





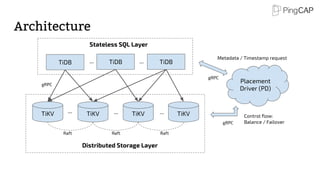
![RocksDB
Instance
Region 1:[a-e]
Region 3:[k-o]
Region 5:[u-z]
...
Region 4:[p-t]
RocksDB
Instance
Region 1:[a-e]
Region 2:[f-j]
Region 4:[p-t]
...
Region 3:[k-o]
RocksDB
Instance
Region 2:[f-j]
Region 5:[u-z]
Region 3:[k-o]
... RocksDB
Instance
Region 1:[a-e]
Region 2:[f-j]
Region 5:[u-z]
...
Region 4:[p-t]
Raft group
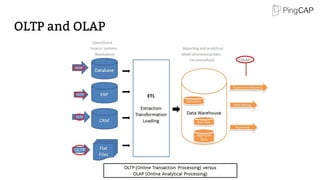
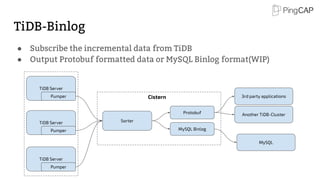
Storage stack 2/2
● Data is organized by Regions
● Region: a set of continuous key-value pairs
RPC (gRPC)
Transaction
MVCC
Raft
RocksDB
···](https://image.slidesharecdn.com/bigdataintidb1-171110051658/85/TiDB-for-Big-Data-9-320.jpg)
![Dynamic Multi-Raft
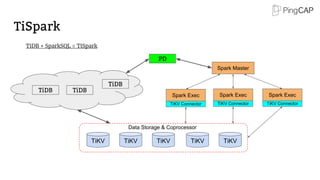
● What’s Dynamic Multi-Raft?
○ Dynamic split / merge
● Safe split / merge
Region 1:[a-e]
split Region 1.1:[a-c]
Region 1.2:[d-e]split](https://image.slidesharecdn.com/bigdataintidb1-171110051658/85/TiDB-for-Big-Data-10-320.jpg)
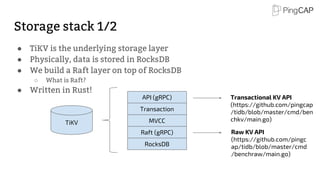
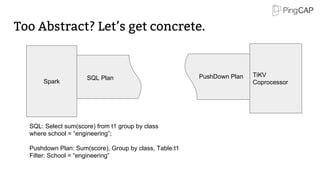
![Safe Split: 1/4
TiKV1
Region 1:[a-e]
TiKV2
Region 1:[a-e]
TiKV3
Region 1:[a-e]
raft raft
Leader Follower Follower
Raft group](https://image.slidesharecdn.com/bigdataintidb1-171110051658/85/TiDB-for-Big-Data-11-320.jpg)
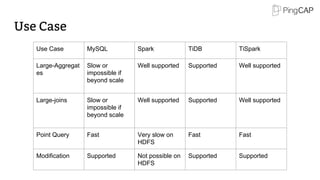
![Safe Split: 2/4
TiKV2
Region 1:[a-e]
TiKV3
Region 1:[a-e]
raft raft
Leader
Follower Follower
TiKV1
Region 1.1:[a-c]
Region 1.2:[d-e]](https://image.slidesharecdn.com/bigdataintidb1-171110051658/85/TiDB-for-Big-Data-12-320.jpg)
![Safe Split: 3/4
TiKV1
Region 1.1:[a-c]
Region 1.2:[d-e]
Leader
Follower Follower
Split log (replicated by Raft)
Split log
TiKV2
Region 1:[a-e]
TiKV3
Region 1:[a-e]](https://image.slidesharecdn.com/bigdataintidb1-171110051658/85/TiDB-for-Big-Data-13-320.jpg)
![Safe Split: 4/4
TiKV1
Region 1.1:[a-c]
Leader
Region 1.2:[d-e]
TiKV2
Region 1.1:[a-c]
Follower
Region 1.2:[d-e]
TiKV3
Region 1.1:[a-c]
Follower
Region 1.2:[d-e]
raft
raft
raft
raft](https://image.slidesharecdn.com/bigdataintidb1-171110051658/85/TiDB-for-Big-Data-14-320.jpg)
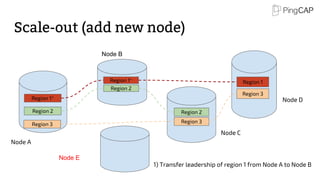
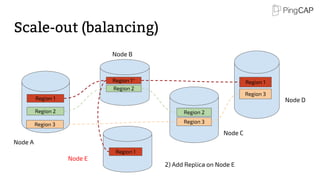
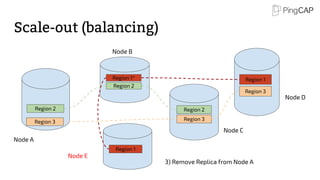


