






![Data Model
Document
Collections containing semi- { id: ‘4b2b9f67a1f631733d917a7b"),’
author: ‘joe’,
structured data tags : [‘example’, ‘db’],
comments : [ { author: 'jim', comment: 'OK' },
{ author: ‘ida', comment: ‘Bad' }
key-values , JSON, XML, ]
CouchDB, MongoDB { id: ‘4b2b9f67a1f631733d917a7c"),
author: ‘ida’, ...
{ id: ‘4b2b9f67a1f631733d917a7d"),
author: ‘jim’, ...
Graph
Graph: nodes and edges
Edges can be directional
Each can contain key-value
attributes
Neo4j, Sones, InfiniteGraph](https://image.slidesharecdn.com/springone2gx2010-springnonrelationaldata-110808212043-phpapp01/75/Spring-one2gx2010-spring-nonrelational_data-14-2048.jpg)



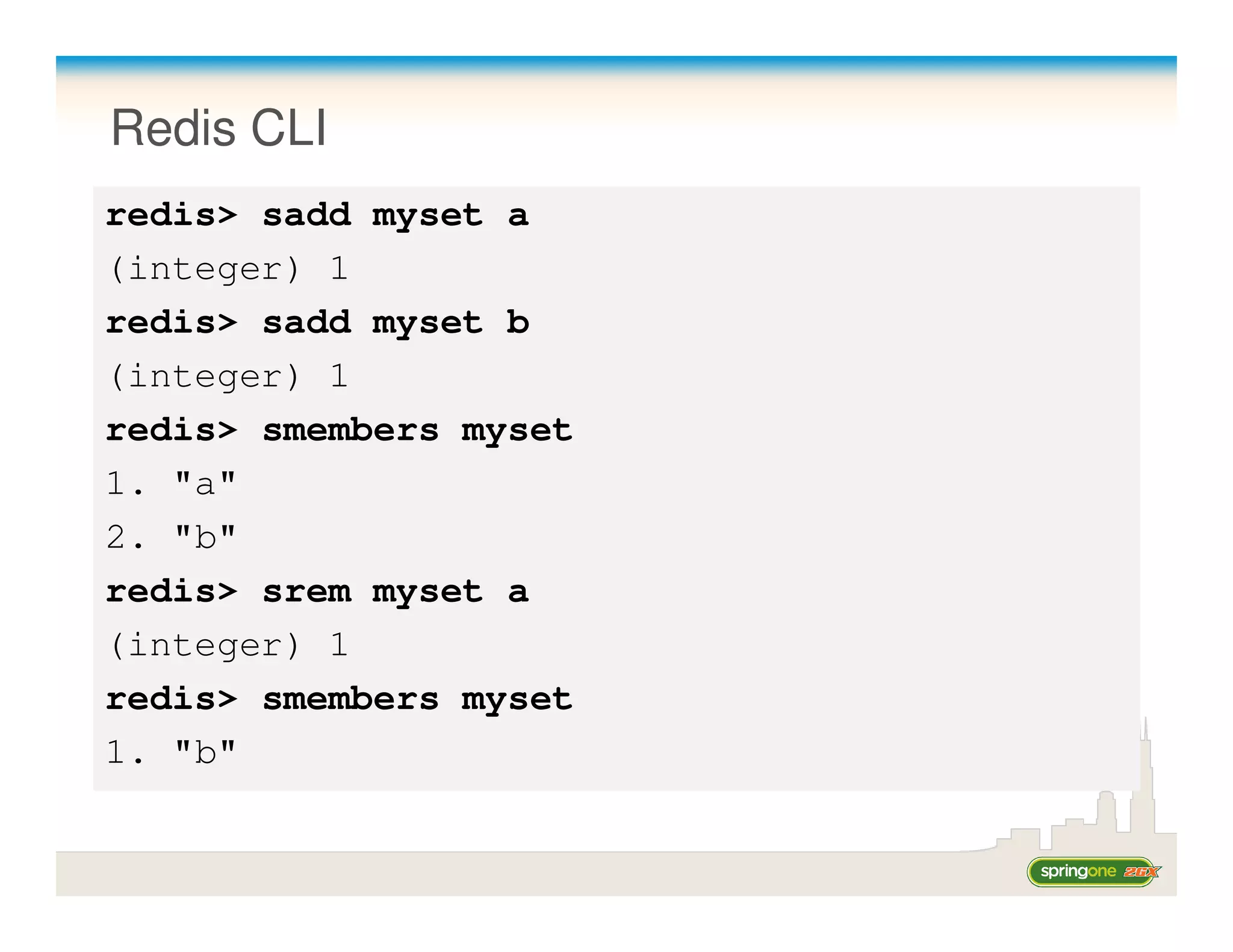



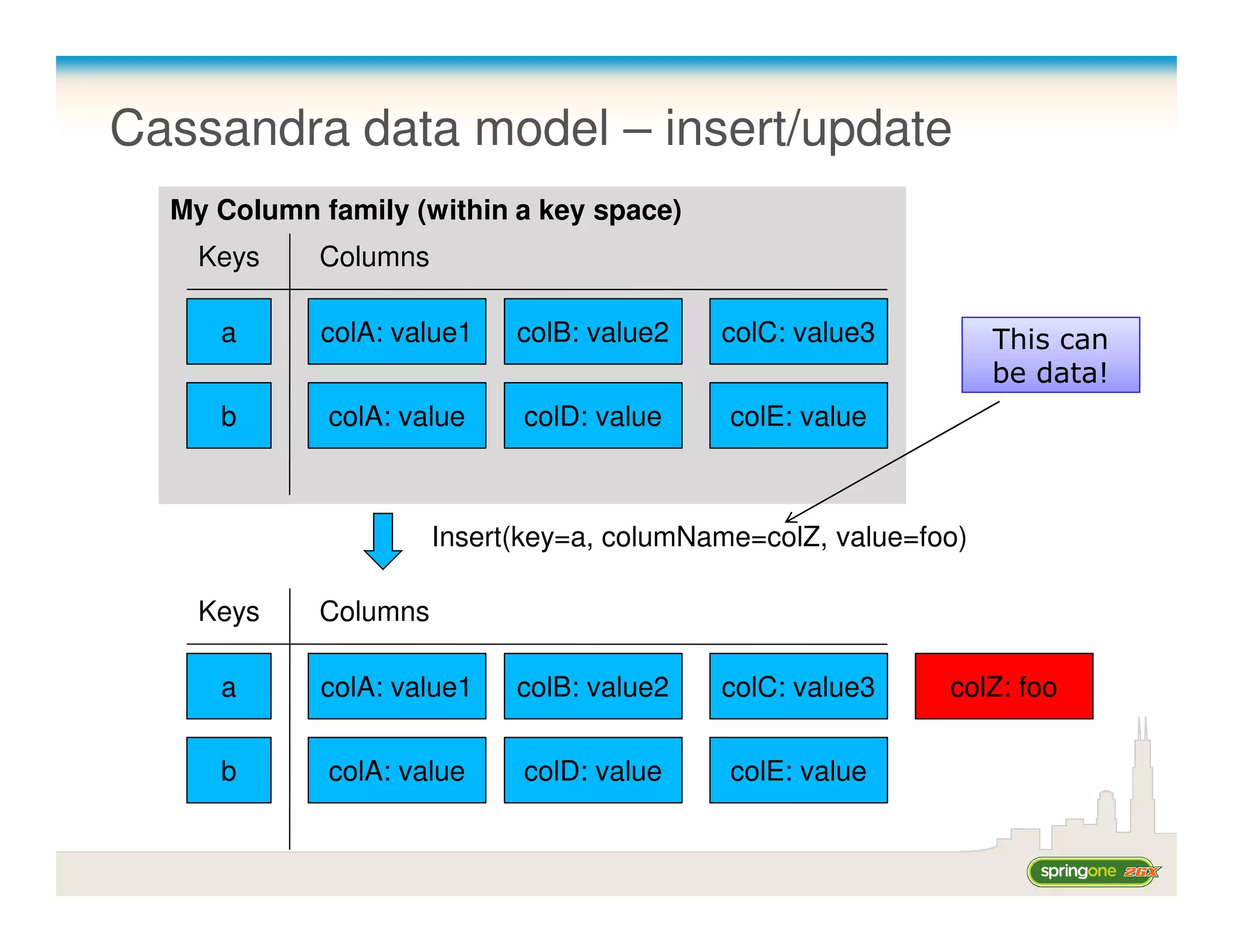
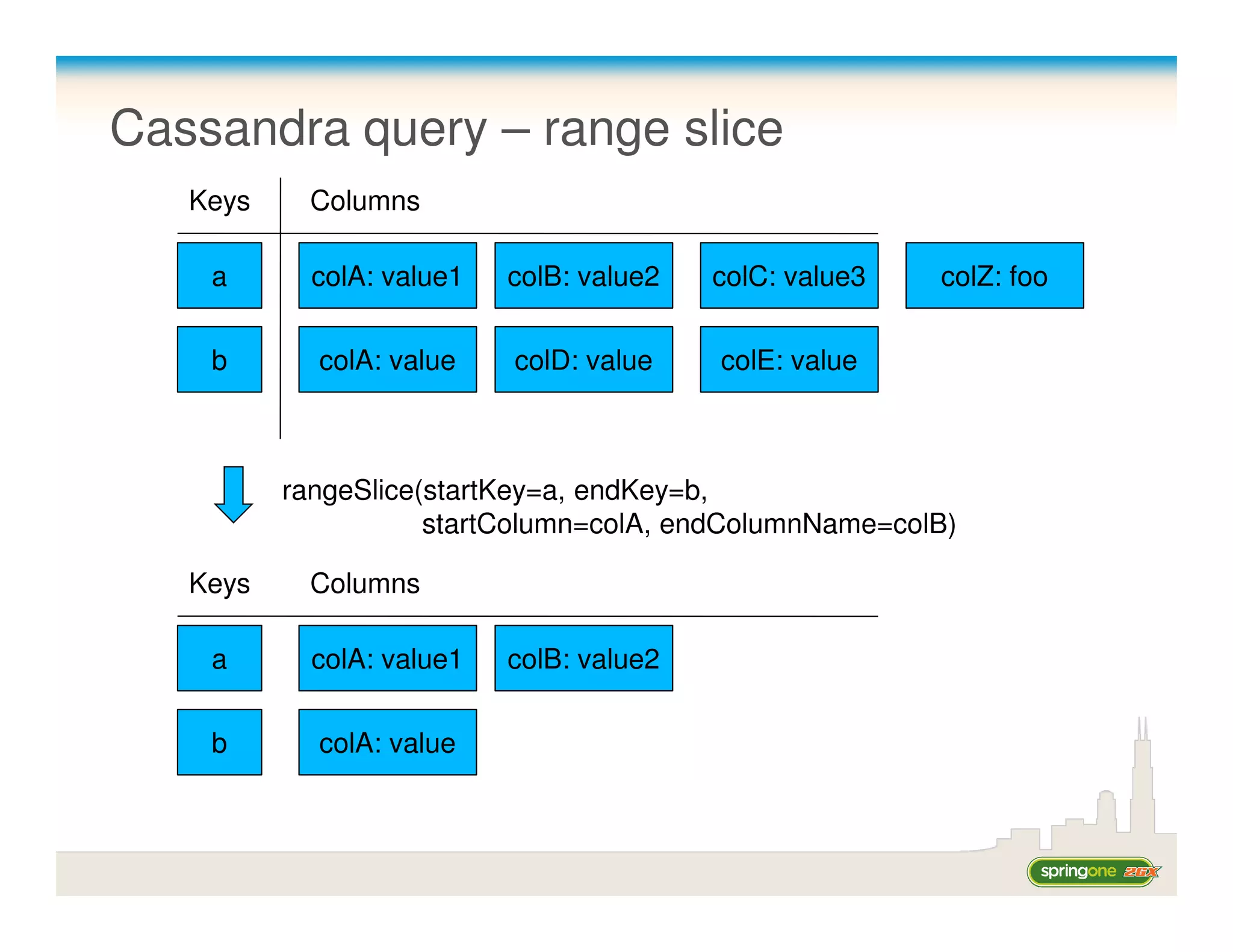
![Cassandra CLI
$ bin/cassandra-cli
cassandra> connect localhost/9160
Connected to "Test Cluster" on localhost/9160
cassandra> get Keyspace1.Standard1['foo']
Returned 0 results
cassandra> set Keyspace1.Standard1['foo']['a'] = '2'
Value inserted
cassandra> get Keyspace1.Standard1['foo']
=> (Column=61, value=1, timestamp...)
cassandra> set Keyspace1.Standard1['foo']['bar'] = 'abc'
Value inserted
cassandra> get Keyspace1.Standard1['foo']
=> (Column=626172, value=abc, timestamp...)
