Download to read offline










![Performance Metrics for stream data
mining processes
18
[1]Bifet A., Read J., Žliobaitė I., Pfahringer B., Holmes G. (2013) Pitfalls in Benchmarking Data Stream Classification and How to Avoid Them. In: Blockeel H., Kersting
K., Nijssen S., Železný F. (eds) Machine Learning and Knowledge Discovery in Databases. ECML PKDD 2013. Lecture Notes in Computer Science, vol 8188. Springer,
Berlin, Heidelberg
[2]Mingzhou Song,Lin Zhang, Comparison of Cluster Representations from Partial Second- to Full Fourth-Order Cross Moments for Data Stream Clustering,ICDM
'08. Eighth IEEE International Conference on Data Mining, 2008.
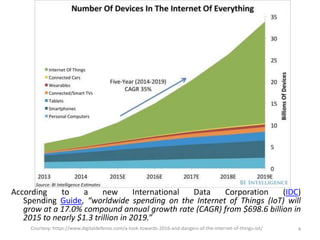
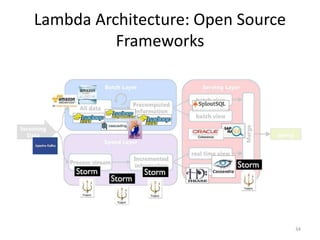
Task Evaluation Parameter Major Purpose Value significance
Classification
Kappa statistics [1] Assess performance imbalance
data stream case
Higher value means better
performance
Temporal-Kappa statistics [1] Assess performance in case of
temporal dependent data
stream
Negative value means worse
performance
Clustering
Completeness [2] Measures whether same class
instance fall in same cluster or
not
Higher value means better
clustering
Purity [2] Assesses purity of the clusters
in terms of having same class
instances
Higher value means better
clustering
SSQ [2] Measures cluster cohesiveness Lower value means better
performance
Silhouette coefficient [2] Assess compactness as well as
separation of clusters
Higher value means better
clustering](https://image.slidesharecdn.com/shikhafdp6214july2017-170719041956/85/Shikha-fdp-62_14july2017-17-320.jpg)


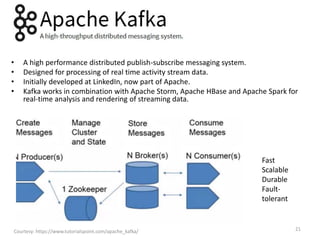
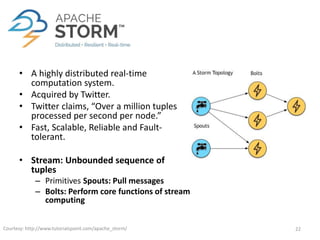
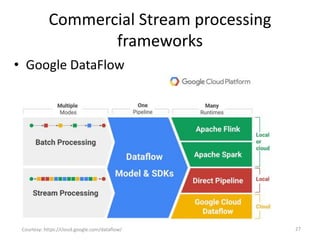
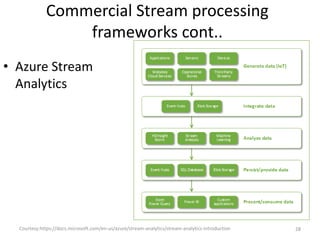

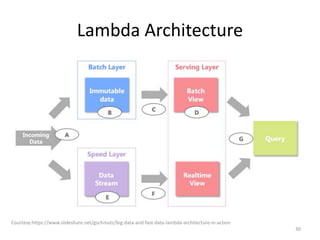


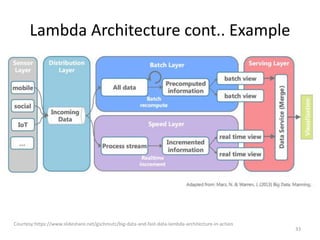
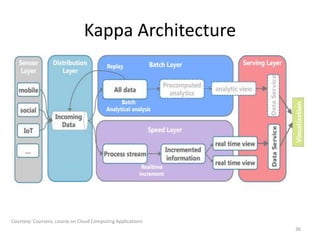



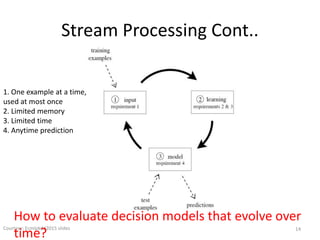
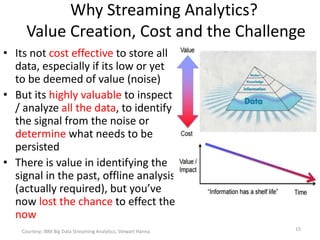
The document discusses performance metrics and frameworks for streaming data analytics within big data systems, emphasizing the differences between batch and stream processing. It highlights the challenges of processing and analyzing streaming data, including dealing with unstructured data and ensuring data privacy, while outlining the significance of real-time decision-making models. Key technologies mentioned include Kafka, Storm, and the Lambda and Kappa architectures for efficient streaming analytics.































![[WSO2Con EU 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/1-181113084942-thumbnail.jpg?width=640&height=640&fit=bounds)













![[WSO2Con USA 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/wso2conusa2018theriseofstreamingsql-180717041454-thumbnail.jpg?width=640&height=640&fit=bounds)




















