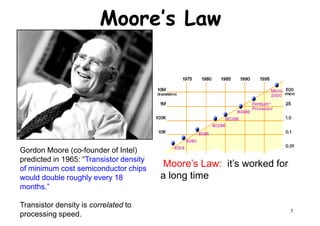
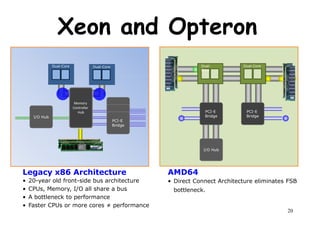
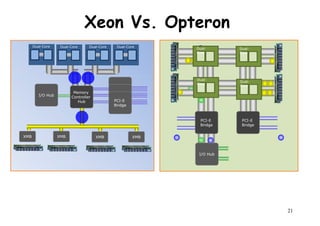
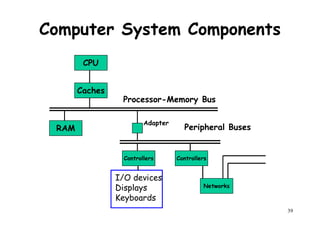
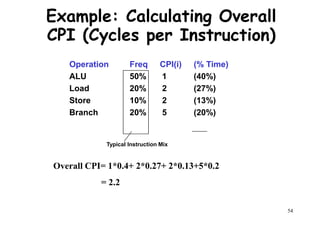
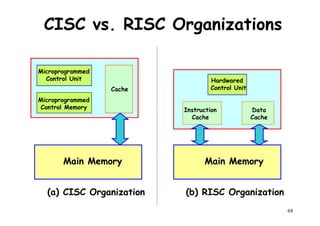
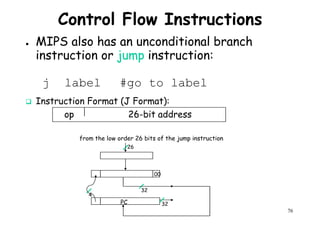
The document provides an introduction to computer architecture and performance. It discusses how performance has increased due to Moore's Law and transistor density doubling every 18 months. It explains that improvements in recent decades have come more from architectural innovations like pipelining than just manufacturing advances. Pipelining allows multiple instructions to be processed simultaneously to improve performance. The document outlines some objectives of studying innovations like RISC architectures, pipelining, caching and parallel processing.
















































![A MIPS Example
cont…
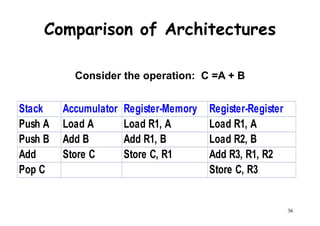
CPI1 =
(5 + 1 + 1) x 106
[(5x1) + (1x2) + (1x3)] x 106
10/7 = 1.43=
count cycles
(5 + 1 + 1) x 106
MIPS1 =
1.43
100 MHz
69.9=
CPI2 =
(10 + 1 + 1) x 106
[(10x1) + (1x2) + (1x3)] x 106
15/12 = 1.25=
59
(10 + 1 + 1) x 106
MIPS2 =
1.25
100 MHz
80.0=
So, compiler 2 has a higher
MIPS rating and should be
faster?](https://image.slidesharecdn.com/introductiontohpca-190124124932/85/High-Performance-Computer-Architecture-59-320.jpg)


![CPU Performance Equation
● Suppose we have made the following measurements :-
– Frequency of FP operations (Other than FPSQRT) = 25 %
– Average CPI of FP operations = 4.0
– Average CPI of other operations = 1.33Average CPI of other operations = 1.33
– Frequency of FPSQRT = 2%
– CPI of FPSQRT = 20
– Assume that the 2 design alternatives are to decrease the CPI of FPSQRT to 2 or
to decrease the average CPI Of all FP operations to 2.5. Compare these 2 design
alternatives using the CPU performance equation.
● Solutions:- First observe that only the CPI changes, the clock rate and instruction
count remain identical. We can start by finding original CPI without enhancement:-
n
62
We can compute the CPI for the enhanced FPSQRT by subtracting the cycles saved from
the original CPI :-
CPI with new FPSQRT = CPI Original – [2% x (CPI old FPSQRT – CPI new FPSQRT)]
= 2 – [(2/10)x (20-2)] = 1.64
Σ CPIi x Ni
i =1
n
Instruction Count
CPU Clock Cycles
Instruction Count
=CPI original = = (4 x 25%) + (1.33 x 75%) ~ 2
=](https://image.slidesharecdn.com/introductiontohpca-190124124932/85/High-Performance-Computer-Architecture-62-320.jpg)













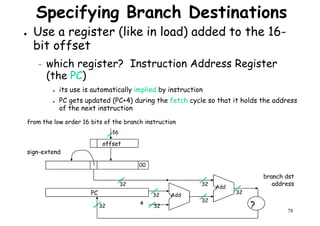


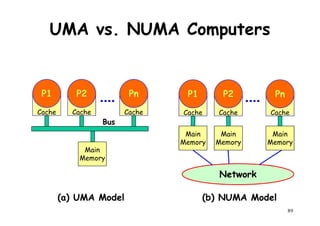
![Architectural Classifications
● Flynn’s Classifications [1966]
Based on multiplicity of instruction streams– Based on multiplicity of instruction streams
& data stream in a computer.
● Feng’s Classification [1972]
– Based on serial & parallel processing.
● Handler’s Classification [1977]
81
Handler’s Classification [1977]
– Determined by the degree of parallelism &
pipeline in various subsystem level.](https://image.slidesharecdn.com/introductiontohpca-190124124932/85/High-Performance-Computer-Architecture-81-320.jpg)










