Downloaded 68 times






![SESSION CREATION
AND EXECUTION
% curl -XPOST localhost:8998/sessions
-d '{"kind": "spark"}'
{
"id": 0,
"kind": "spark",
"log": [...],
"state": "idle"
}
% curl -XPOST localhost:8998/sessions/0/statements -d '{"code": "1+1"}'
{
"id": 0,
"output": {
"data": { "text/plain": "res0: Int = 2" },
"execution_count": 0,
"status": "ok"
},
"state": "available"
}](https://image.slidesharecdn.com/20150818scalabythebay-150819153622-lva1-app6891/85/Big-Data-Scala-by-the-Bay-Interactive-Spark-in-your-Browser-25-320.jpg)


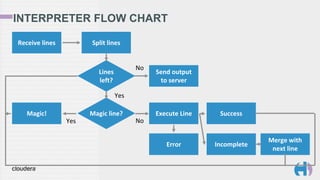
![LIVY INTERPRETERS
trait Interpreter {
def state: State
def execute(code: String): Future[JValue]
def close(): Unit
}
sealed trait State
case class NotStarted() extends State
case class Starting() extends State
case class Idle() extends State
case class Running() extends State
case class Busy() extends State
case class Error() extends State
case class ShuttingDown() extends State
case class Dead() extends State](https://image.slidesharecdn.com/20150818scalabythebay-150819153622-lva1-app6891/85/Big-Data-Scala-by-the-Bay-Interactive-Spark-in-your-Browser-30-320.jpg)
![LIVY INTERPRETERS
trait Interpreter {
def state: State
def execute(code: String): Future[JValue]
def close(): Unit
}
sealed trait State
case class NotStarted() extends State
case class Starting() extends State
case class Idle() extends State
case class Running() extends State
case class Busy() extends State
case class Error() extends State
case class ShuttingDown() extends State
case class Dead() extends State](https://image.slidesharecdn.com/20150818scalabythebay-150819153622-lva1-app6891/85/Big-Data-Scala-by-the-Bay-Interactive-Spark-in-your-Browser-31-320.jpg)