=> (Column=61, value=1, timestamp...)
cassandra> count Keyspace1.Standard1['foo']
2 columns
cassandra>](https://image.slidesharecdn.com/springone2gx2010-springnonrelationaldata-110808212043-phpapp01/75/Spring-one2gx2010-spring-nonrelational_data-27-2048.jpg)
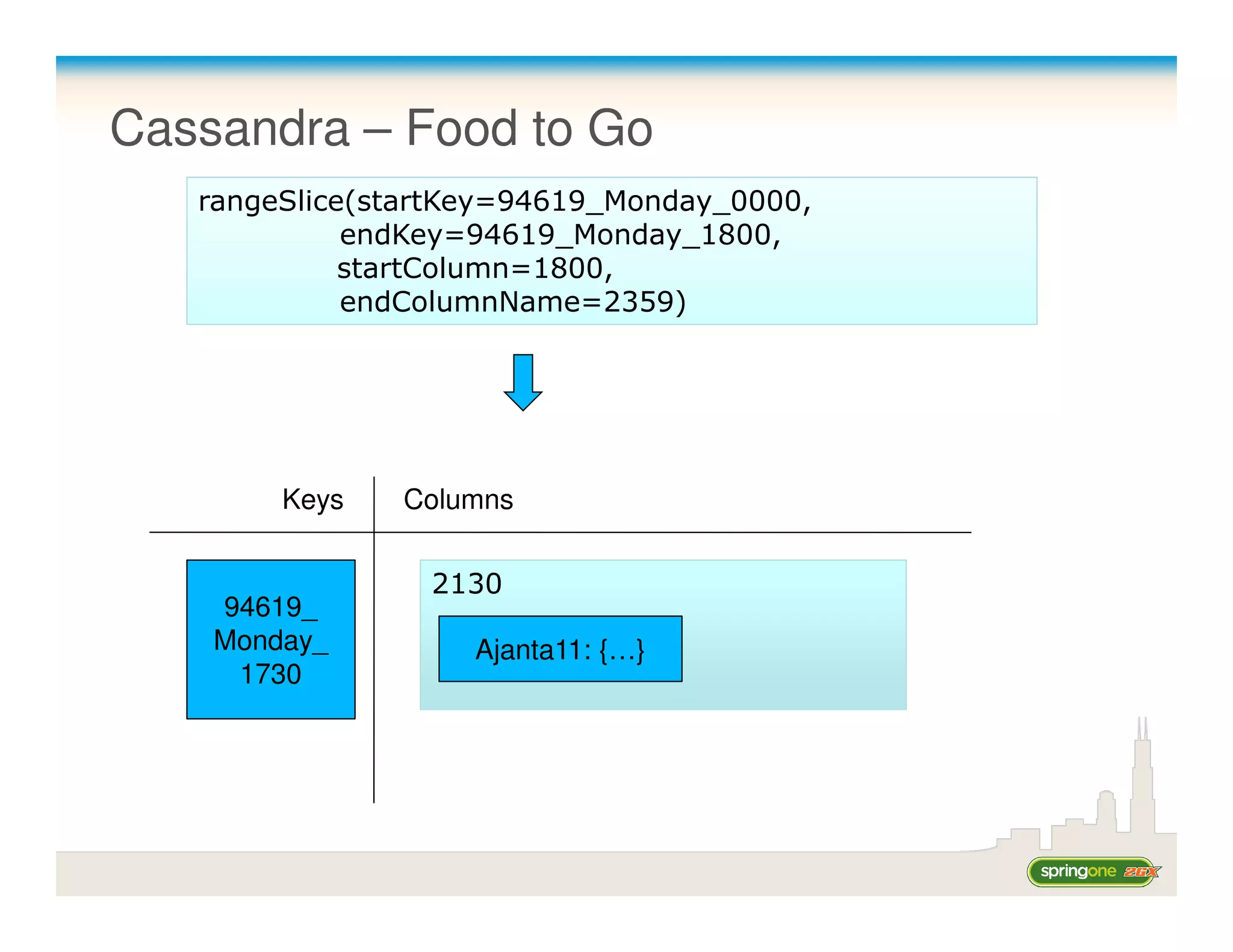
![Scaling Cassandra through sharding/replication
Keys = [D, A] •Client connects to any node
•Dynamically add/remove
nodes
Node 1
•Configurable # replicas
Token = A •Reads/Writes specify how
many nodes
Replicates to Replicates to Keys = [A, B]
Node 4 Node 2
Token = D Token = B
Keys = [C, D] Replicates to Replicates to
Node 3
Token = C
Keys = [B, C]](https://image.slidesharecdn.com/springone2gx2010-springnonrelationaldata-110808212043-phpapp01/75/Spring-one2gx2010-spring-nonrelational_data-28-2048.jpg)


![MongoDB Data Model
{
"name" : "Ajanta",
• BSON data types "type" : "Indian",
"serviceArea" : [
• Documents types "94619",
– Data "94618"
],
– Query "openingHours" : [
– Modifier for updates {
• Query and Modify "dayOfWeek" : Monday,
"open" : 1730,
operators "close" : 2130
– $tl, $gt, $ne, $in, $or, }
$elemMatch, $orderBy, ],
$group, "_id" :
ObjectId("4bddc2f49d1505567c
– $where + javascript
