Downloaded 15 times








































![MongoDB Example
> // map function > // reduce function
> m = function(){ > r = function( key , values ){
... this.tags.forEach( ... var total = 0;
... function(z){ ... for ( var i=0; i<values.length; i++ )
... emit( z , { count : 1 } ... total += values[i].count;
); ... return { count : total };
... } ...};
... );
...};
> // execute
> res = db.things.mapReduce(m, r, { out : "myoutput" } );](https://image.slidesharecdn.com/demsak-bigdata-njsql-120515153750-phpapp01/85/Big-Data-NJ-SQL-Server-User-Group-43-320.jpg)





![HADOOP
[Azure and Enterprise]
Java OM Streaming OM HiveQL PigLatin .NET/C#/F# (T)SQL
OCEAN OF DATA
NOSQL [unstructured, semi-structured, structured] ETL
HDFS
A SEAMLESS OCEAN OF INFORMATION PROCESSING AND ANALYTICs
EIS / RDBMS File OData Azure
ERP System [RSS] Storage](https://image.slidesharecdn.com/demsak-bigdata-njsql-120515153750-phpapp01/85/Big-Data-NJ-SQL-Server-User-Group-51-320.jpg)


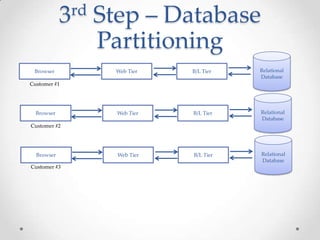
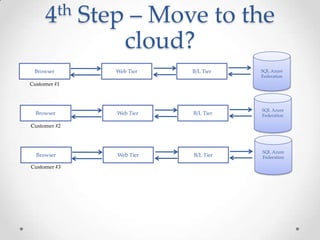
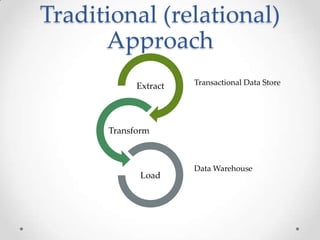
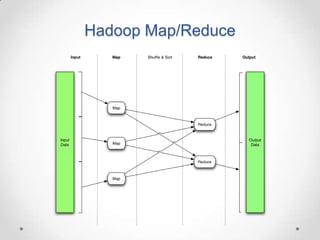
This document provides a summary of a presentation on Big Data and NoSQL databases. It introduces the presenters, Melissa Demsak and Don Demsak, and their backgrounds. It then discusses how data storage needs have changed with the rise of Big Data, including the problems created by large volumes of data. The presentation contrasts traditional relational database implementations with NoSQL data stores, identifying five categories of NoSQL data models: document, key-value, graph, and column family. It provides examples of databases that fall under each category. The presentation concludes with a comparison of real-world scenarios and which data storage solutions might be best suited to each scenario.



























![[Pulsar summit na 21] Change Data Capture To Data Lakes Using Apache Pulsar/Hudi](https://cdn.slidesharecdn.com/ss_thumbnails/pulsarsummitna21cdcusinghudipulsardeck-210628151056-thumbnail.jpg?width=640&height=640&fit=bounds)


































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