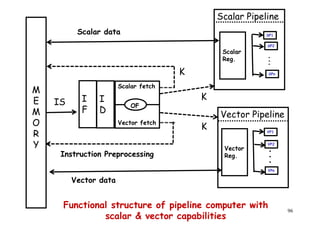
![Array processor
● Synchronous parallel computer with multiple
arithmetic logic units [Same function at same
time] .
● By replication of ALU system can achieve
spatial parallelism.
● An appropriate data routing mechanism must
be establish among the PE’s.
Scalar & control type instructions are directly
97
● Scalar & control type instructions are directly
executed in control unit.
● Each PE consist of one ALU with register &
local memory.](https://image.slidesharecdn.com/introductiontohpca-190124124932/85/High-Performance-Computer-Architecture-97-320.jpg)

![Control
Processor
Control
Memory
I/O
Control Unit P: Processor
M: Memory
Data Bus
Scalar Processing
Duplicate Hardware PerformsDuplicate Hardware Performs
Multiple Tasks At OnceMultiple Tasks At Once
PP
M
P
MM
Array
Processing
. . . . .
PE1
PE 2
PE n
Control
99
Inter-PE connection network
[Data routing]
Functional structure of SIMD array processor with
concurrent scalar processing in control unit](https://image.slidesharecdn.com/introductiontohpca-190124124932/85/High-Performance-Computer-Architecture-99-320.jpg)


![Memory
module 1
Memory
module 2
..
Input-output
Interconnection
Network
Interprocessor-memory
Connection network
[Bus , crossbar or multiport]
. . . . . .
I/O channels
Memory
module n
..
..
..
Shared Memory Inter-
processor
interrupt
P 1
LM1
P 2 LM2
. . . .
102
interrupt
network
P n LM n
Functional design of an MIMD multiprocessor system](https://image.slidesharecdn.com/introductiontohpca-190124124932/85/High-Performance-Computer-Architecture-102-320.jpg)





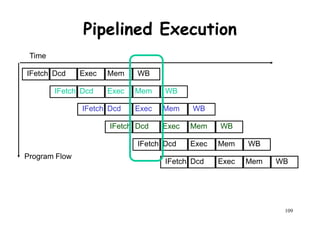




![Ideal Pipeline Speedup
● k-stage pipeline processes n tasks in k + (n-1)
clock cycles:clock cycles:
– k cycles for the first task and n-1 cycles for the
remaining n-1 tasks.
● Total time to process n tasks
● Tk = [ k + (n-1)] τ
For the non-pipelined processor
118
● For the non-pipelined processor
T1 = n k τ](https://image.slidesharecdn.com/introductiontohpca-190124124932/85/High-Performance-Computer-Architecture-118-320.jpg)
![Pipeline Speedup Expression
Speedup=
● Maximum speedup = Sk K ,for n >> K
Sk =
T1
Tk
=
n k τ
[ k + (n-1)] τ
=
n k
k + (n-1)
119
● Observe that the memory bandwidth
must increase by a factor of Sk:
– Otherwise, the processor would stall waiting for
data to arrive from memory.](https://image.slidesharecdn.com/introductiontohpca-190124124932/85/High-Performance-Computer-Architecture-119-320.jpg)
![Efficiency of pipeline
● The percentage of busy time-space span over
the total time span.
– n:- no. of task or instruction– n:- no. of task or instruction
– k:- no. of pipeline stages
– τ:- clock period of pipeline
● Hence pipeline efficiency can be defined by:-
n * k * τ
η =
n
=
120
n * k * τ
K [ k*τ +(n-1) τ ]
η =
n
k+(n-1)
=](https://image.slidesharecdn.com/introductiontohpca-190124124932/85/High-Performance-Computer-Architecture-120-320.jpg)
![Throughput of pipeline
● Number of result task that can be completed
by a pipeline per unit time.
W =
n
=
n
=
η
● Idle case w = 1/τ = f when η =1.
W =
n
k*τ+(n-1)τ
=
n
[k+(n-1)]τ
=
η
τ
121
Idle case w = 1/τ = f when η =1.
● Maximum throughput = frequency of linear
pipeline](https://image.slidesharecdn.com/introductiontohpca-190124124932/85/High-Performance-Computer-Architecture-121-320.jpg)












![References
[1]J.L. Hennessy & D.A. Patterson,
“Computer Architecture: A Quantitative“Computer Architecture: A Quantitative
Approach”. Morgan Kaufmann Publishers,
3rd Edition, 2003
[2]John Paul Shen and Mikko Lipasti,
“Modern Processor Design,” Tata Mc-
Graw-Hill, 2005
135
Graw-Hill, 2005](https://image.slidesharecdn.com/introductiontohpca-190124124932/85/High-Performance-Computer-Architecture-135-320.jpg)



















































