6220a0")
– $inc, $set, $push, $pull }](https://image.slidesharecdn.com/springone2gx2010-springnonrelationaldata-110808212043-phpapp01/75/Spring-one2gx2010-spring-nonrelational_data-31-2048.jpg)









![Spring Redis Examples
RedisClientFactory clientFactory = new JedisClientFactory();
RedisClient client = clientFactory.createClient();
client.sadd("s1", "1"); client.sadd("s1", "2");
client.sadd("s1", "3");
client.sadd("s2", "2"); client.sadd("s2", "3");
Set<String> intersection = client.sinter("s1", "s2");
System.out.println(intersection); // [3,2]
RedisTemplate redisTemplate = new RedisTemplate(client)
Person p = new Person("Joe", "Trader", 33);
redisTemplate.convertAndSet("trader:1", p);
p = redisTemplate.getAndConvert("trader:1", Person.class);
intersection =
redisTemplate.getSetOps().getIntersectionOfSets(“s1”,”s2”)
RedisSet s1 = new RedisSet(template, "s1");
s1.add("1"); s1.add("2"); s1.add("3");
RedisSet s2 = new RedisSet(template, "s2");
s2.add("2"); s2.add("3");
Set s3 = s1.intersection("s3", s1, s2); // [3,2]](https://image.slidesharecdn.com/springone2gx2010-springnonrelationaldata-110808212043-phpapp01/75/Spring-one2gx2010-spring-nonrelational_data-49-2048.jpg)










