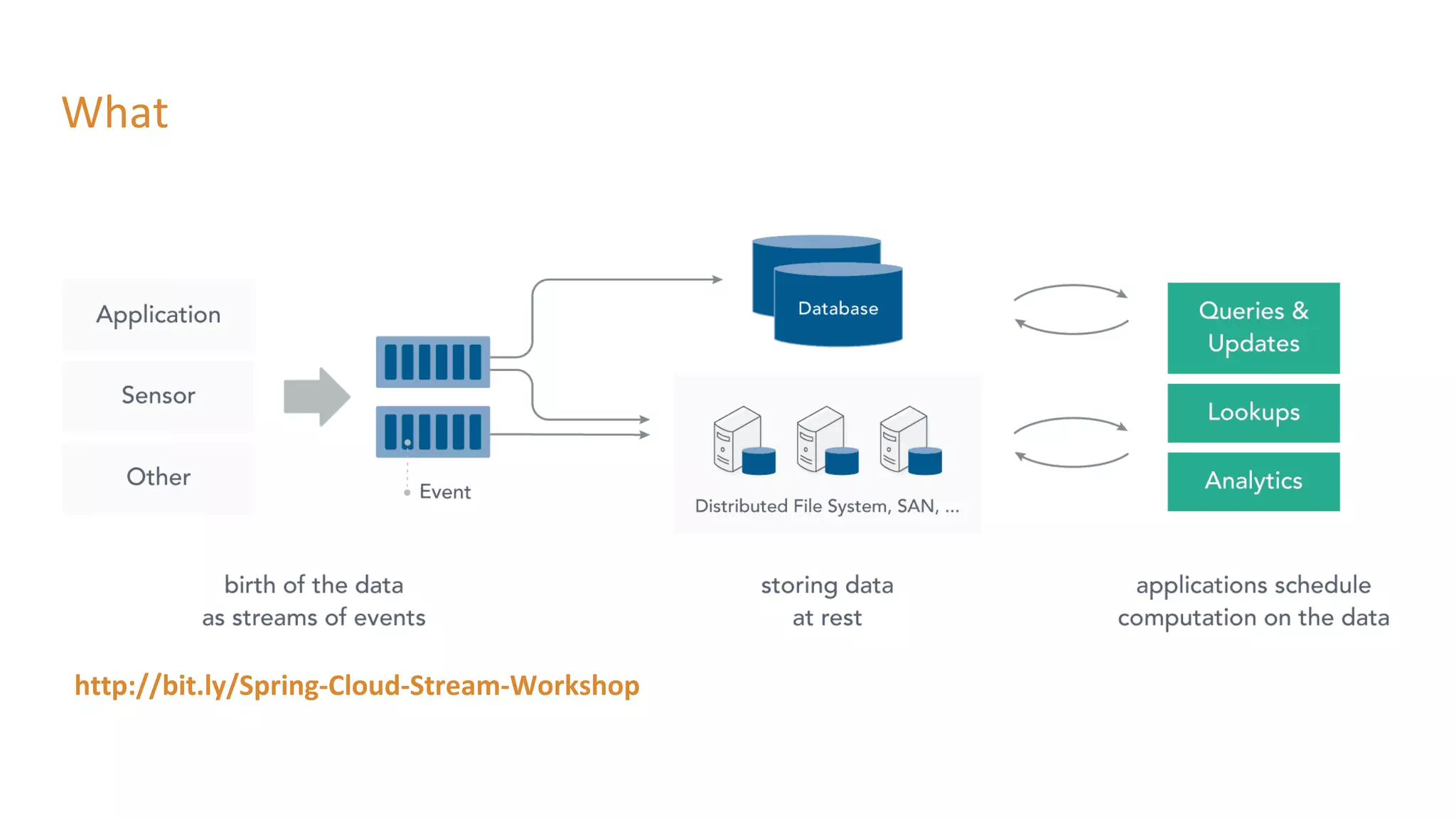
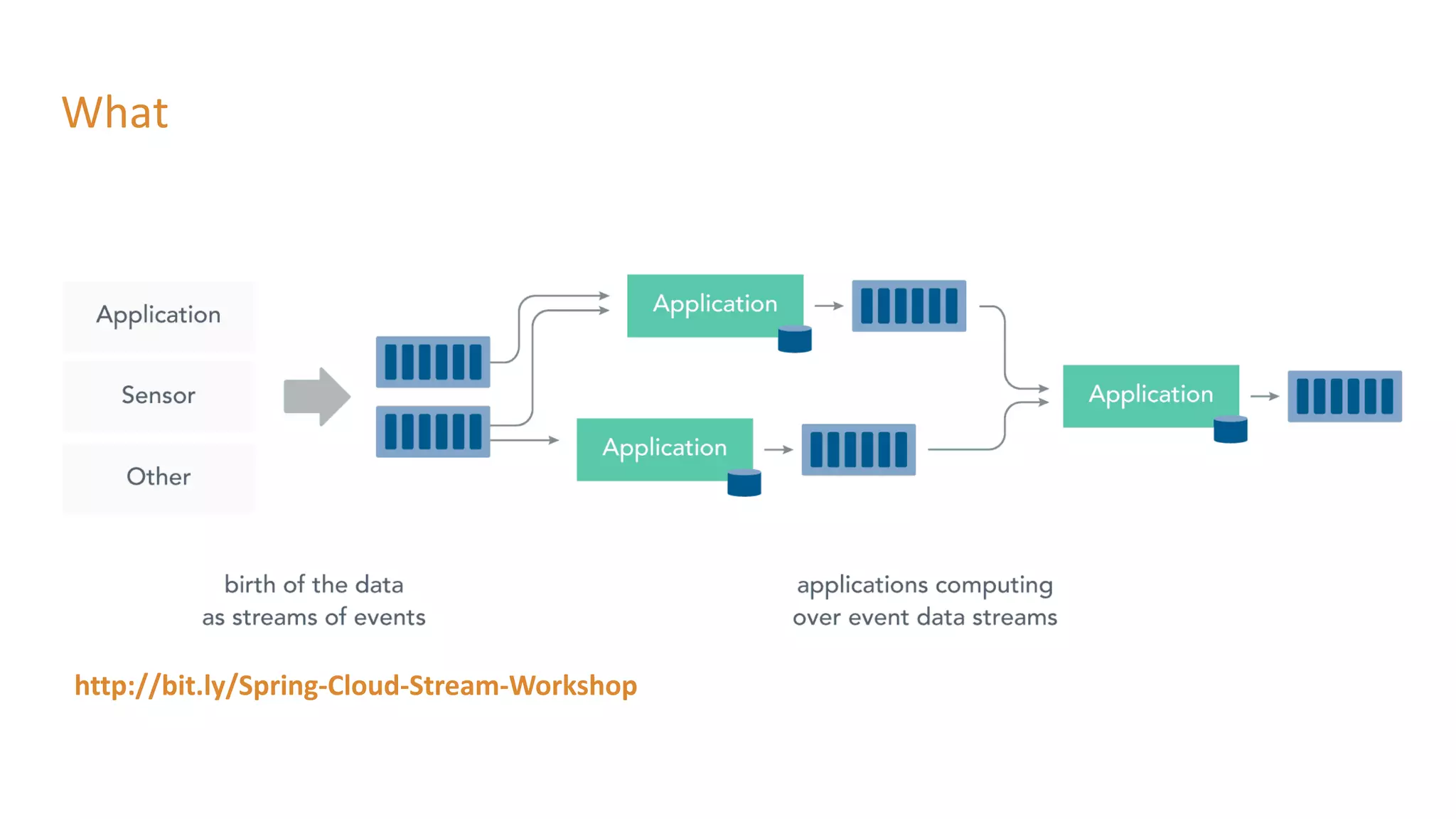
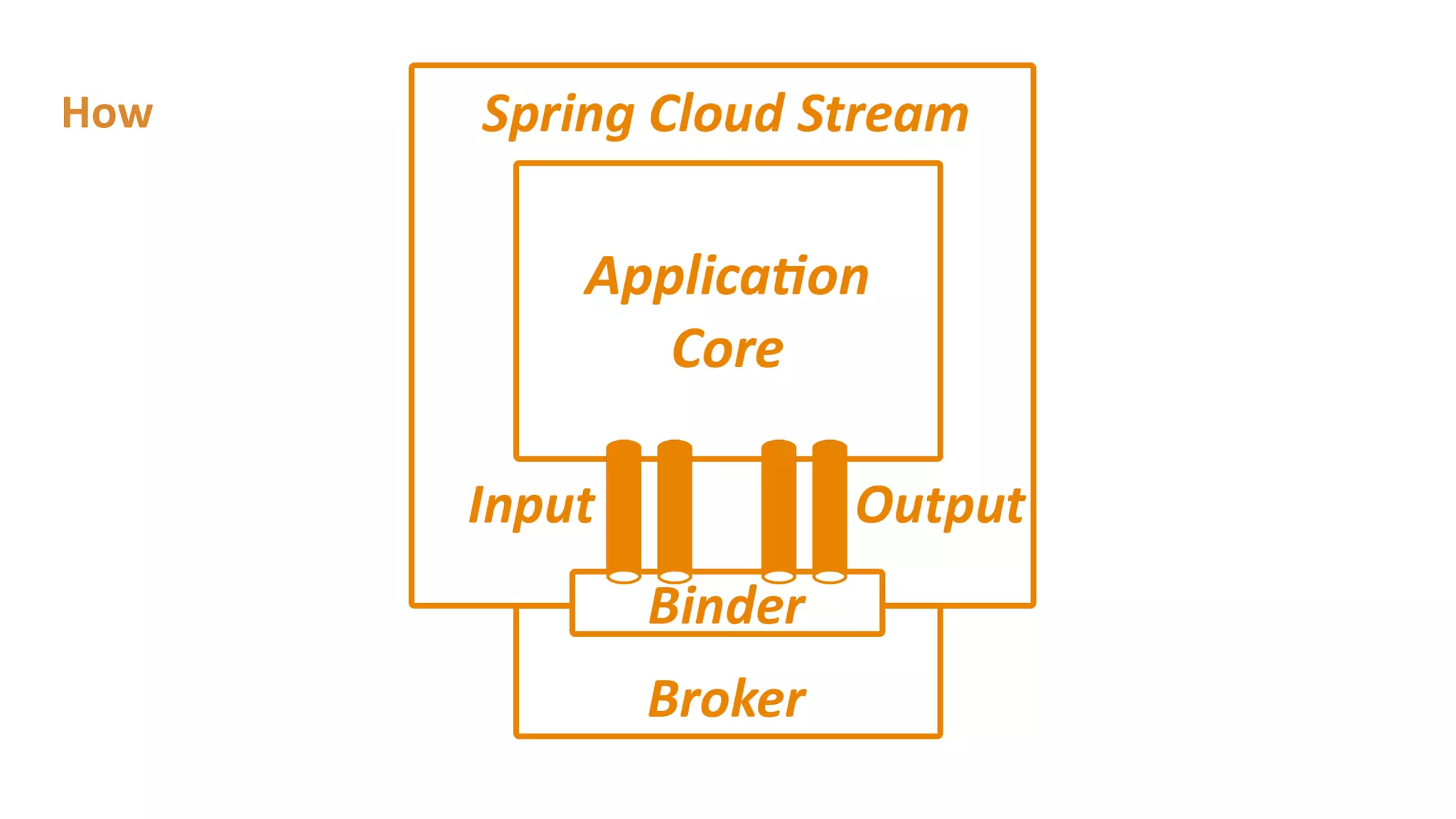
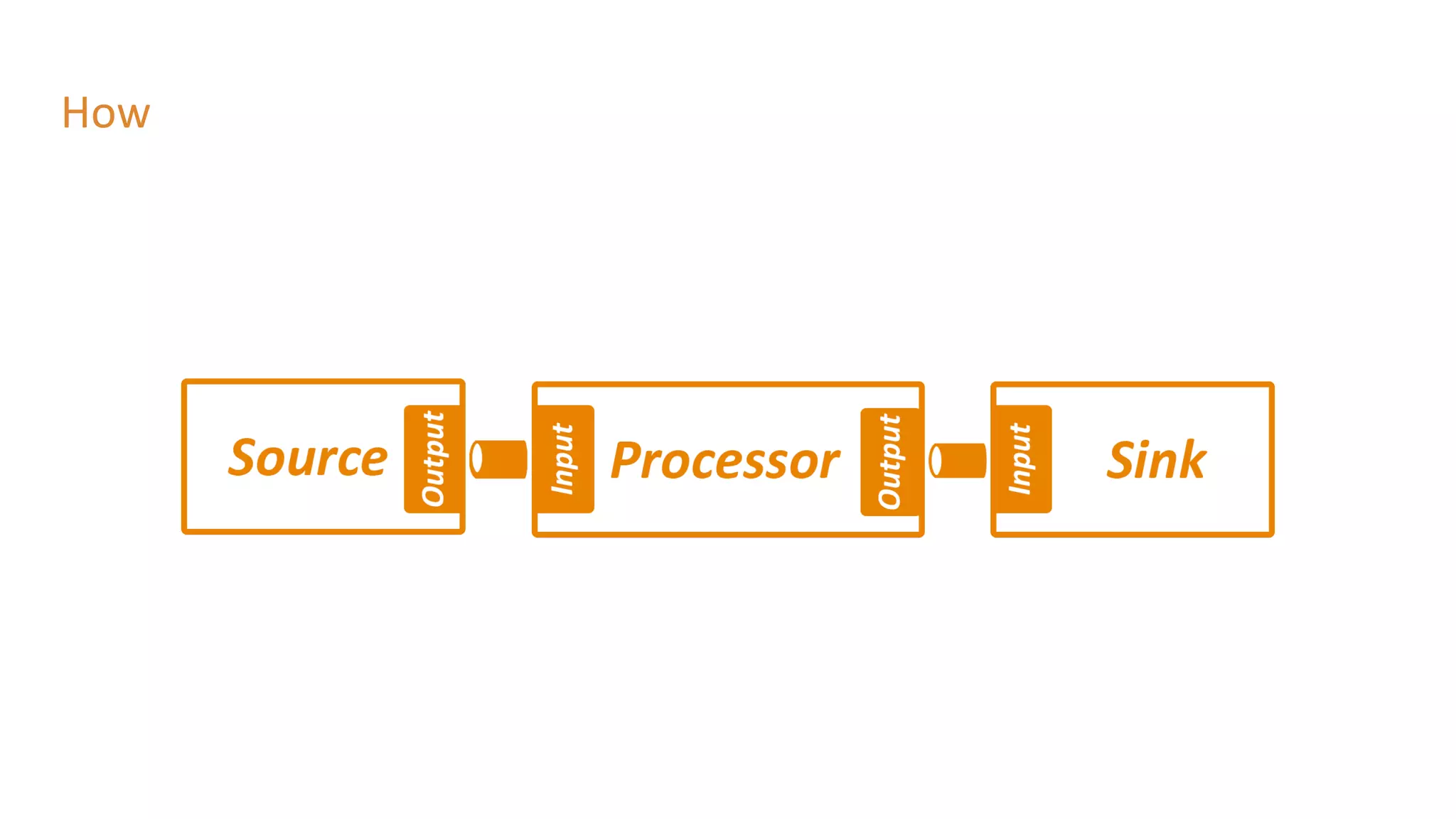
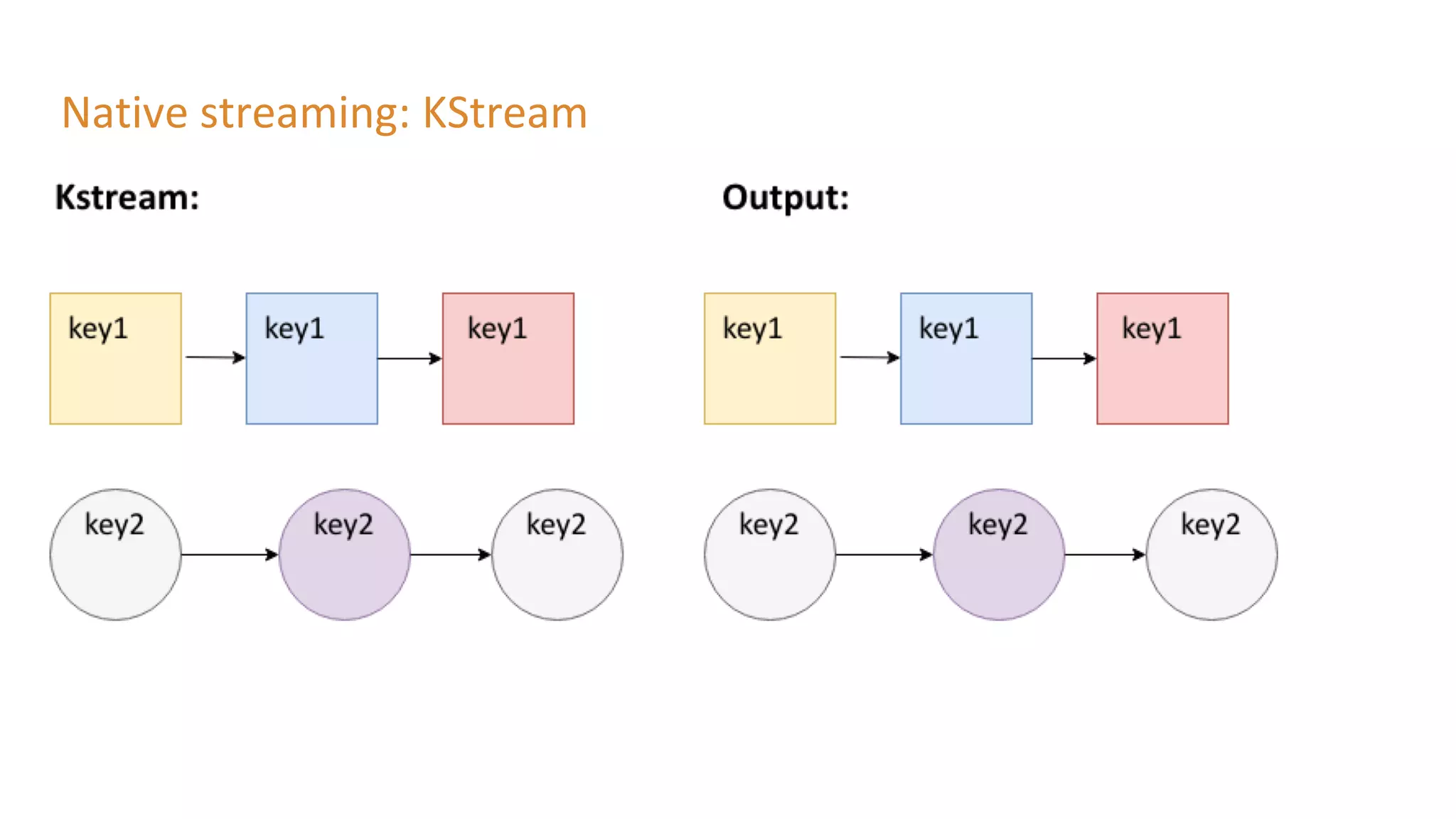
