Download as PDF, PPTX












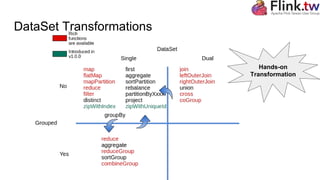





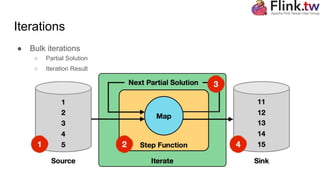
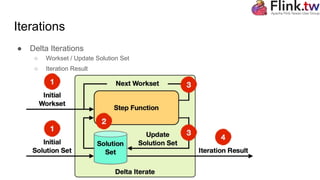


The document is a tutorial on Apache Flink, covering key concepts such as its type system, dataset transformations, and the basic structure of Flink programs. It details how to obtain an execution environment, load datasets, apply transformations, and manage accumulators and broadcast variables. Additionally, it discusses iterations and semantic annotations to optimize performance.


















































































