Download as PDF, PPTX





![6
02 Scala Collection-like API
case class Word (word: String, count: Int)
val lines: DataSet[String] = env.readTextFile(...)
lines.flatMap(_.split(“ ”)). map(word => Word(word,1))
.groupBy(“word”).sum(“count”)
.print()
val lines: DataStream[String] = env.addSource(new KafkaSource(...))
lines.flatMap(_.split(“ ”)). map(word => Word(word,1))
.keyBy(“word”).timeWindow(Time.seconds(5)).sum(“count”)
.print()
DataSet API
DataStream API](https://image.slidesharecdn.com/hadoopcon2016-session1-160909155319/75/Apache-Flink-Training-Workshop-HadoopCon2016-1-System-Overview-7-2048.jpg)

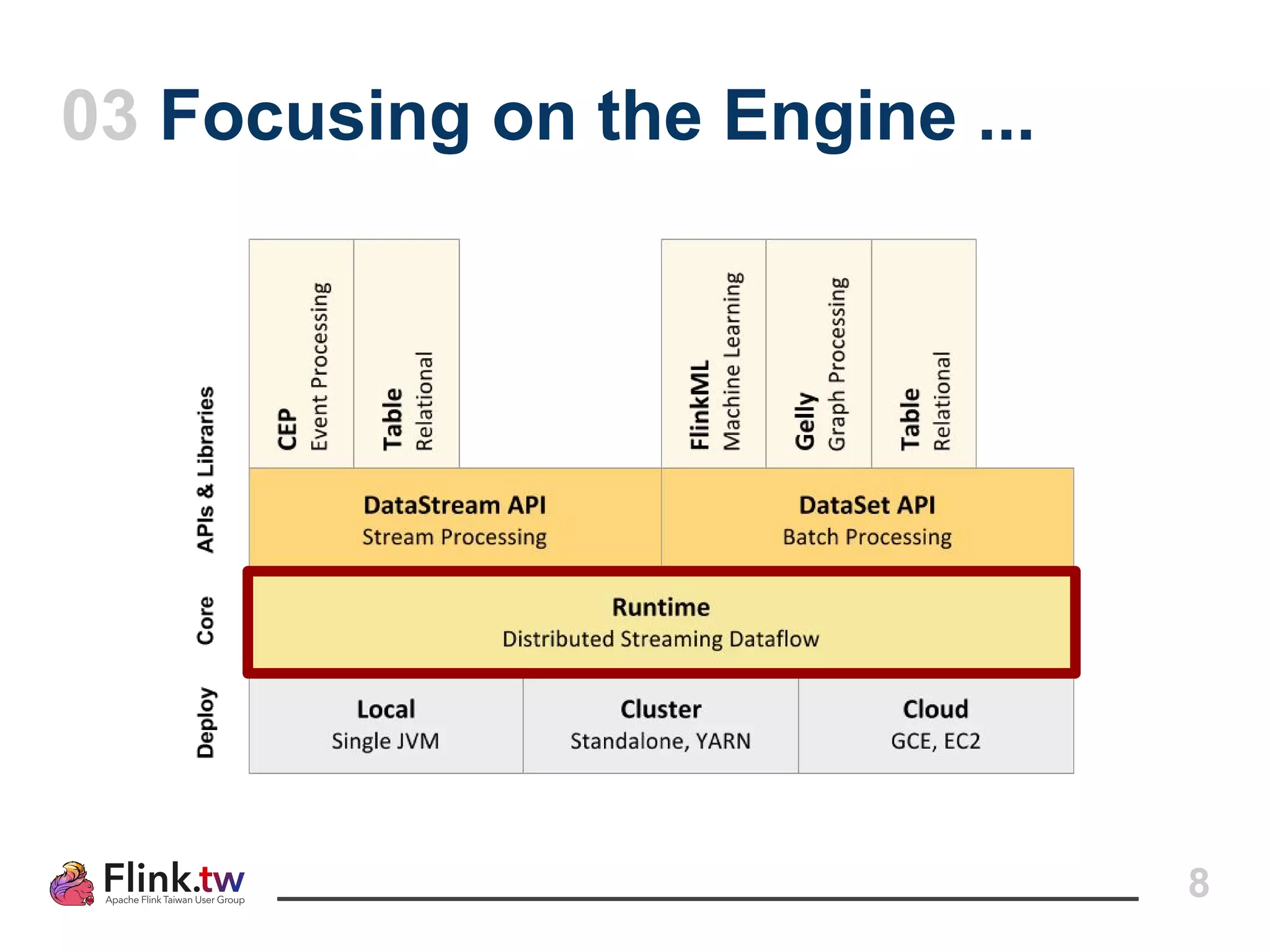

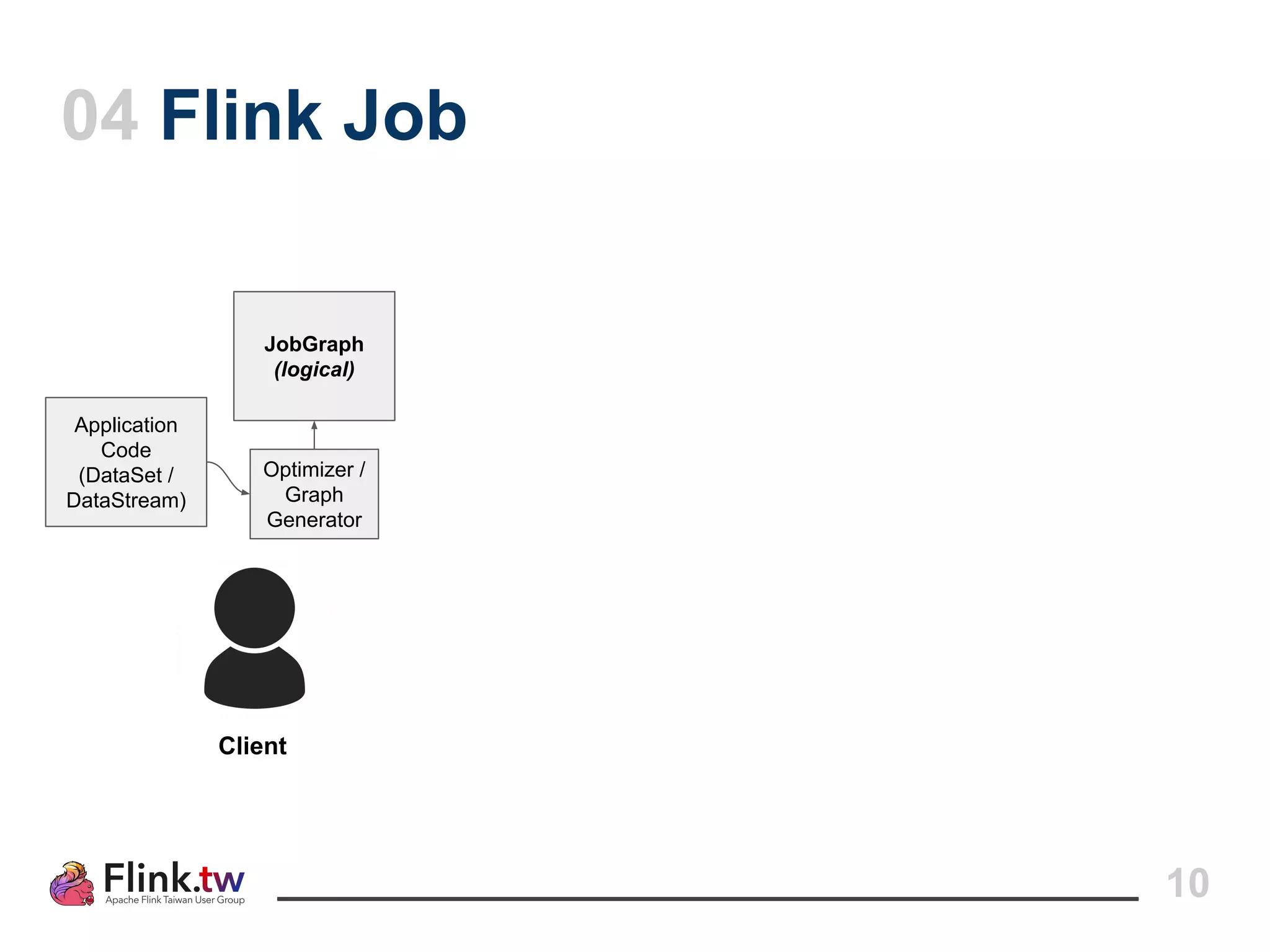
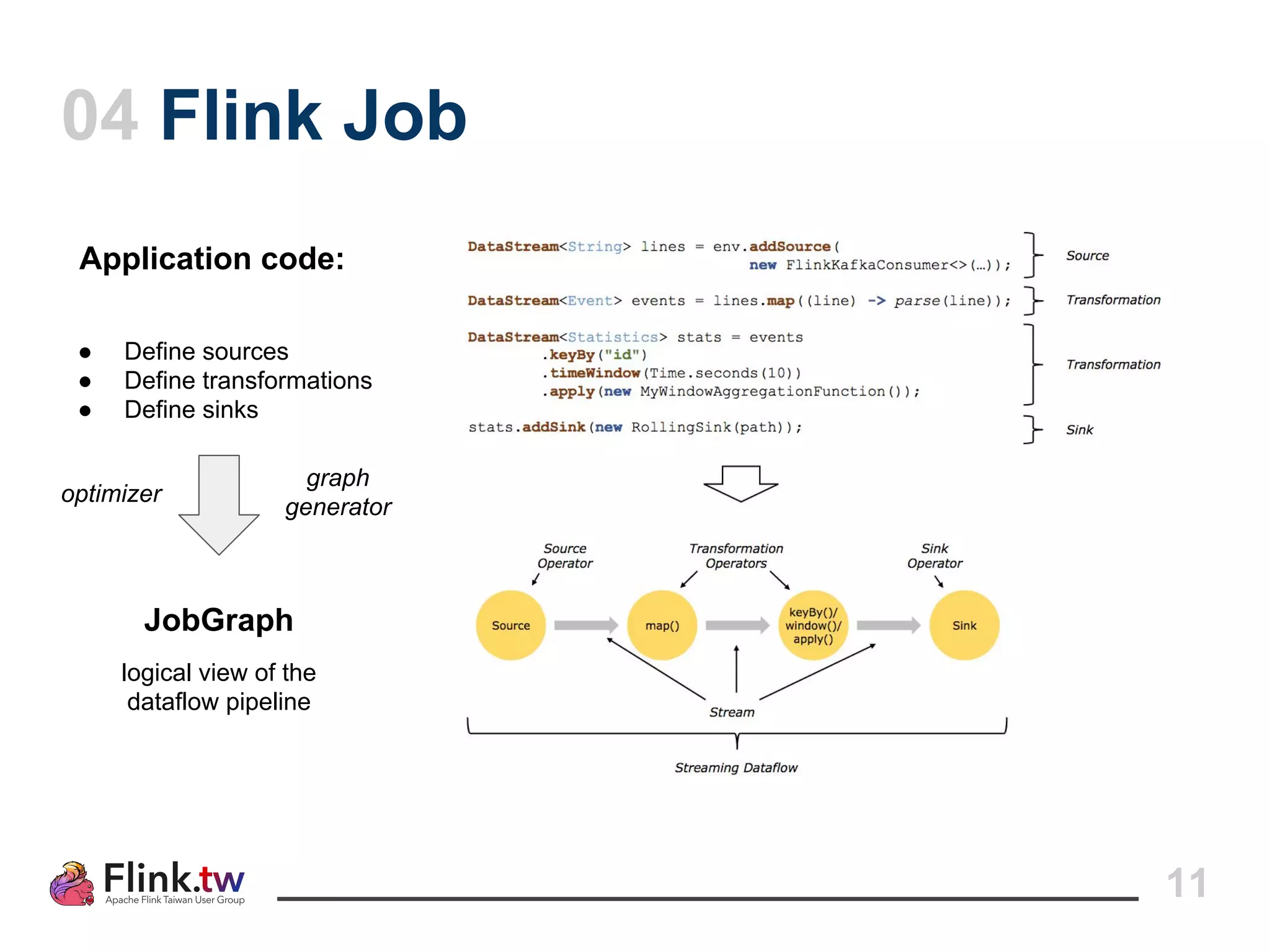
