






![That’s Cool, but...
● But what if we want to scan data?
○ How to support API: scan(startKey, endKey, limit)
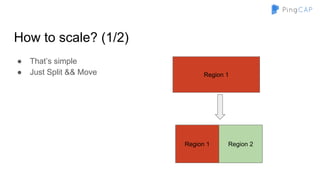
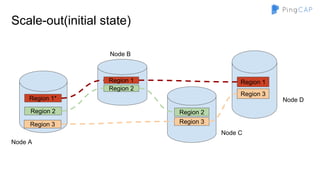
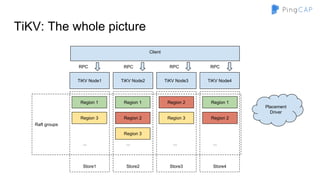
● So, we need a globally ordered map
○ Can’t use hash partitioning
○ Use range partitioning
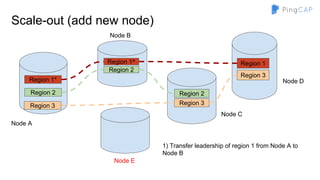
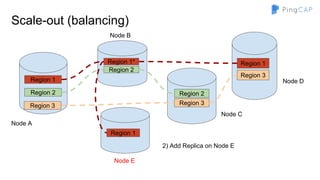
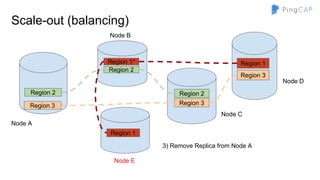
■ Region 1 -> [a - d]
■ Region 2 -> [e - h]
■ …
■ Region n -> [w - z]](https://image.slidesharecdn.com/howtobuildtidb-171130073818/85/How-to-build-TiDB-9-320.jpg)




![Transaction API style (go code)
txn := store.Begin() // start a transaction
txn.Set([]byte("key1"), []byte("value1"))
txn.Set([]byte("key2"), []byte("value2"))
err = txn.Commit() // commit transaction
if err != nil {
txn.Rollback()
}
I want to write
code like this.](https://image.slidesharecdn.com/howtobuildtidb-171130073818/85/How-to-build-TiDB-22-320.jpg)

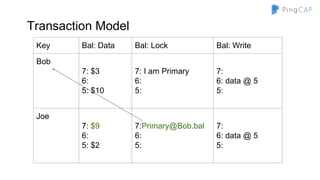
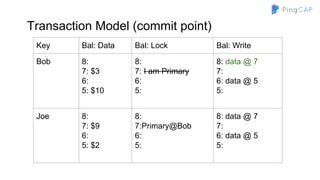
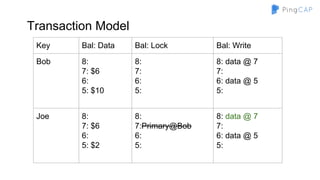
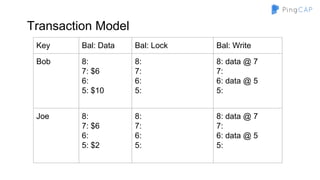










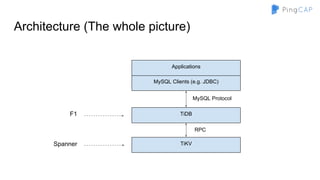








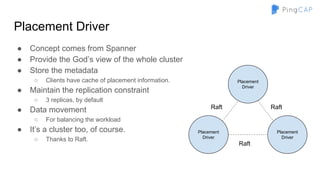
The document outlines the development of TiDB, a NewSQL database built by PingCAP, emphasizing its scalability, fault tolerance, and support for ACID transactions. It describes the architecture, which utilizes a distributed key-value store with features like data replication using Raft, horizontal scalability through partitioning, and SQL compatibility achieved through mapping relations to a key-value model. The overall goal is to create a highly available and performant database that can efficiently handle large-scale data and complex queries.




























![Introducing TiDB [Delivered: 09/27/18 at NYC SQL Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/nycmysqlintroducingtidb-180928024621-thumbnail.jpg?width=640&height=640&fit=bounds)

















![Introducing TiDB [Delivered: 09/25/18 at Portland Cloud Native Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/portlandk8smeetupintroducingtidb-180926052719-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Paper Reading] Efficient Query Processing with Optimistically Compressed Has...](https://cdn.slidesharecdn.com/ss_thumbnails/icde-2020-220209161641-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading]Orca: A Modular Query Optimizer Architecture for Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/orca-211220090600-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading]KVSSD: Close integration of LSM trees and flash translation la...](https://cdn.slidesharecdn.com/ss_thumbnails/kvssdcloseintegrationoflsmtreesandflashtranslationlayerforwrite-efficientkvstore-211206083654-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading]Chucky: A Succinct Cuckoo Filter for LSM-Tree](https://cdn.slidesharecdn.com/ss_thumbnails/chuckyasuccinctcuckoofilterforlsm-tree-211122111631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading]The Bw-Tree: A B-tree for New Hardware Platforms](https://cdn.slidesharecdn.com/ss_thumbnails/thebw-treeab-treefornewhardwareplatforms-211115032950-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] QAGen: Generating query-aware test databases](https://cdn.slidesharecdn.com/ss_thumbnails/datagenerator-211105075703-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] Leases: An Efficient Fault-Tolerant Mechanism for Distribute...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadingleases-211101103843-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper reading] Interleaving with Coroutines: A Practical Approach for Robust...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadinginterleavingwithcoroutinesapracticalapproachforrobustindexjoin-211011055753-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paperreading] Paxos made easy (by sen han)](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadingpaxosmadeeasybysenhan-210926142716-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] Generalized Sub-Query Fusion for Eliminating Redundant I/O fr...](https://cdn.slidesharecdn.com/ss_thumbnails/resin-210920113222-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] Steering Query Optimizers: A Practical Take on Big Data Workl...](https://cdn.slidesharecdn.com/ss_thumbnails/steersigmod21-210913065908-thumbnail.jpg?width=640&height=640&fit=bounds)




