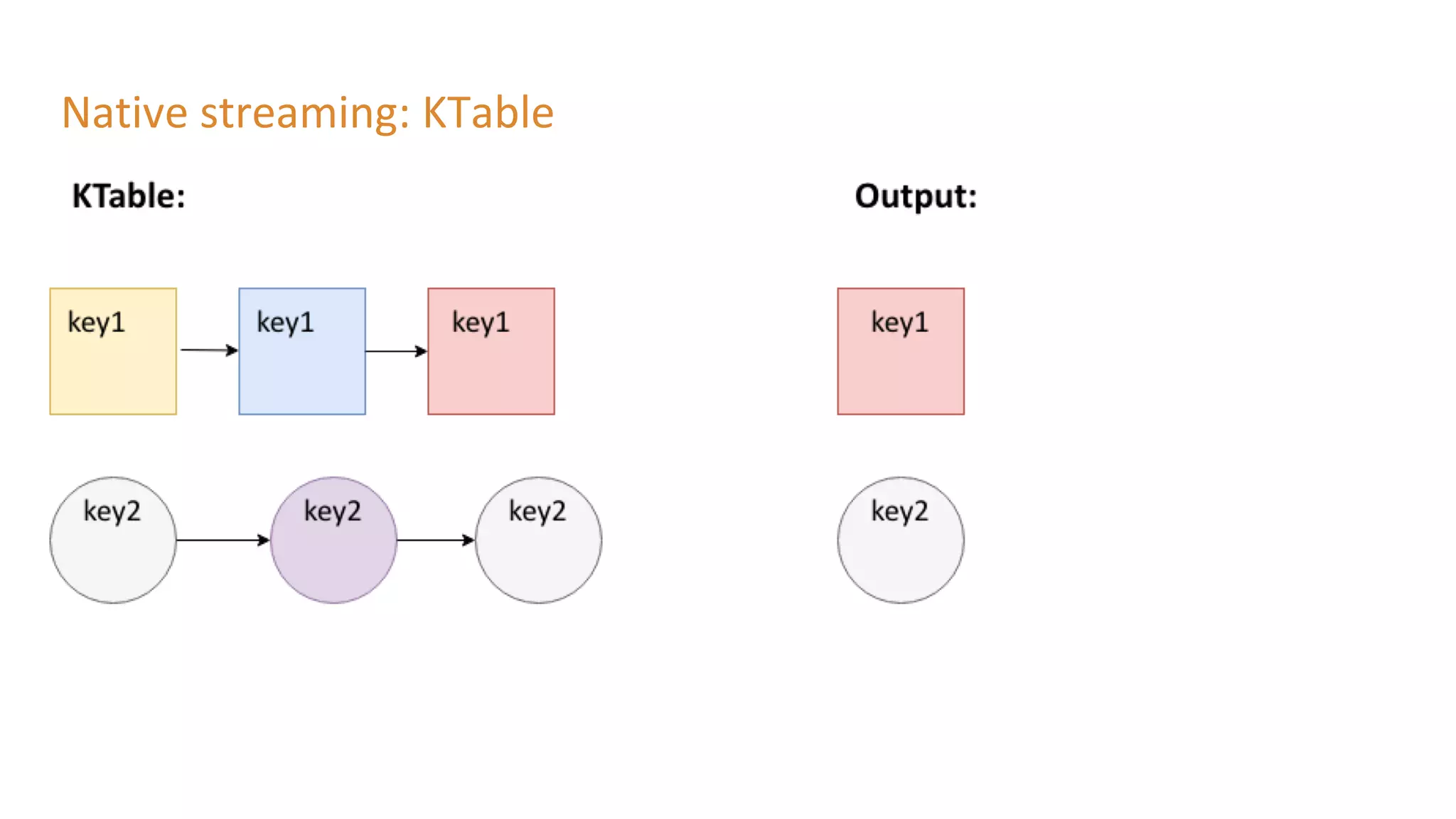
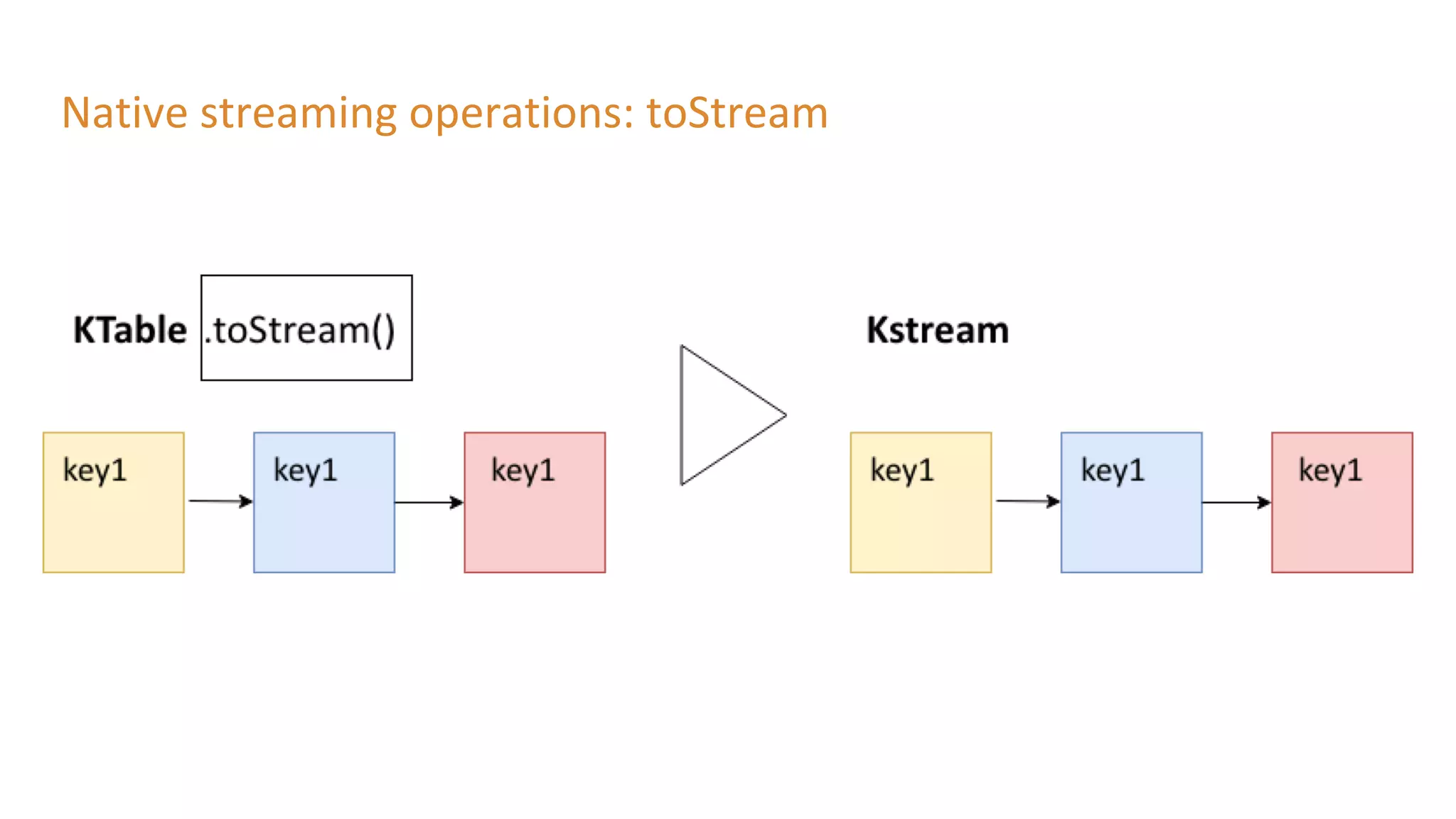
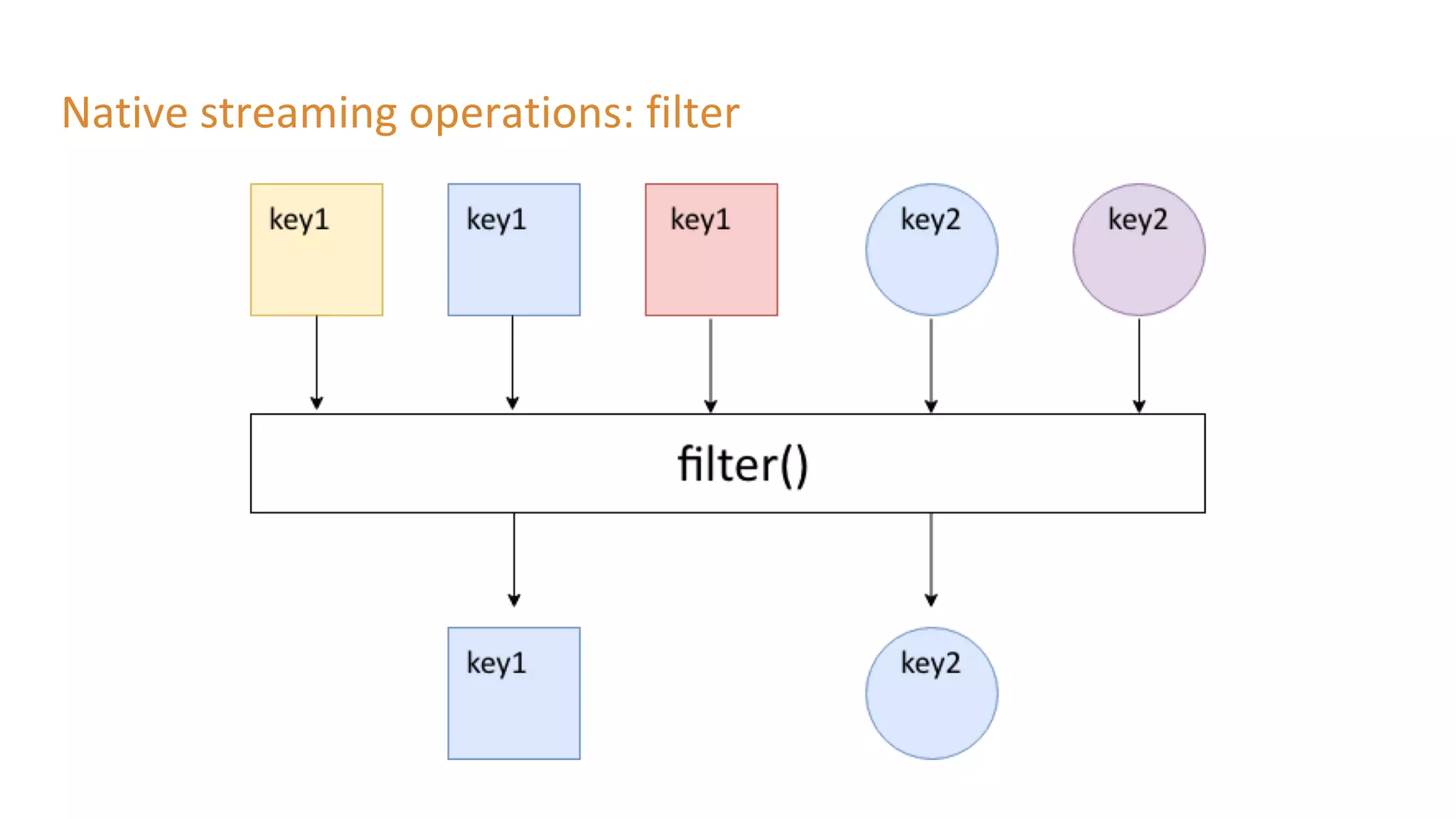
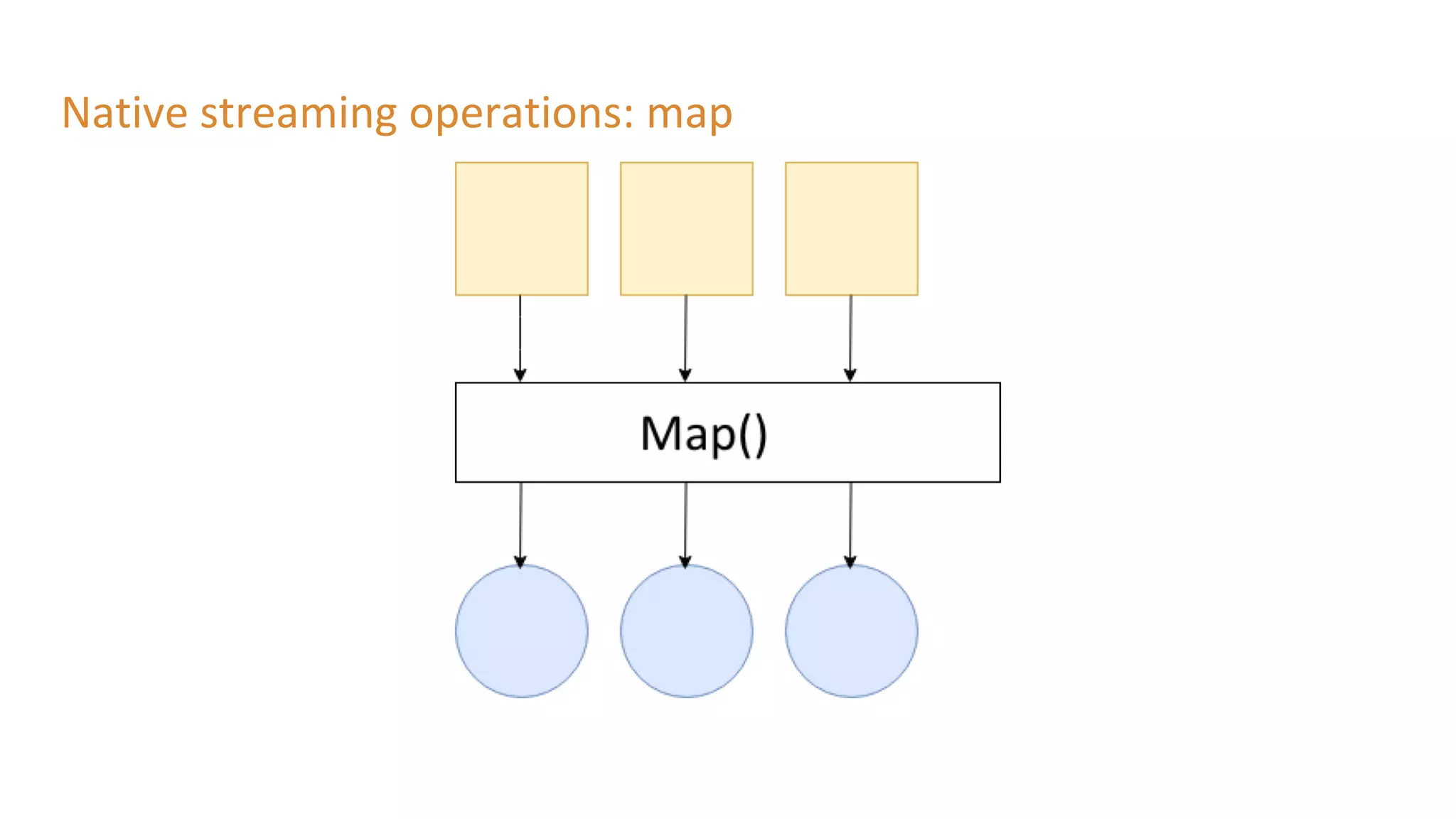
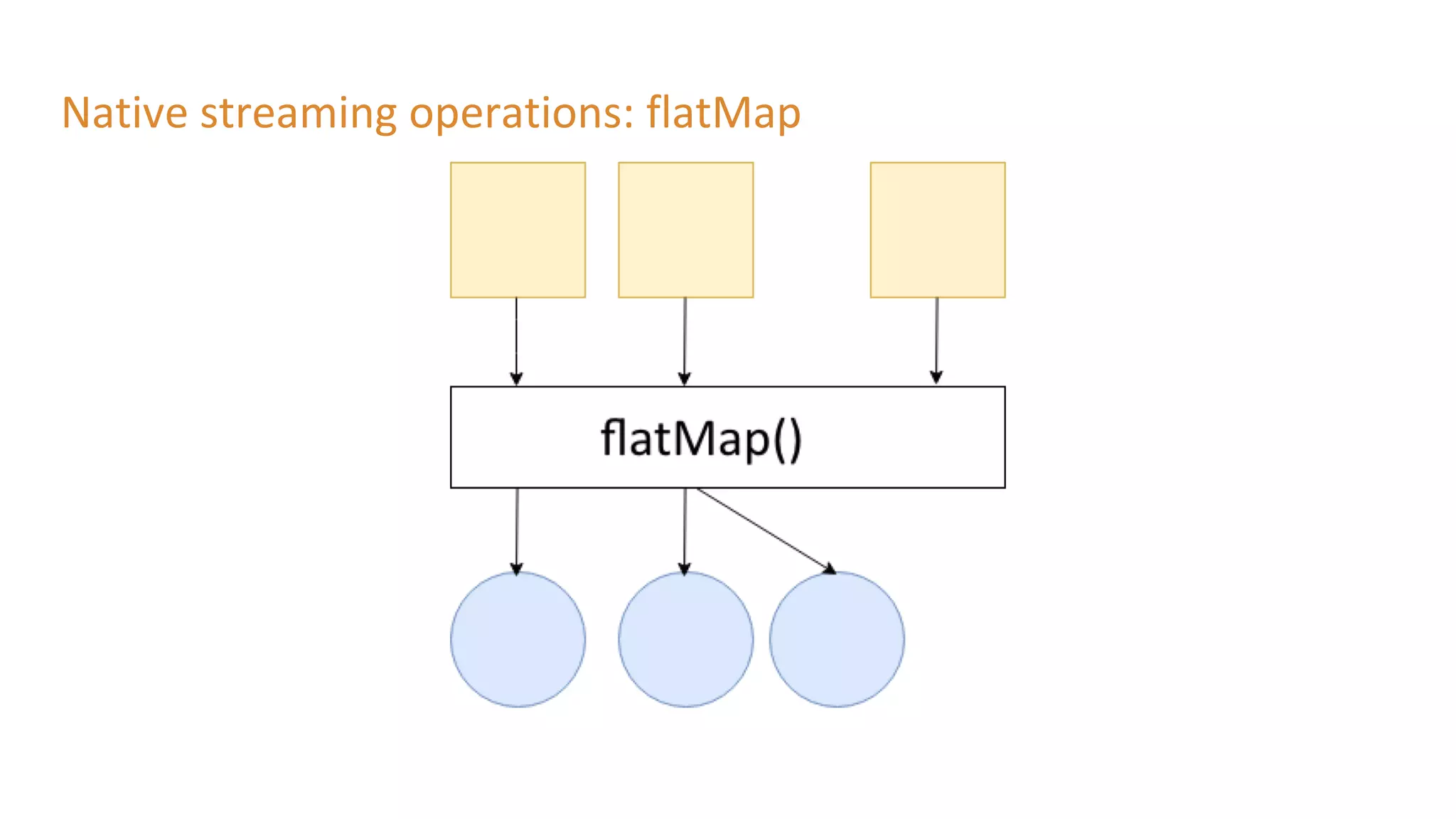