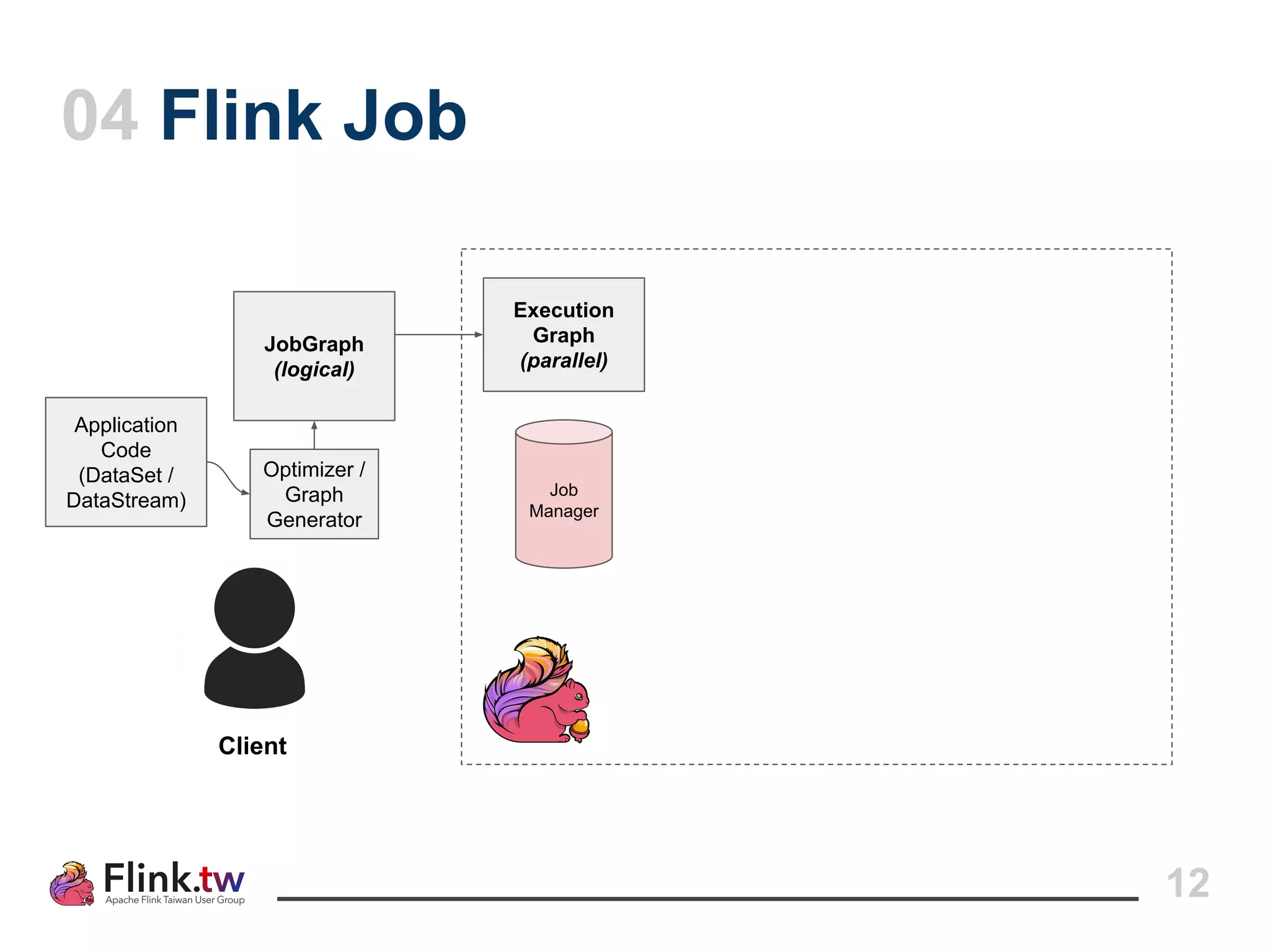
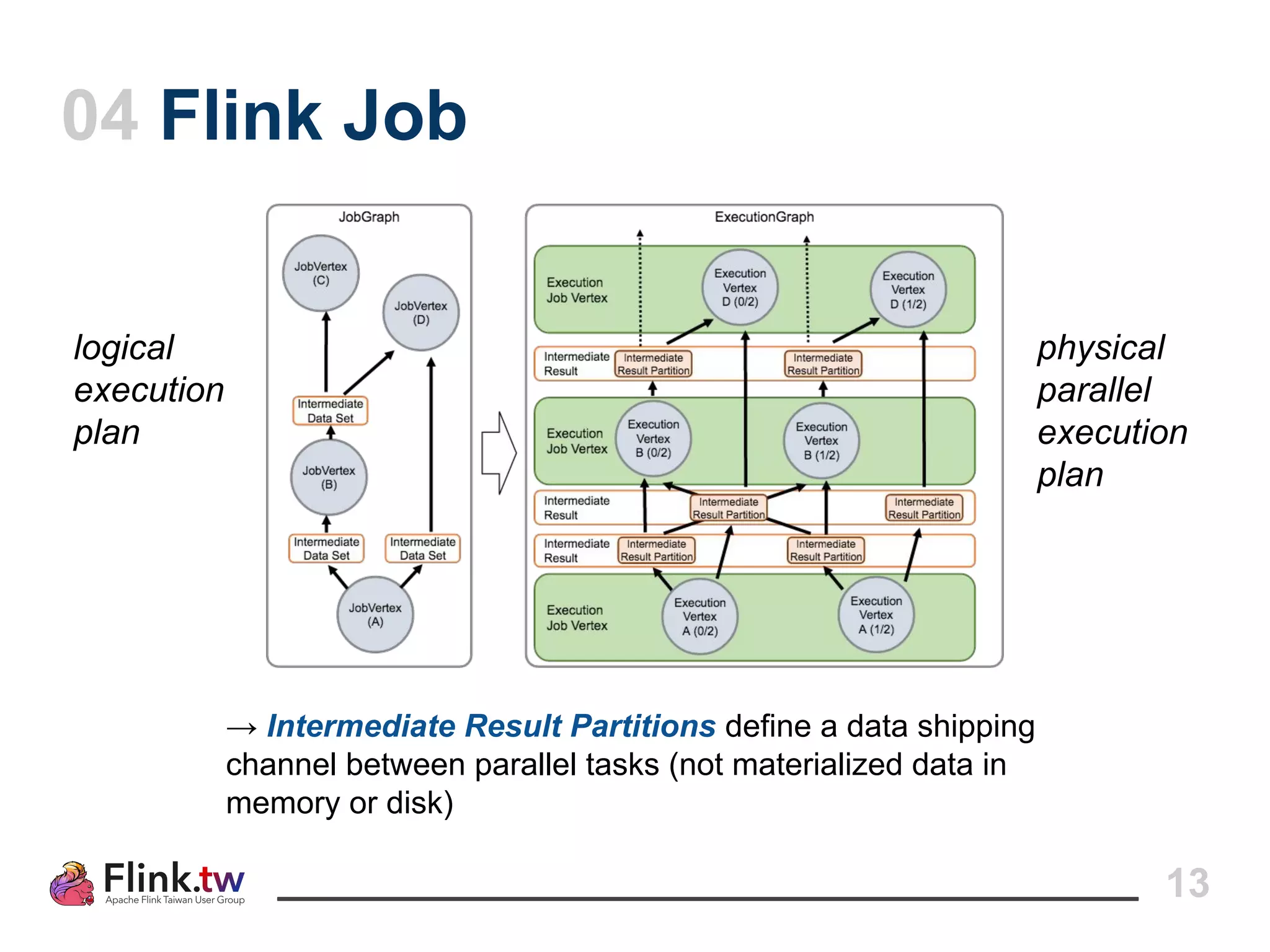
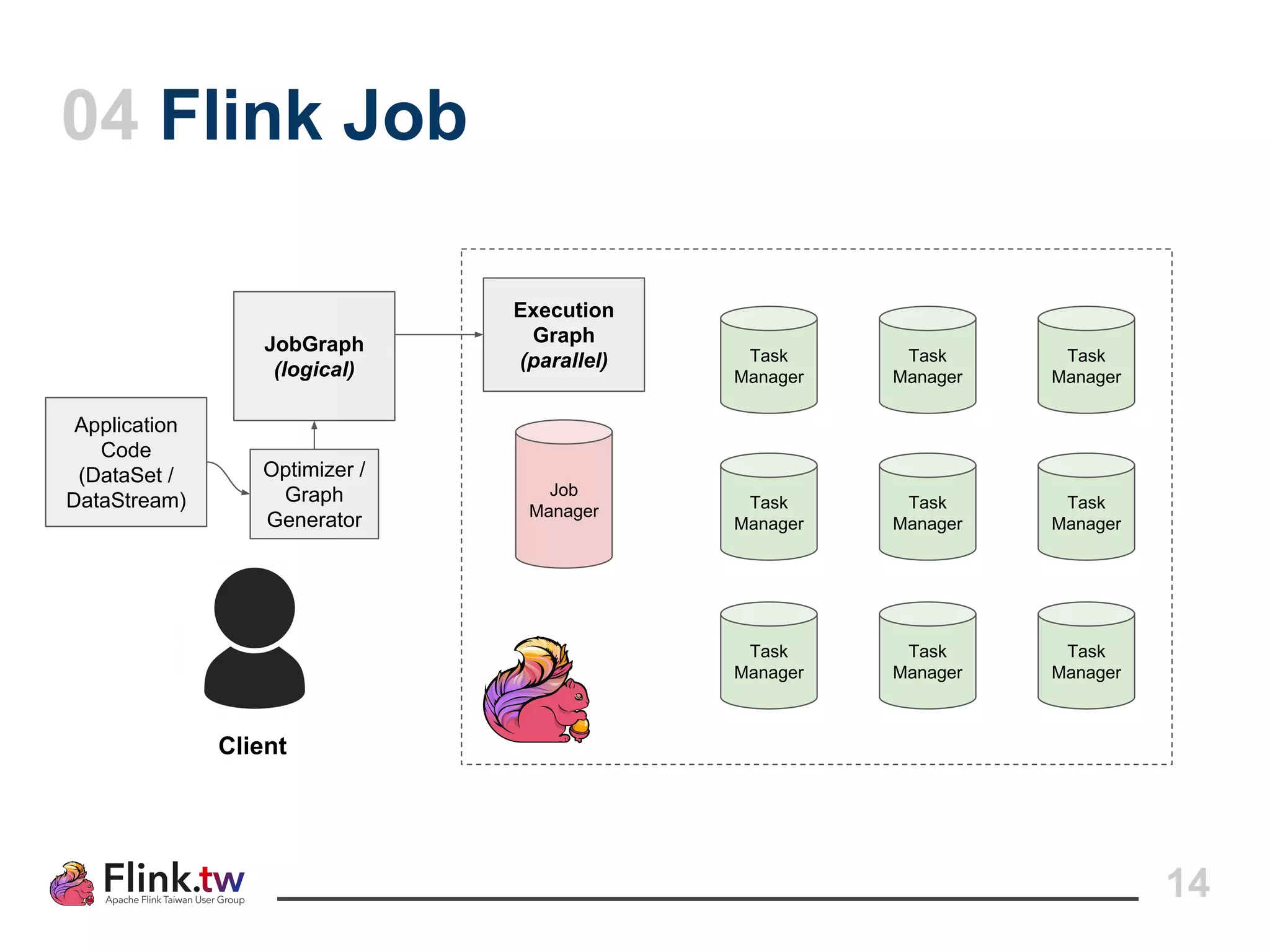
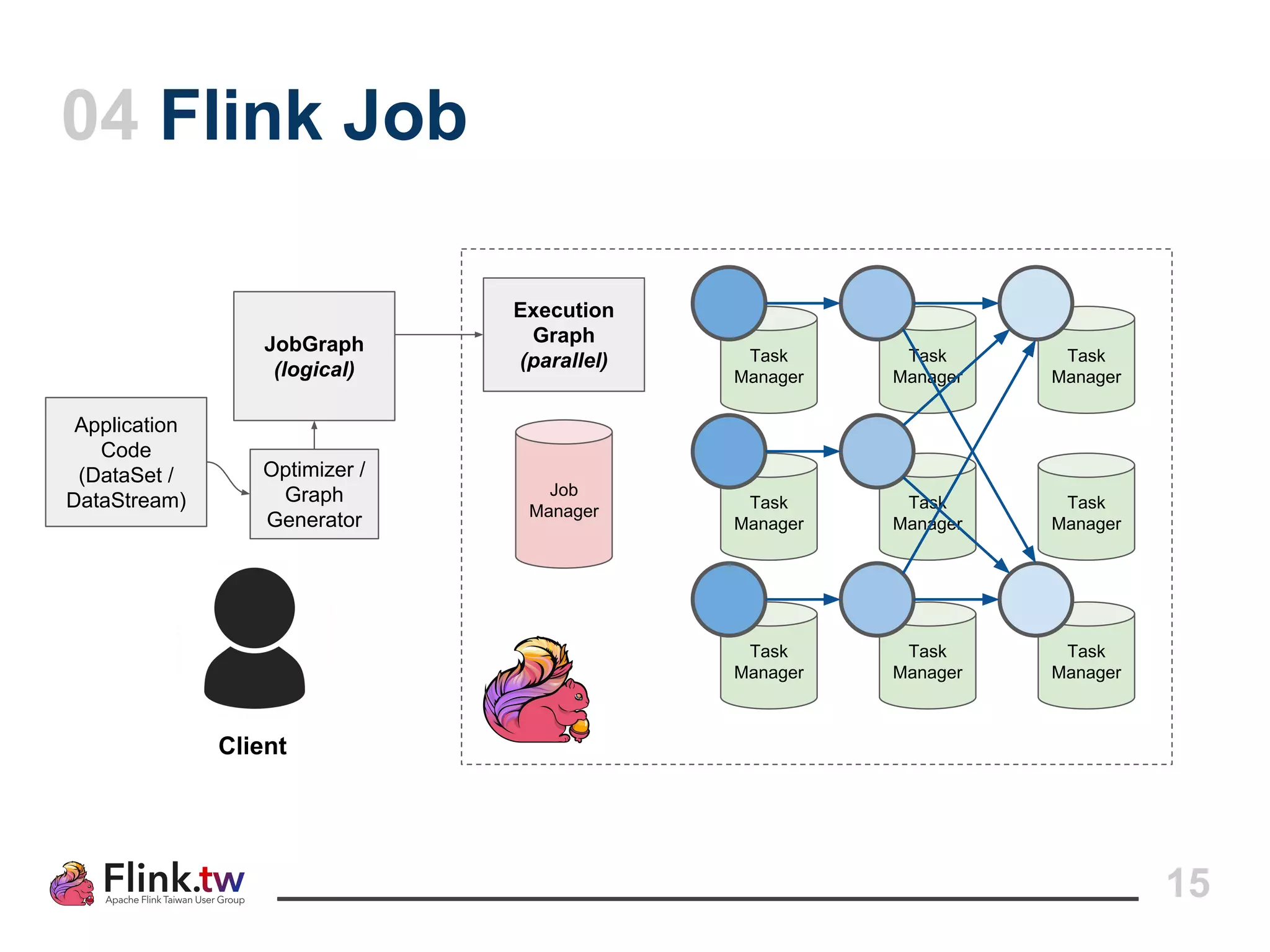
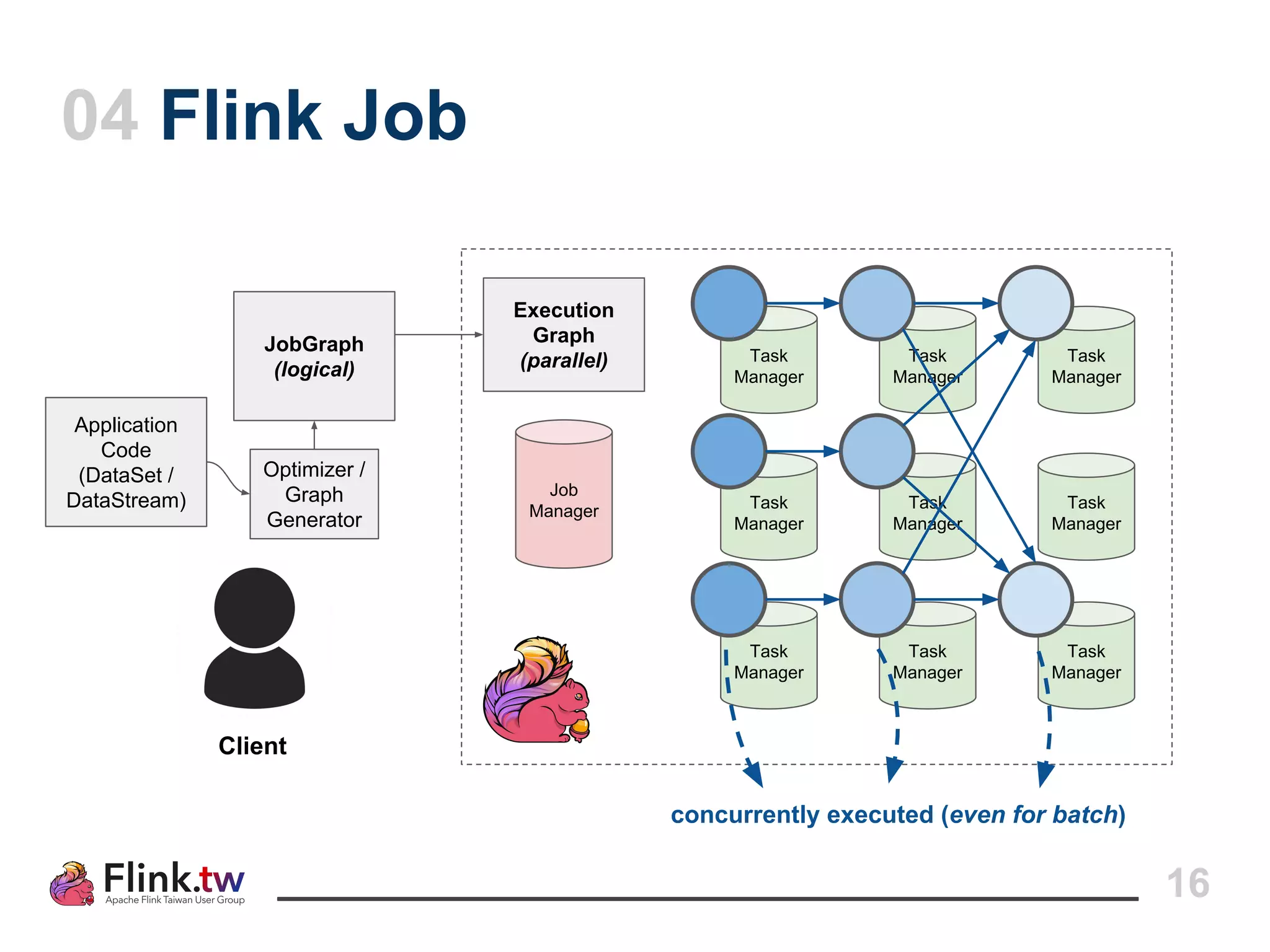
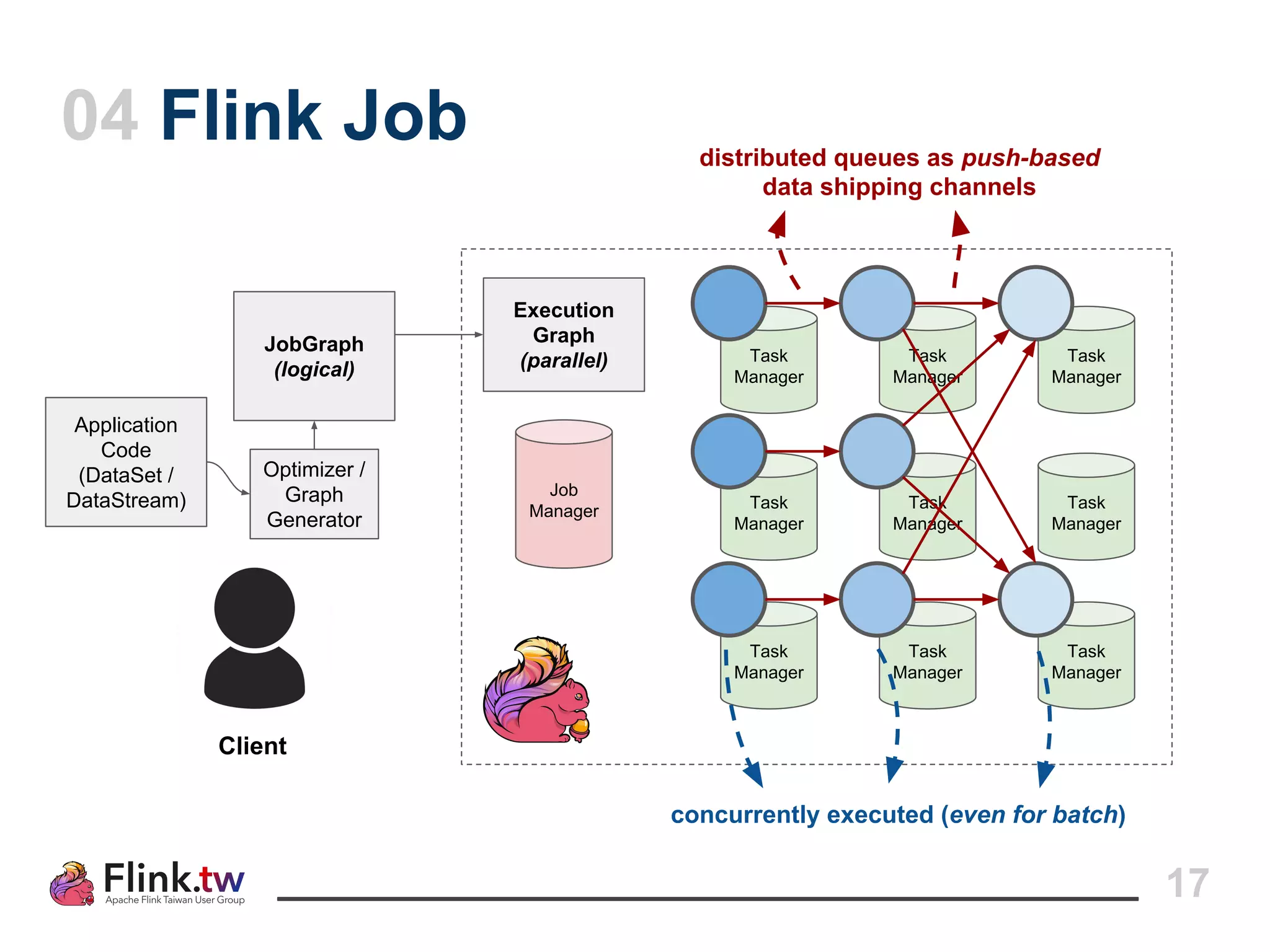