![Food to Go - MongoDB
{ {
"name" : "Ajanta", serviceArea:"94619",
"type" : "Indian", openingHours: {
"serviceArea" : [ $elemMatch : {
"94619", "dayOfWeek" : Monday,
"94618" "open": {$lte: 1800},
], "close": {$gte: 1800}
"openingHours" : [ }
{ }
"dayOfWeek" : Monday, }
"open" : 1730,
"close" : 2130
}
], Straightforward to model a
"_id" : restaurant aggregate as a MongoDB
ObjectId("4bddc2f49d1505567c document and execute queries
6220a0")
}](https://image.slidesharecdn.com/springone2gx2010-springnonrelationaldata-110808212043-phpapp01/75/Spring-one2gx2010-spring-nonrelational_data-71-2048.jpg)





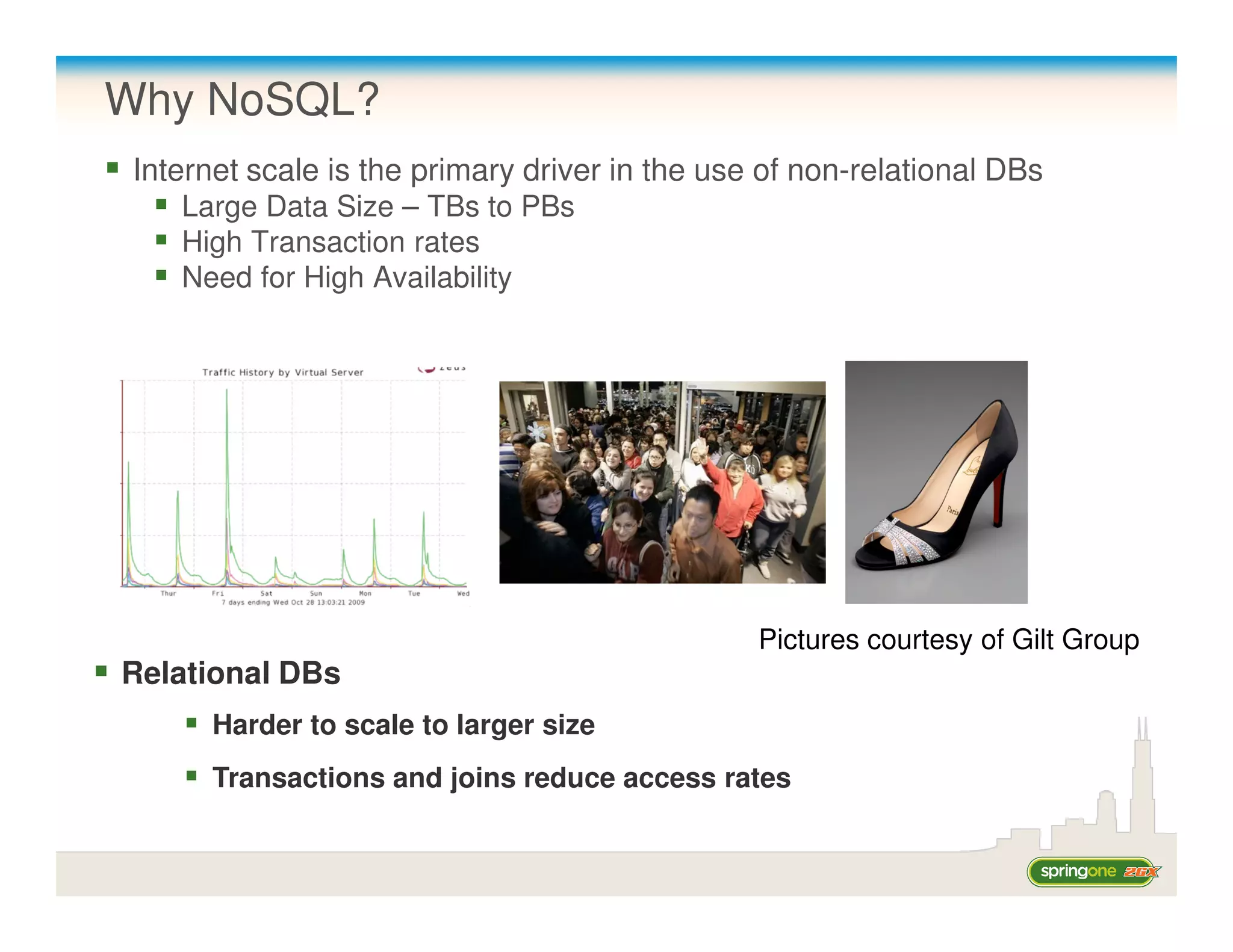
This document provides a summary of a talk on using Spring with NoSQL databases. The talk discusses the benefits and drawbacks of NoSQL databases, and how the Spring Data project simplifies development of NoSQL applications. It then provides background on the two speakers, Chris Richardson and Mark Pollack. The agenda outlines explaining why NoSQL, overviewing some NoSQL databases, discussing Spring NoSQL projects, and having demos and code examples.






































































