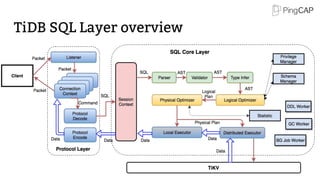

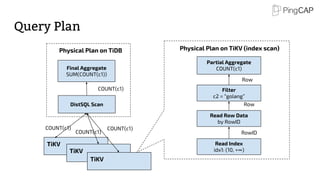

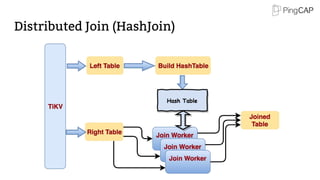

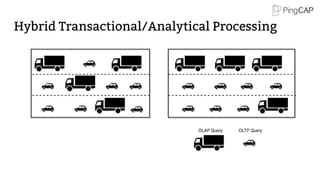

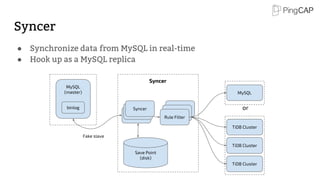







This document provides an overview of TiDB, a hybrid transactional and analytical processing (HTAP) database built to handle big data efficiently by integrating OLTP and OLAP capabilities. It details its architecture including the Tikv storage layer, the Raft consensus algorithm for data safety, and its SQL capabilities for distributed computing. The document also discusses integration with big data ecosystems and future improvements planned for TiDB.

































![Introducing TiDB [Delivered: 09/27/18 at NYC SQL Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/nycmysqlintroducingtidb-180928024621-thumbnail.jpg?width=640&height=640&fit=bounds)

![Introducing TiDB [Delivered: 09/25/18 at Portland Cloud Native Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/portlandk8smeetupintroducingtidb-180926052719-thumbnail.jpg?width=640&height=640&fit=bounds)









![Introducing TiDB Operator [Cologne, Germany]](https://cdn.slidesharecdn.com/ss_thumbnails/colognek8smeetupintroducingtidboperator-190222180135-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Paper Reading] Efficient Query Processing with Optimistically Compressed Has...](https://cdn.slidesharecdn.com/ss_thumbnails/icde-2020-220209161641-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading]Orca: A Modular Query Optimizer Architecture for Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/orca-211220090600-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading]KVSSD: Close integration of LSM trees and flash translation la...](https://cdn.slidesharecdn.com/ss_thumbnails/kvssdcloseintegrationoflsmtreesandflashtranslationlayerforwrite-efficientkvstore-211206083654-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading]Chucky: A Succinct Cuckoo Filter for LSM-Tree](https://cdn.slidesharecdn.com/ss_thumbnails/chuckyasuccinctcuckoofilterforlsm-tree-211122111631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading]The Bw-Tree: A B-tree for New Hardware Platforms](https://cdn.slidesharecdn.com/ss_thumbnails/thebw-treeab-treefornewhardwareplatforms-211115032950-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] QAGen: Generating query-aware test databases](https://cdn.slidesharecdn.com/ss_thumbnails/datagenerator-211105075703-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] Leases: An Efficient Fault-Tolerant Mechanism for Distribute...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadingleases-211101103843-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper reading] Interleaving with Coroutines: A Practical Approach for Robust...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadinginterleavingwithcoroutinesapracticalapproachforrobustindexjoin-211011055753-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paperreading] Paxos made easy (by sen han)](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadingpaxosmadeeasybysenhan-210926142716-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] Generalized Sub-Query Fusion for Eliminating Redundant I/O fr...](https://cdn.slidesharecdn.com/ss_thumbnails/resin-210920113222-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] Steering Query Optimizers: A Practical Take on Big Data Workl...](https://cdn.slidesharecdn.com/ss_thumbnails/steersigmod21-210913065908-thumbnail.jpg?width=640&height=640&fit=bounds)



























![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)
