Downloaded 234 times












![This is not a contribution
Cached RDDs
•
Let's say you have an RDD[T], where each item is of type T.
Bytes are saved on JVM heap, or optionally heap + disk
Spark optionally serializes it, using by default Java
serialization, so it (hopefully) takes up less space
Pros: easy (myRdd.cache())
Cons: have to iterate over every item, no column
pruning, slow if need to deserialize, memory hungry,
cannot update](https://image.slidesharecdn.com/2ievanchan1-160616215829/85/700-Queries-Per-Second-with-Updates-Spark-As-A-Real-Time-Web-Service-14-320.jpg)
![This is not a contribution
Cached DataFrames
•
Works on a DataFrame (RDD[Row] with a schema)
•
sqlContext.cacheTable(tableA)
Uses columnar storage for very efficient storage
Columnar pruning for faster querying
Pros: easy, efficient memory footprint, fast!
Cons: no filtering, cannot update](https://image.slidesharecdn.com/2ievanchan1-160616215829/85/700-Queries-Per-Second-with-Updates-Spark-As-A-Real-Time-Web-Service-15-320.jpg)















![This is not a contribution
Initial Results
Run lots of queries concurrently using collectAsync
Spark local[*] mode
SQL queries on first million rows of NYC Taxi dataset
50 Queries per Second
Most of time not running queries but parsing SQL !](https://image.slidesharecdn.com/2ievanchan1-160616215829/85/700-Queries-Per-Second-with-Updates-Spark-As-A-Real-Time-Web-Service-33-320.jpg)


![This is not a contribution
SQL Plan Caching
•
Cache the `DataFrame` containing the logical plan translated from
parsing SQL.
•
Now - **700 QPS**!!
val cachedDF = new collection.mutable.HashMap[String, DataFrame]
def getCachedDF(query: String): DataFrame =
cachedDF.getOrElseUpdate(query, sql.sql(query))](https://image.slidesharecdn.com/2ievanchan1-160616215829/85/700-Queries-Per-Second-with-Updates-Spark-As-A-Real-Time-Web-Service-36-320.jpg)

![This is not a contribution
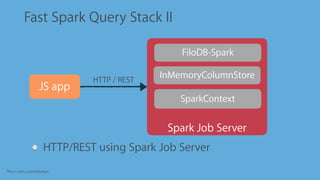
Fast Spark Query Stack
Run Spark context on heap with `local[*]`
Load FiloDB-Spark connector, load data in memory
Very fast queries all in process
Front end app
FiloDB-Spark
SparkContext
InMemoryColumnStore](https://image.slidesharecdn.com/2ievanchan1-160616215829/85/700-Queries-Per-Second-with-Updates-Spark-As-A-Real-Time-Web-Service-38-320.jpg)


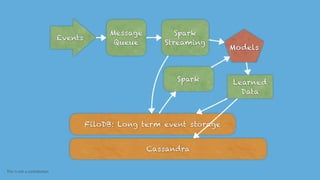
This document discusses using Apache Spark to enable low-latency web queries through a persistent Spark context. It introduces FiloDB, a distributed, versioned, columnar analytics database built on Spark that allows for fast, updatable queries through efficient in-memory columnar storage and filtering. The document demonstrates running over 700 SQL queries per second on a dataset of 15 million NYC taxi records loaded into FiloDB through caching of SQL parsing and use of Spark's collectAsync to enable asynchronous query execution.












































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)