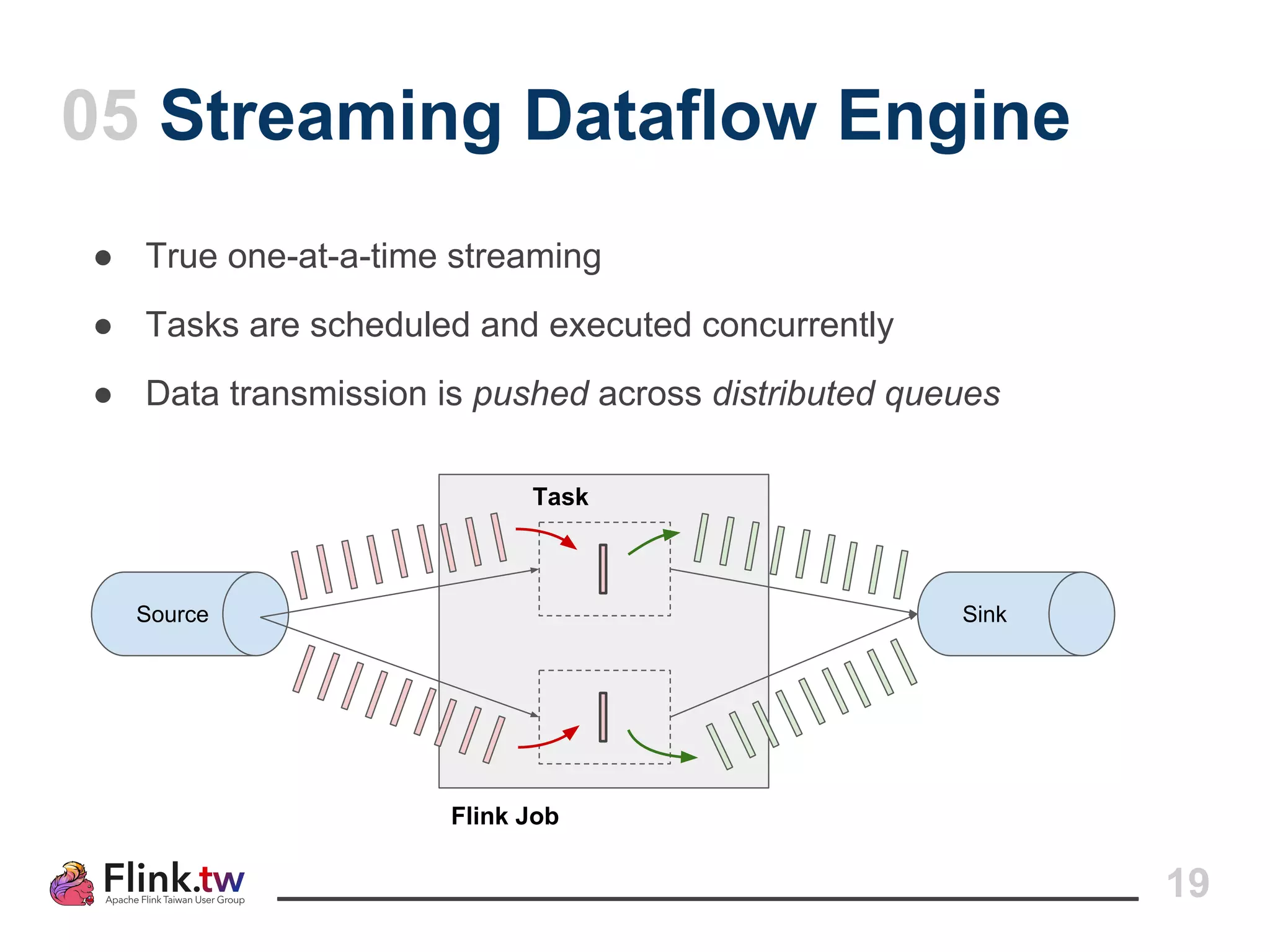
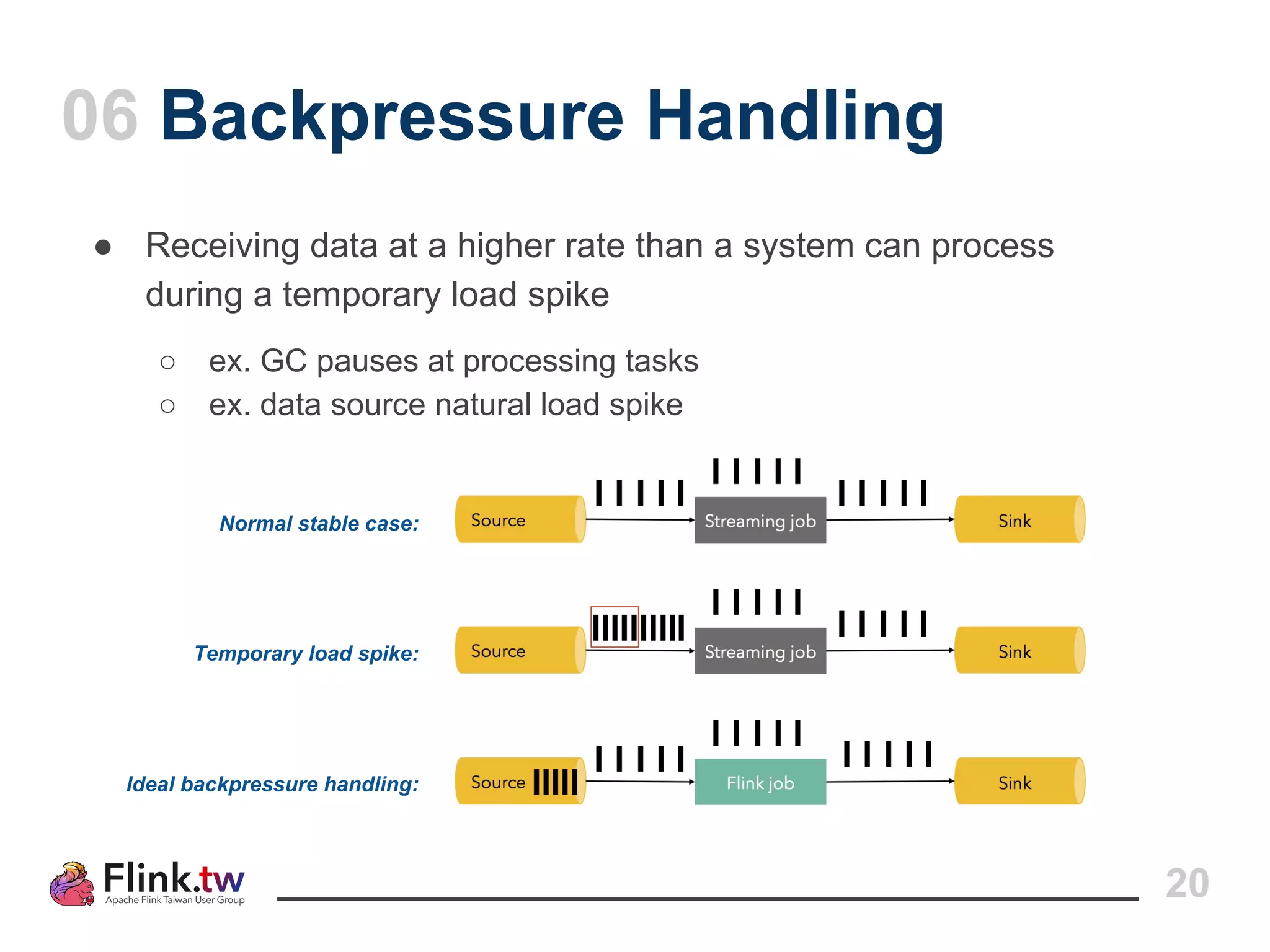
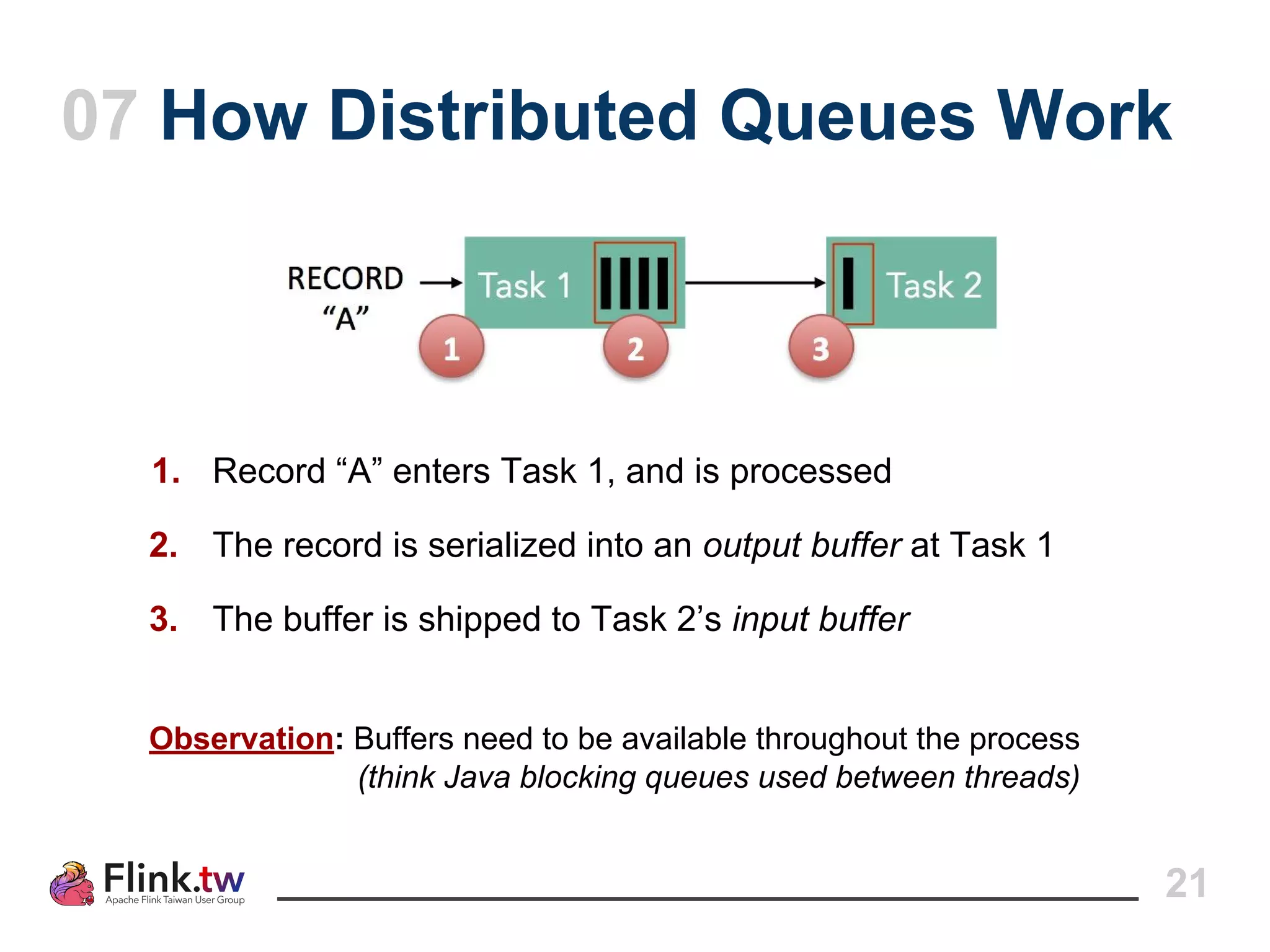
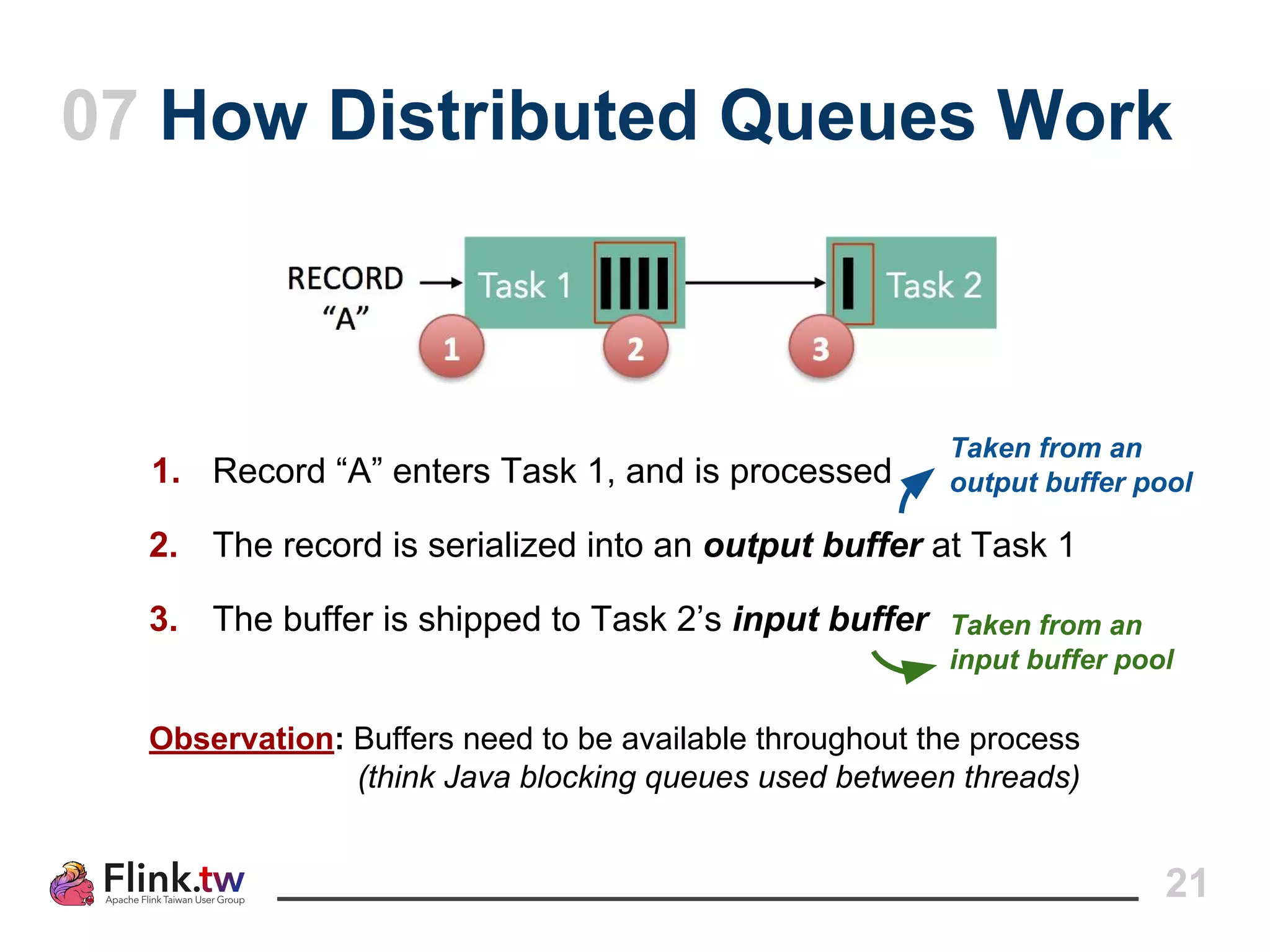
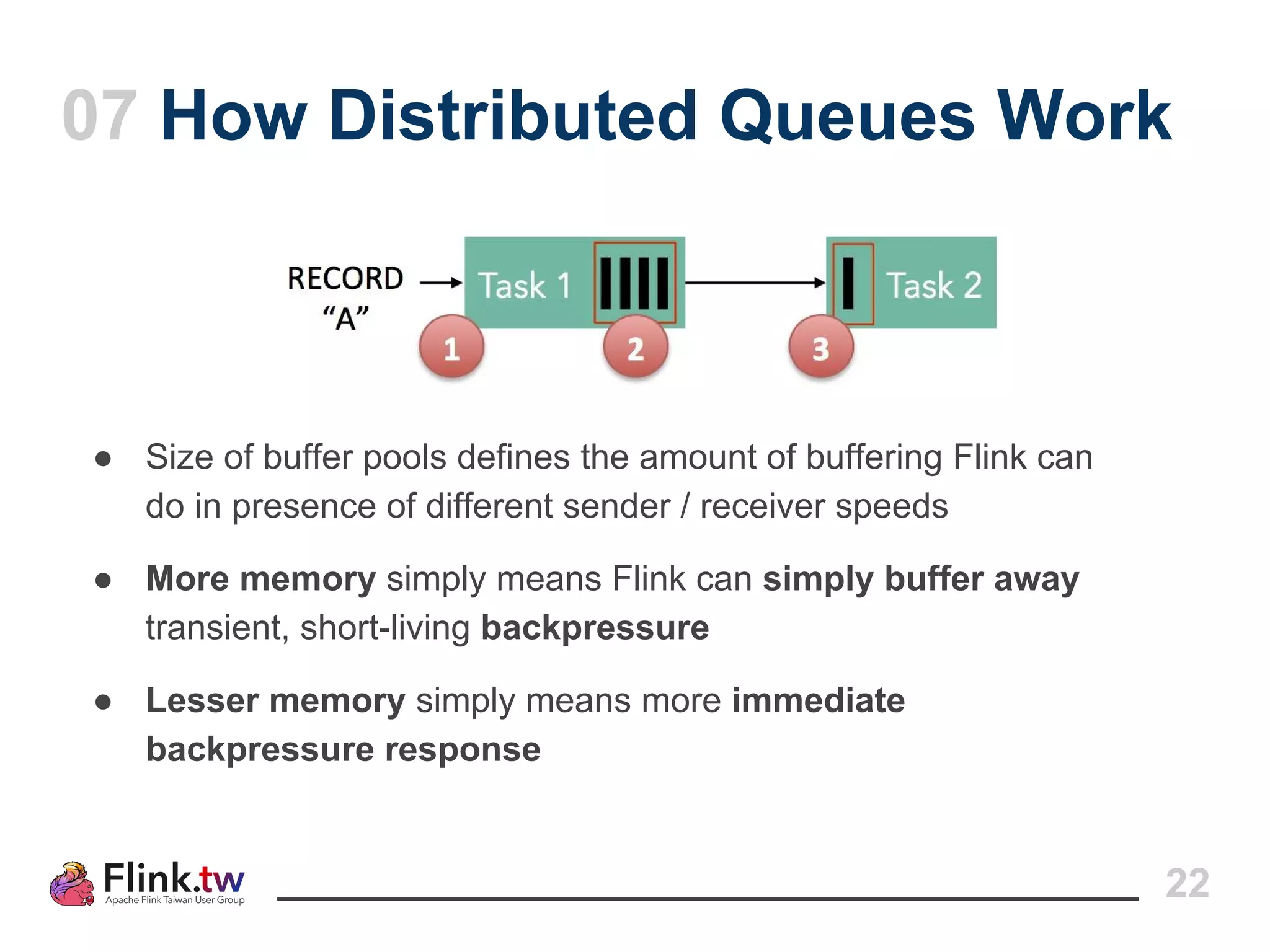

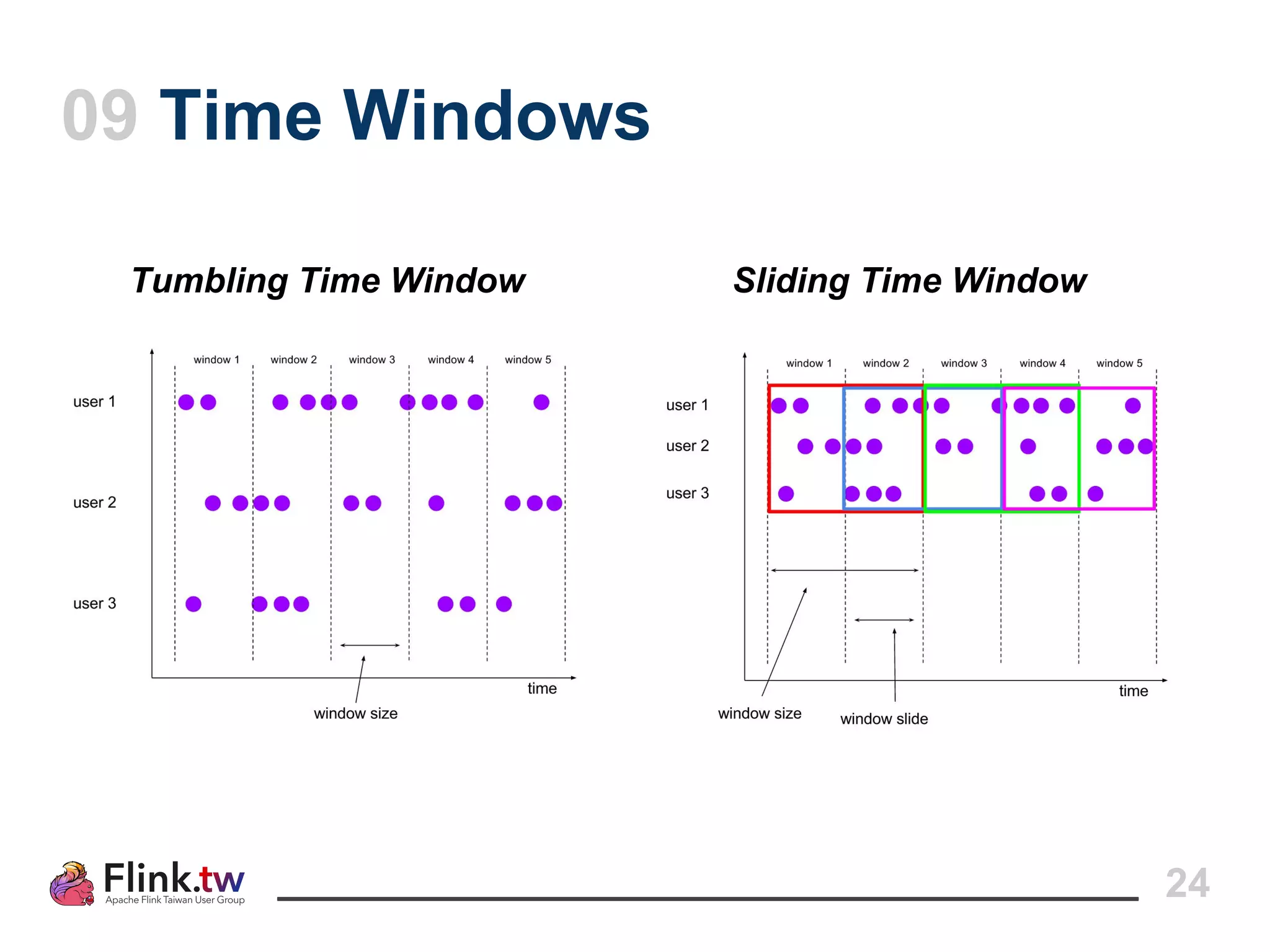
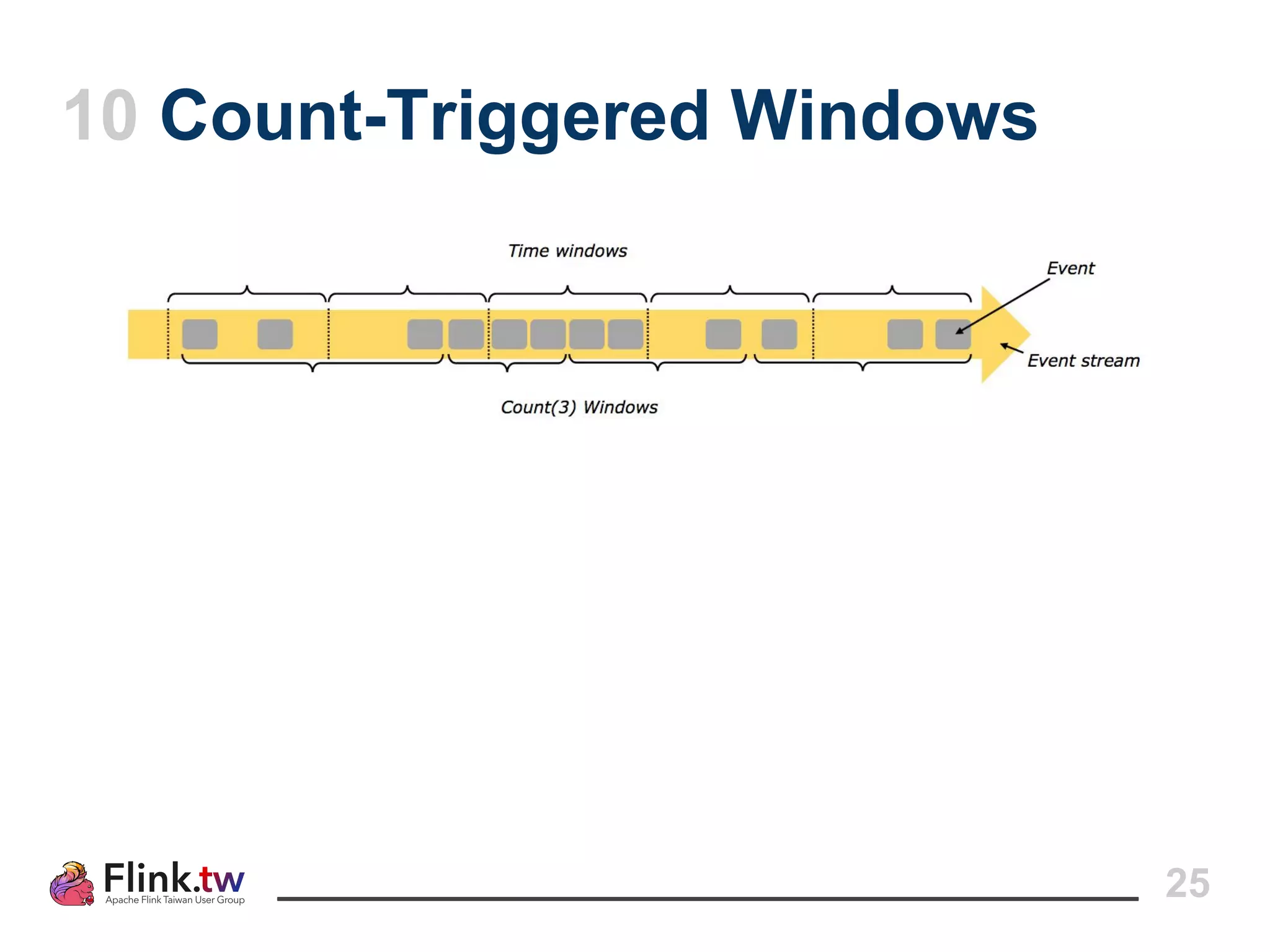
