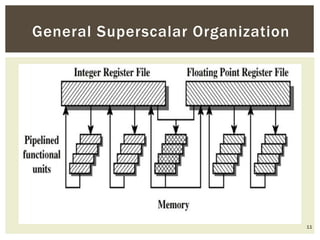
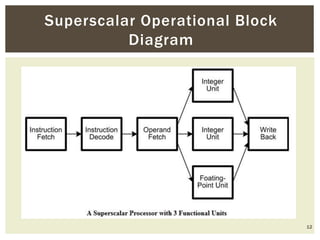
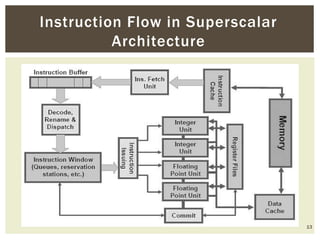
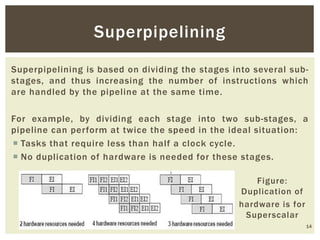
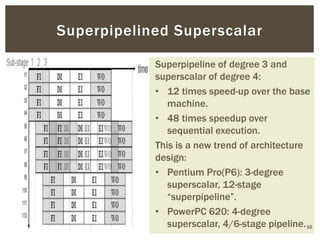
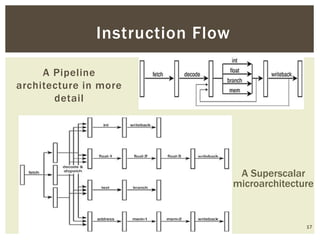
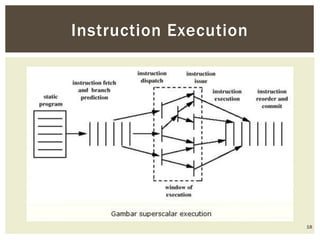
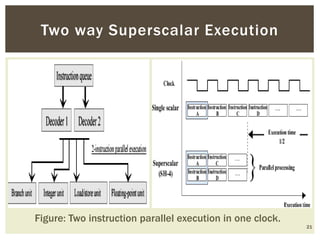
Superscalar architecture (SSA) allows a microprocessor to execute multiple instructions simultaneously during a single clock cycle, leveraging instruction-level parallelism to enhance performance. It enables the independent execution of several scalar instructions while incorporating features like pipelining to optimize instruction throughput. Tools like Simplescalar simulate these architectures, allowing the modeling of programs on modern processors.















































![Multithreading and Parallelism on iOS [MobOS 2013]](https://cdn.slidesharecdn.com/ss_thumbnails/mobos2013-131122085438-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







