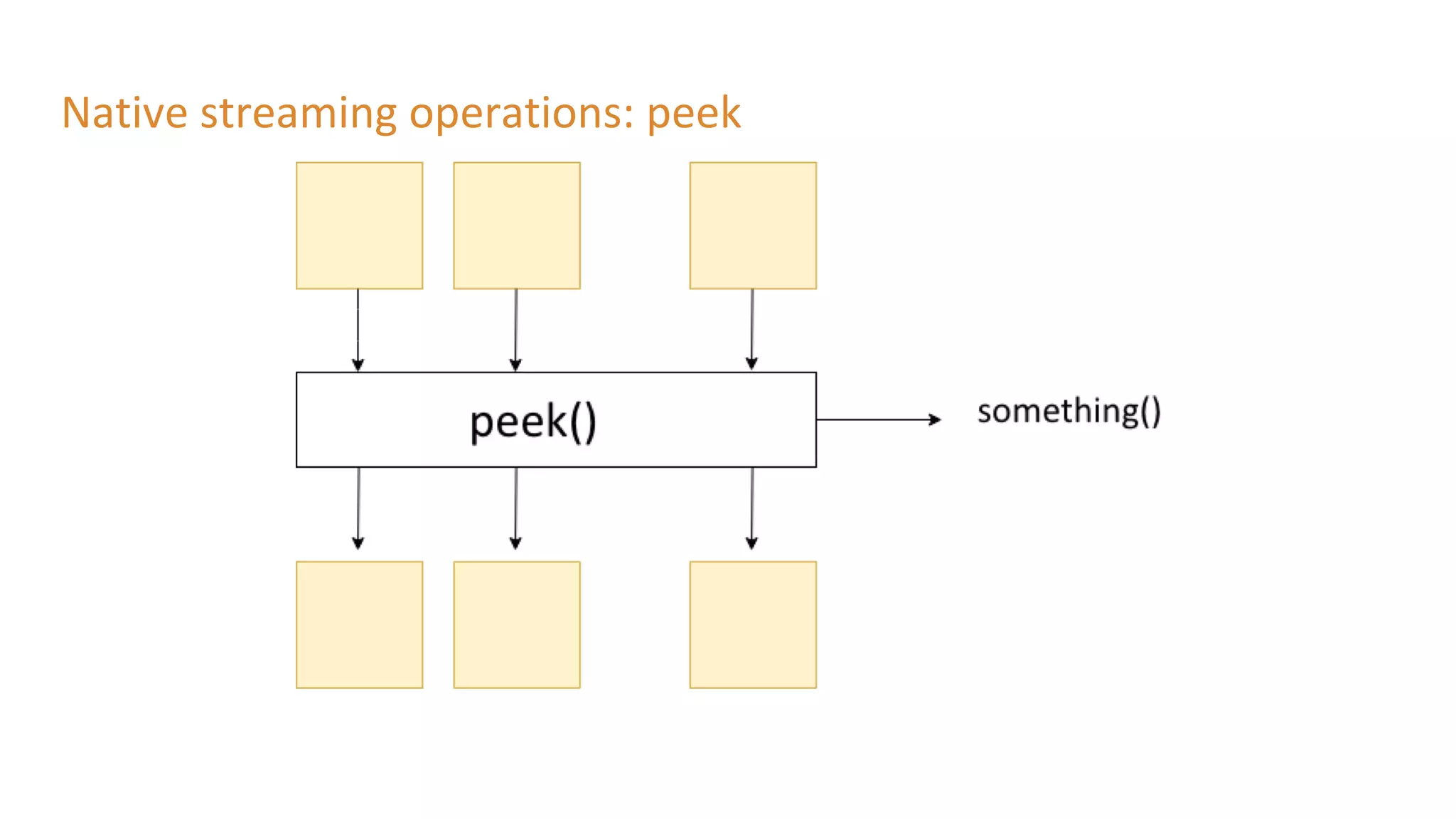
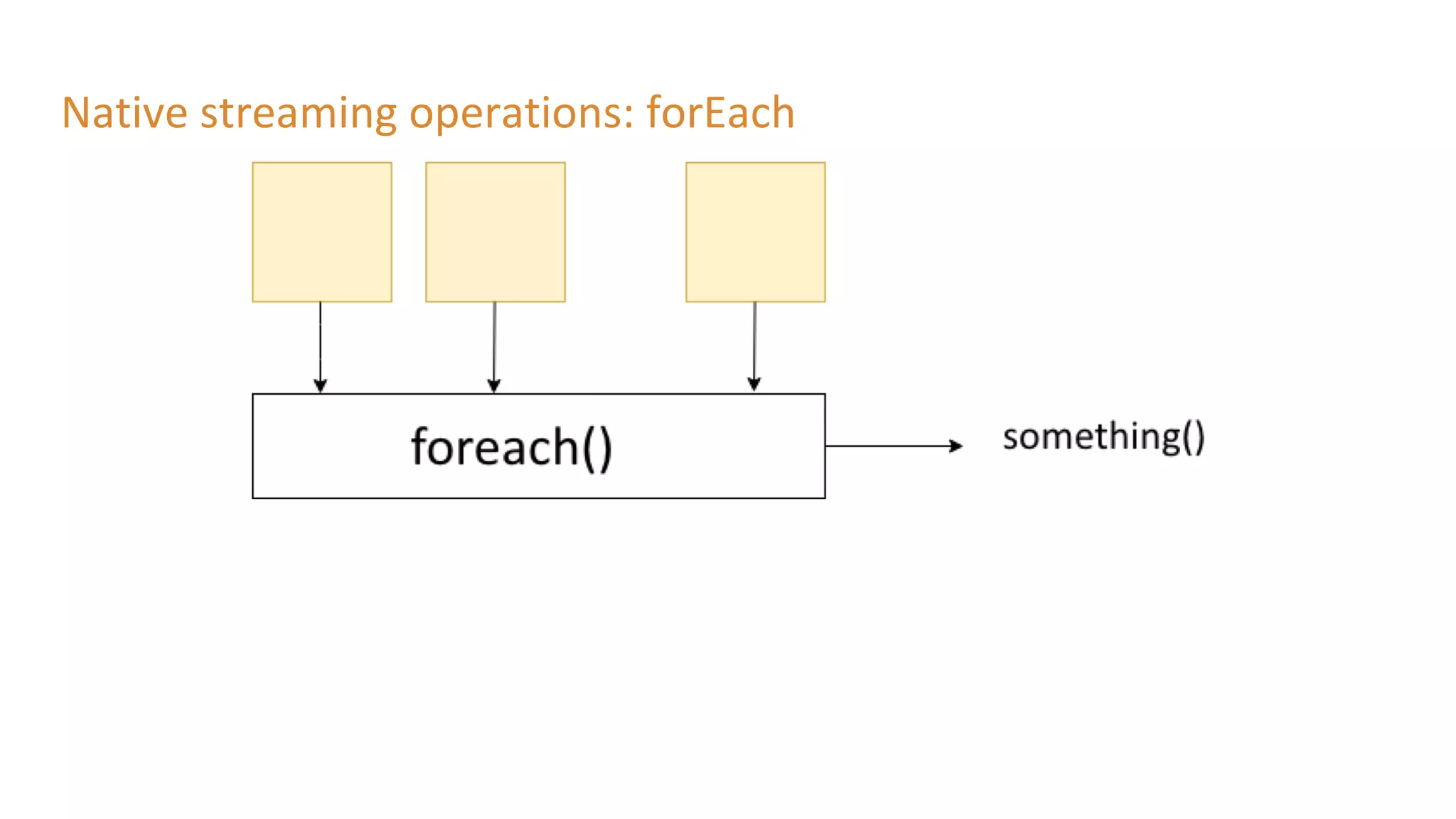
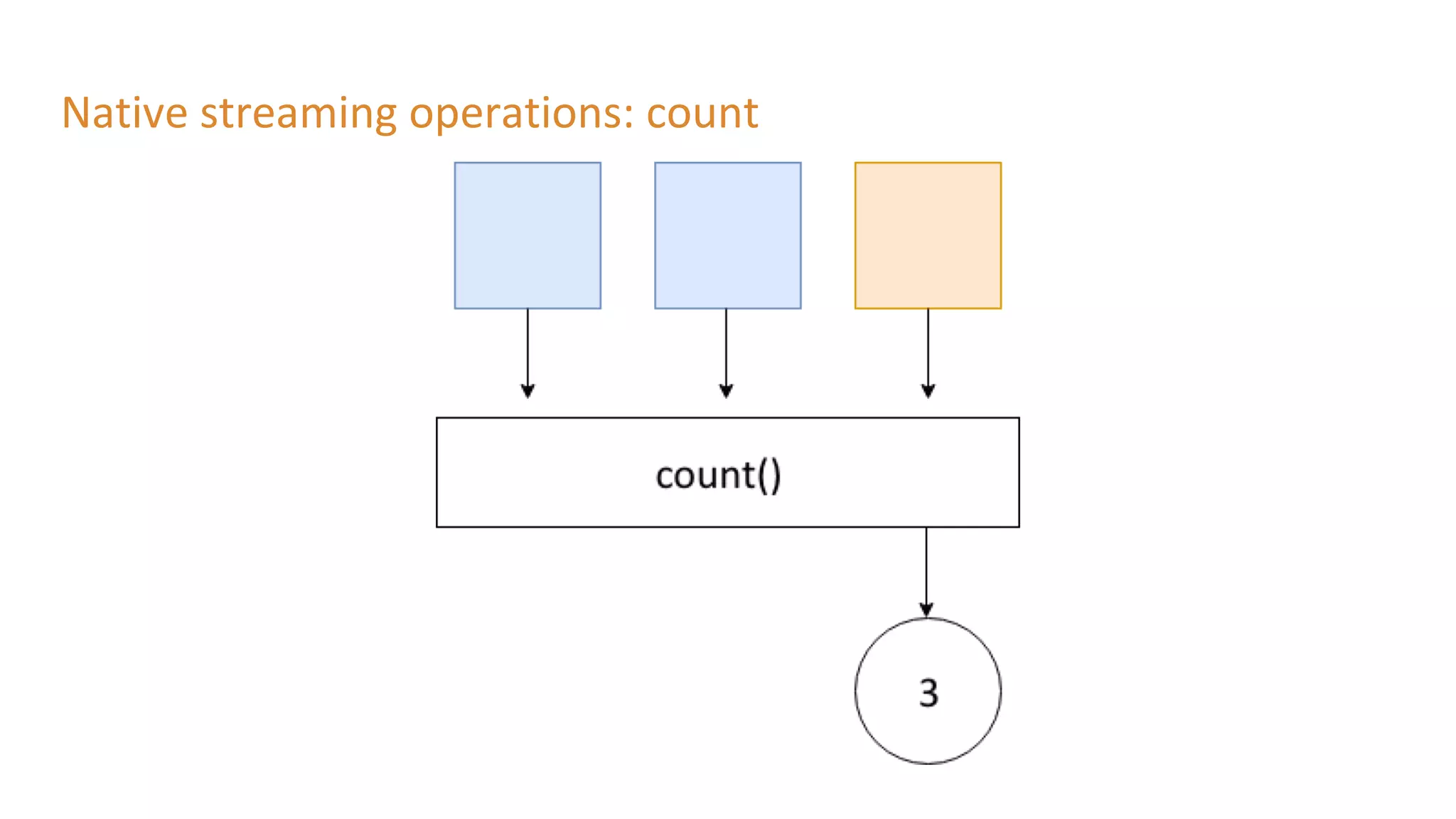
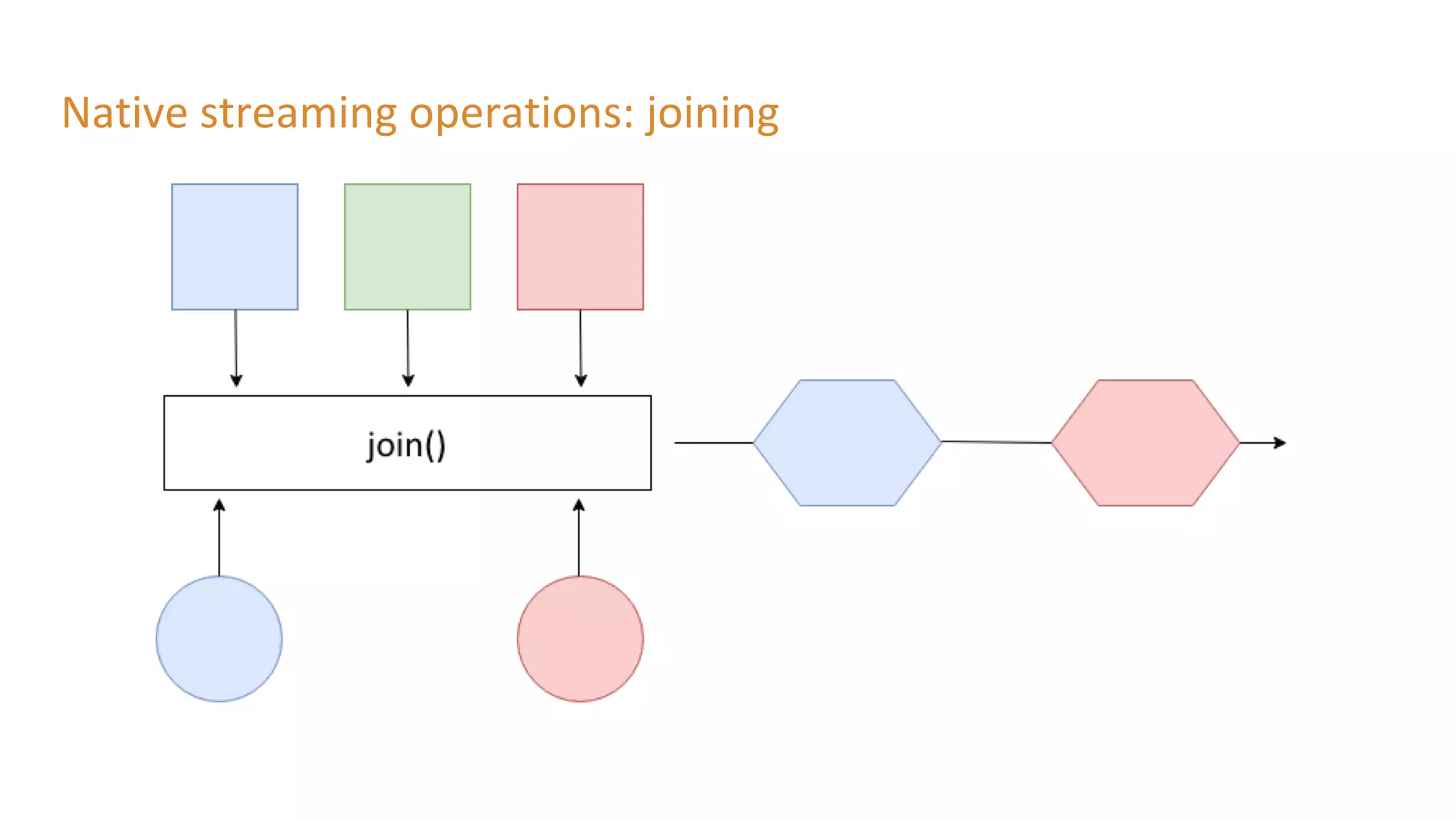