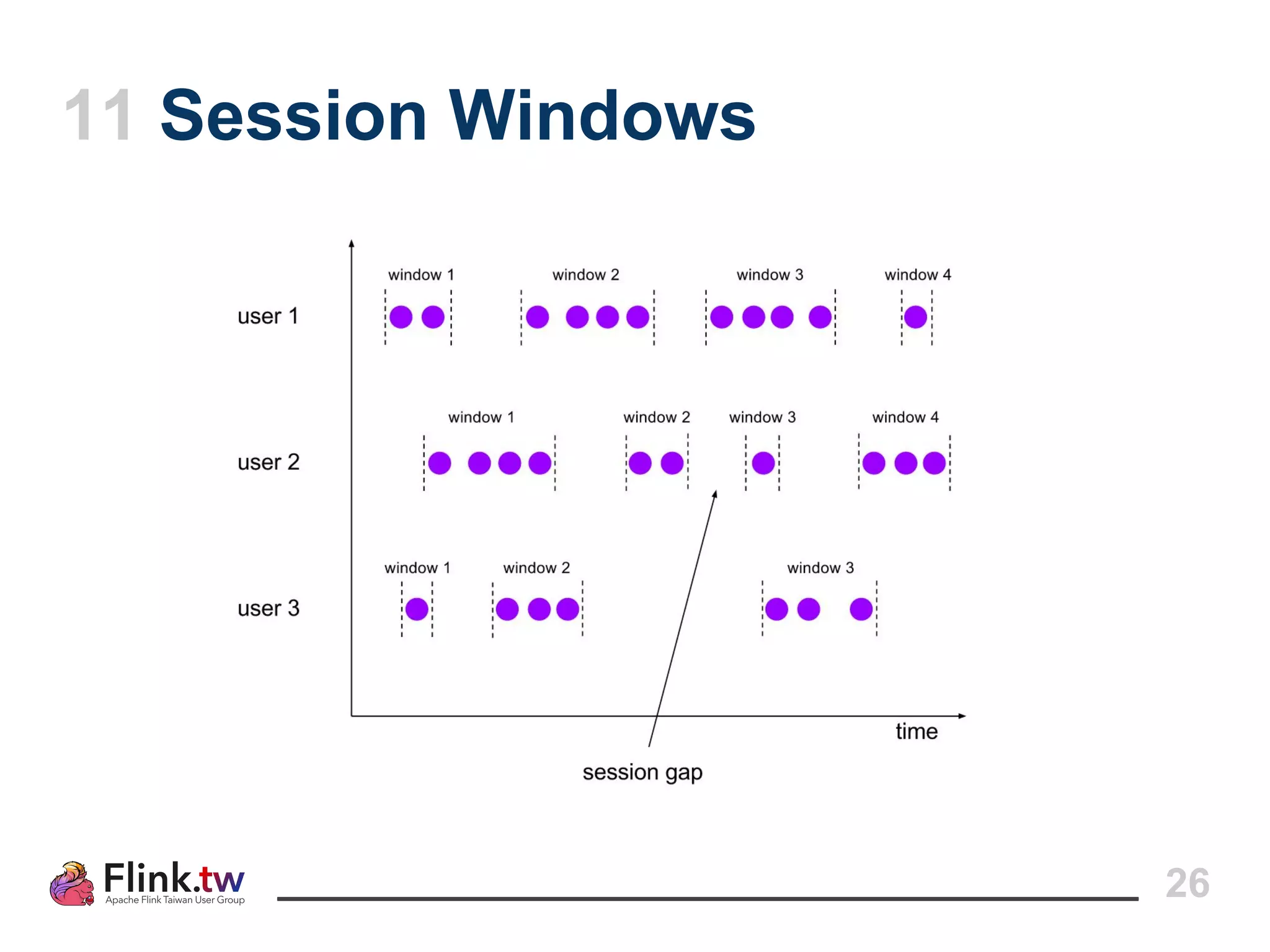



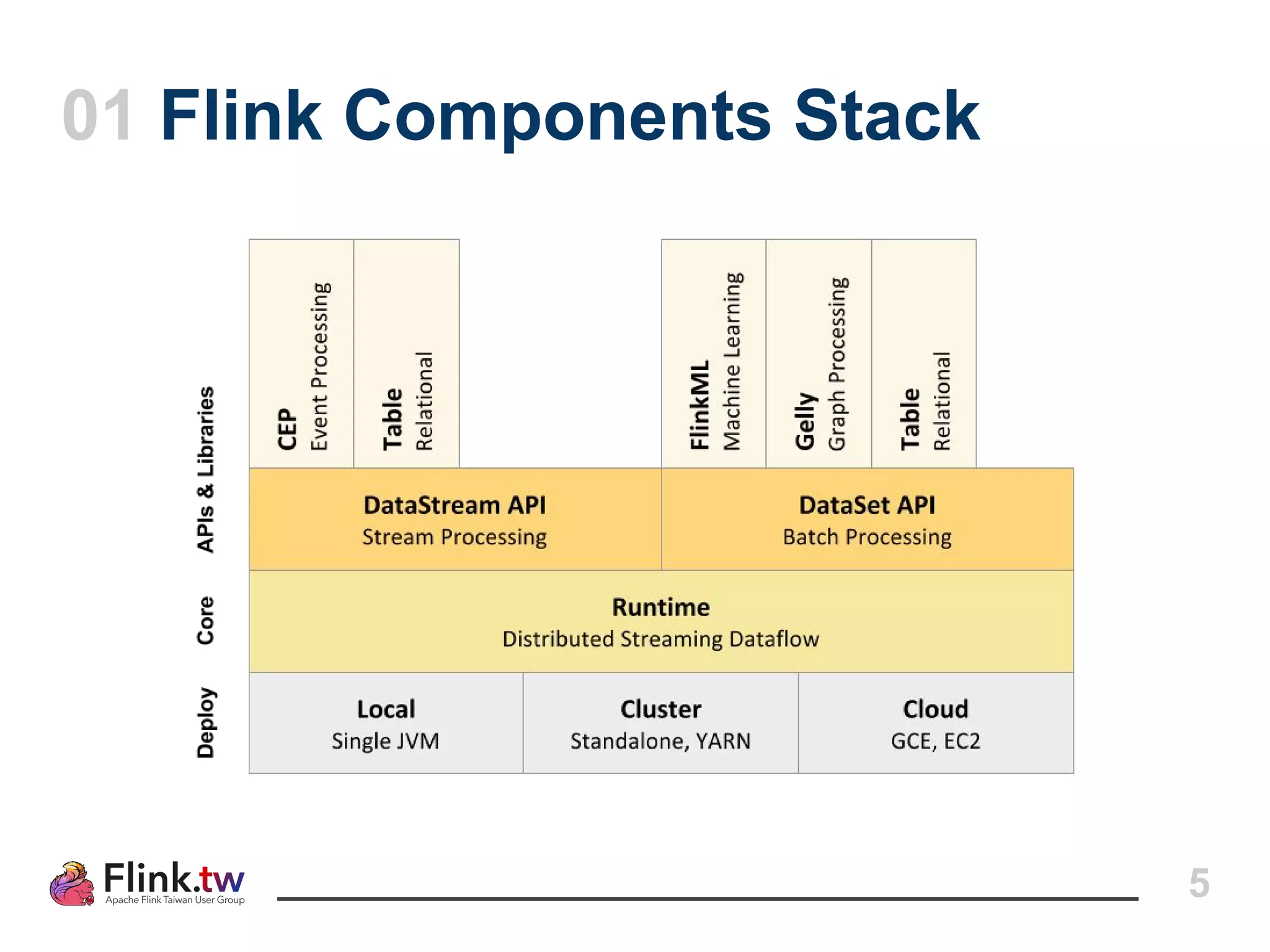
This document provides an overview of Apache Flink, an open-source platform for distributed stream and batch data processing, highlighting its components and features such as low latency and high throughput. It details the architecture of a Flink job, including the roles of application code, optimizers, and managers, and describes Flink's streaming-first philosophy and advantages. The document also covers backpressure handling, distributed queues, and flexible windowing options for processing data streams.








































































![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)