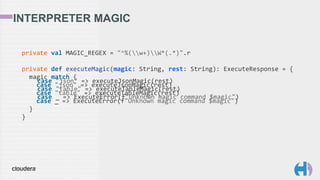
![INTERPRETER MAGIC
private def executeJsonMagic(name: String): ExecuteResponse = {
sparkIMain.valueOfTerm(name) match {
case Some(value: RDD[_]) => ExecuteMagic(Extraction.decompose(Map(
"application/json" -> value.asInstanceOf[RDD[_]].take(10))))
case Some(value) => ExecuteMagic(Extraction.decompose(Map(
"application/json" -> value)))
case None => ExecuteError(f"Value $name does not exist")
}
}
case Some(value: RDD[_]) => ExecuteMagic(Extraction.decompose(Map(
"application/json" -> value.asInstanceOf[RDD[_]].take(10))))
case Some(value) => ExecuteMagic(Extraction.decompose(Map(
"application/json" -> value)))](https://image.slidesharecdn.com/20150818scalabythebay-150819153622-lva1-app6891/85/Big-Data-Scala-by-the-Bay-Interactive-Spark-in-your-Browser-36-320.jpg)
![TABLE MAGIC
"application/vnd.livy.table.v1+json": {
"headers": [
{ "name": "count", "type": "BIGINT_TYPE" },
{ "name": "name", "type": "STRING_TYPE" }
],
"data": [
[ 23407, "the" ],
[ 19540, "I" ],
[ 18358, "and" ],
...
]
}
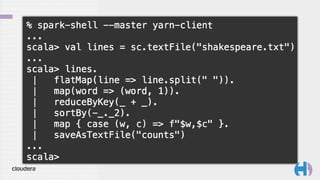
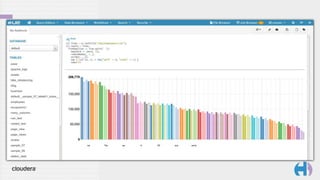
val lines = sc.textFile("shakespeare.txt");
val counts = lines.
flatMap(line => line.split(" ")).
map(word => (word, 1)).
reduceByKey(_ + _).
sortBy(-_._2).
map { case (w, c) =>
Map("word" -> w, "count" -> c)
}
%table counts%table counts](https://image.slidesharecdn.com/20150818scalabythebay-150819153622-lva1-app6891/85/Big-Data-Scala-by-the-Bay-Interactive-Spark-in-your-Browser-37-320.jpg)
![TABLE MAGIC
"application/vnd.livy.table.v1+json": {
"headers": [
{ "name": "count", "type": "BIGINT_TYPE" },
{ "name": "name", "type": "STRING_TYPE" }
],
"data": [
[ 23407, "the" ],
[ 19540, "I" ],
[ 18358, "and" ],
...
]
}
val lines = sc.textFile("shakespeare.txt");
val counts = lines.
flatMap(line => line.split(" ")).
map(word => (word, 1)).
reduceByKey(_ + _).
sortBy(-_._2).
map { case (w, c) =>
Map("word" -> w, "count" -> c)
}
%table counts](https://image.slidesharecdn.com/20150818scalabythebay-150819153622-lva1-app6891/85/Big-Data-Scala-by-the-Bay-Interactive-Spark-in-your-Browser-38-320.jpg)
![JSON MAGIC
val lines = sc.textFile("shakespeare.txt");
val counts = lines.
flatMap(line => line.split(" ")).
map(word => (word, 1)).
reduceByKey(_ + _).
sortBy(-_._2).
map { case (w, c) =>
Map("word" -> w, "count" -> c)
}
%json counts
{
"id": 0,
"output": {
"application/json": [
{ "count": 506610, "word": "" },
{ "count": 23407, "word": "the" },
{ "count": 19540, "word": "I" },
...
]
...
}
%json counts](https://image.slidesharecdn.com/20150818scalabythebay-150819153622-lva1-app6891/85/Big-Data-Scala-by-the-Bay-Interactive-Spark-in-your-Browser-39-320.jpg)
![JSON MAGIC
val lines = sc.textFile("shakespeare.txt");
val counts = lines.
flatMap(line => line.split(" ")).
map(word => (word, 1)).
reduceByKey(_ + _).
sortBy(-_._2).
map { case (w, c) =>
Map("word" -> w, "count" -> c)
}
%json counts
{
"id": 0,
"output": {
"application/json": [
{ "count": 506610, "word": "" },
{ "count": 23407, "word": "the" },
{ "count": 19540, "word": "I" },
...
]
...
}](https://image.slidesharecdn.com/20150818scalabythebay-150819153622-lva1-app6891/85/Big-Data-Scala-by-the-Bay-Interactive-Spark-in-your-Browser-40-320.jpg)



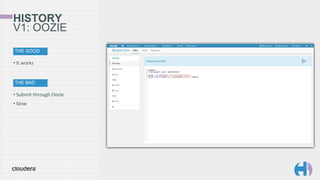
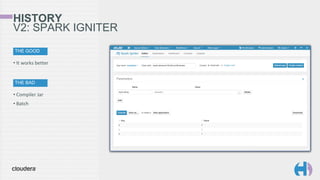
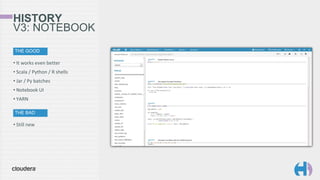
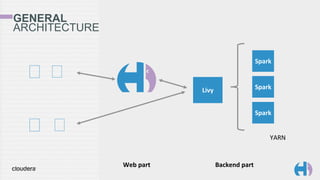
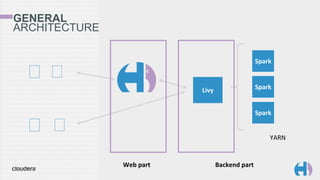
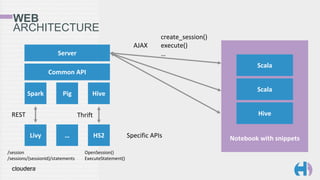
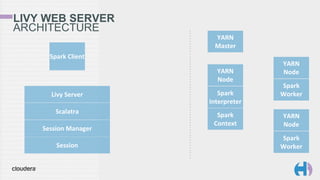
The document outlines the development and architecture of the Hue web interface for analyzing data through Apache Hadoop, emphasizing its integration with Apache Spark. It discusses the evolution of the platform, highlighting features such as Spark streaming, machine learning, and interactive notebooks, along with the use of RESTful web services for session management. The document also details Livy, a server that facilitates Spark sessions and supports multiple programming languages, enhancing user interactions with the Hadoop ecosystem.
































































