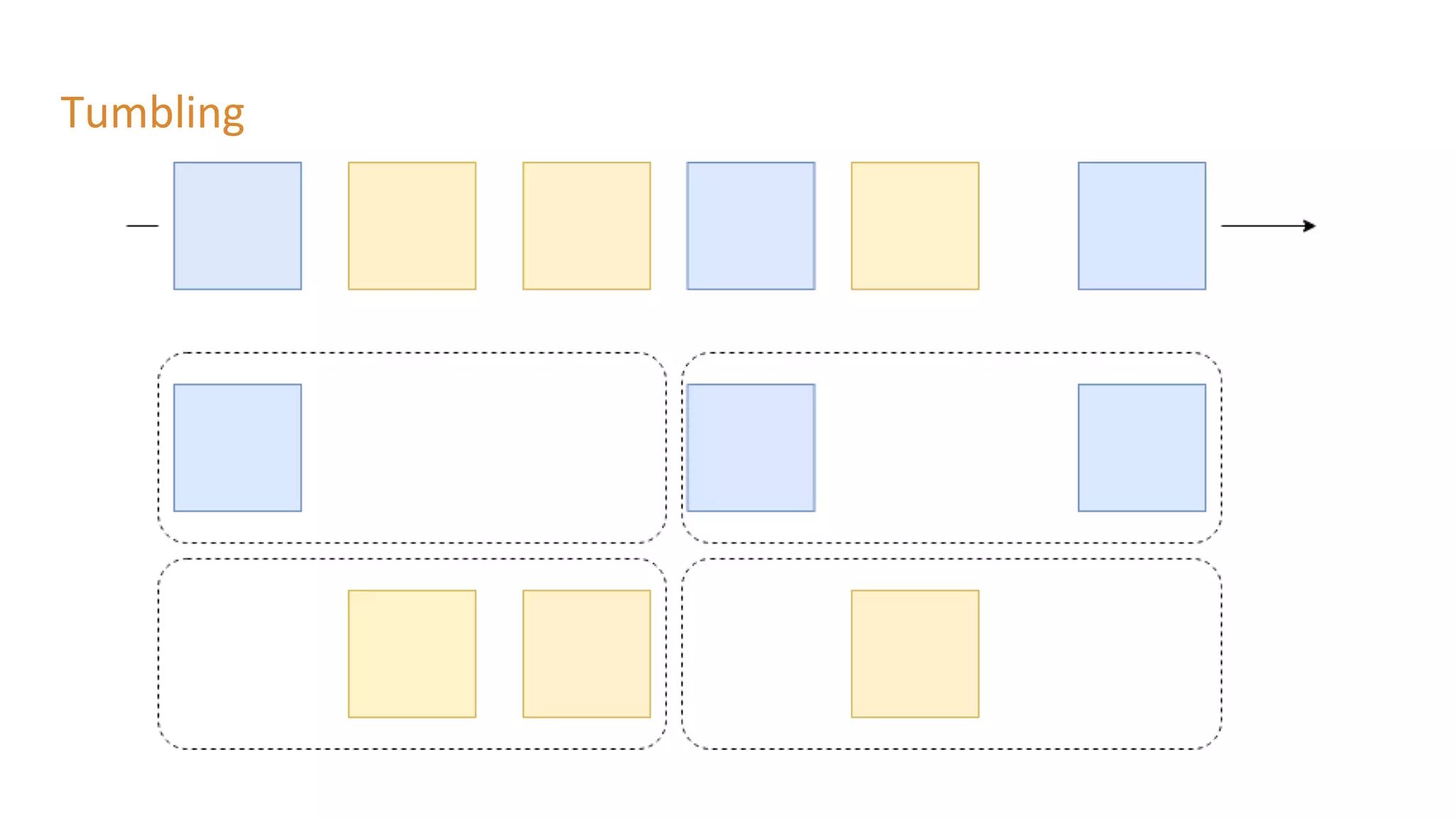
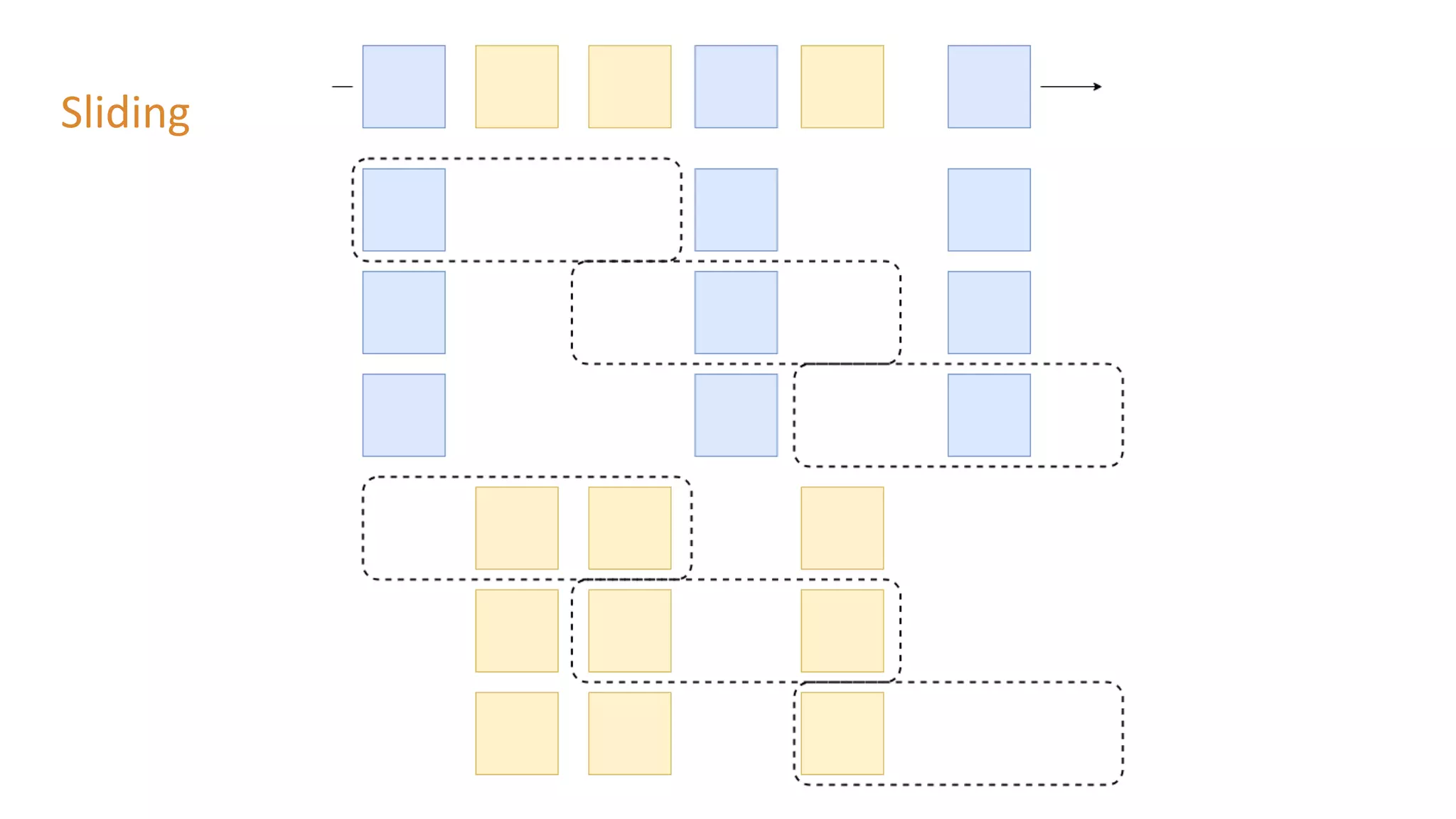
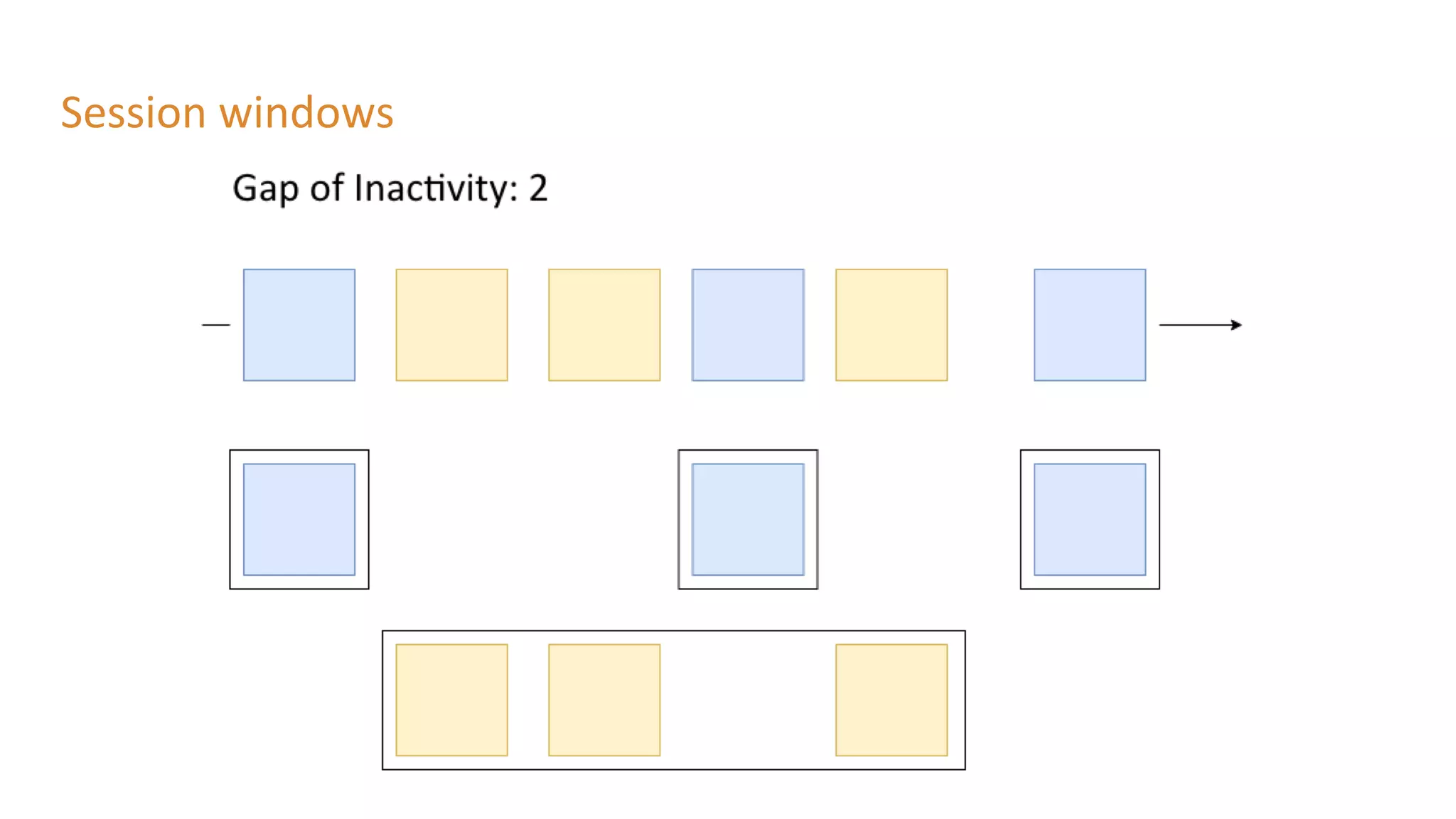
The document outlines a presentation on stream processing live traffic data using Kafka Streams, featuring speaker Tom Van Den Bulck and Tim Ysewyn. It discusses the setup environment, key concepts in streaming, types of traffic data represented in XML format, and outlines practical labs for sending and processing data with Kafka. Key topics include event-driven architecture, the importance of continuous processing, and various streaming operations such as filtering, mapping, and windowing.





































































![Building streaming data applications using Kafka*[Connect + Core + Streams] b...](https://cdn.slidesharecdn.com/ss_thumbnails/buildingstreamingdataapplicationsusingapachekafka-171011211455-thumbnail.jpg?width=640&height=640&fit=bounds)














![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















