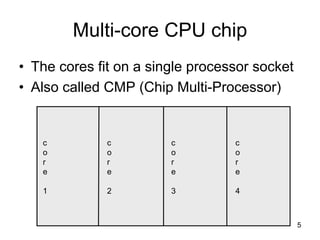
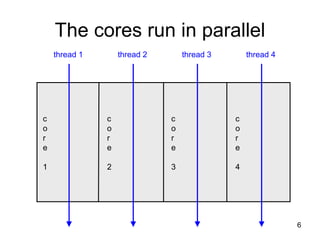
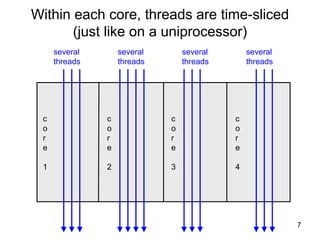
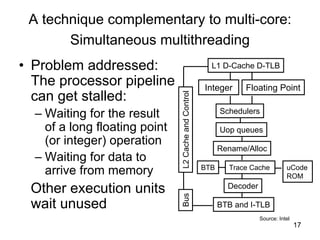
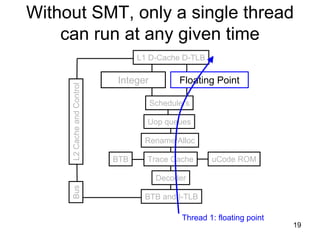
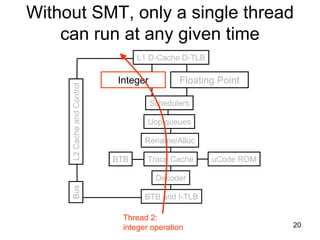
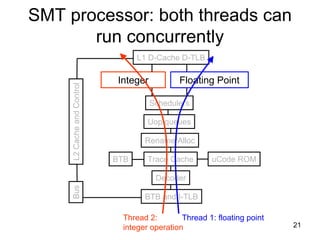
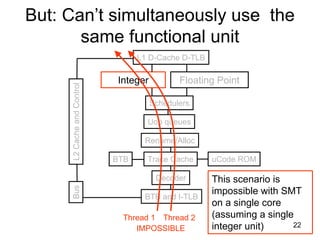
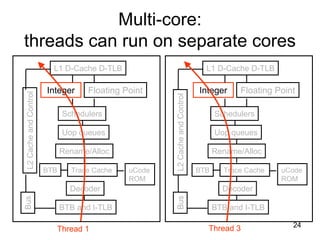
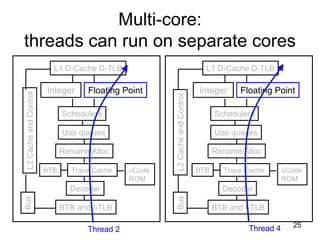
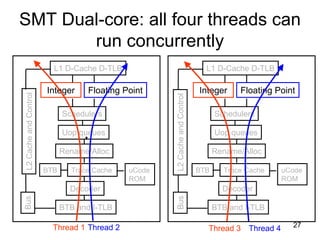
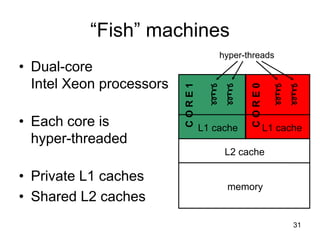
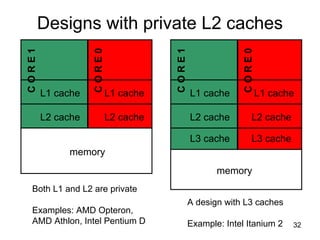
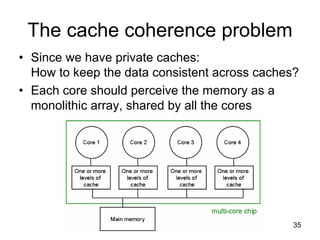
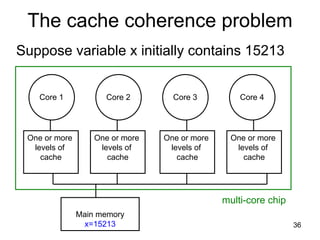
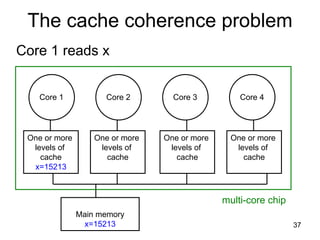
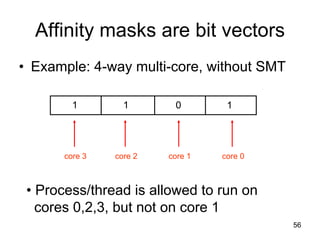
This document discusses multi-core processor architectures. It begins by explaining single-core processors and then introduces multi-core processors, which place multiple processor cores on a single chip. Each core can run threads independently and in parallel. The document discusses how operating systems schedule threads across multiple cores. It also covers challenges like cache coherence when multiple cores access shared memory. Overall, the document provides an overview of multi-core processors and how they exploit thread-level parallelism.


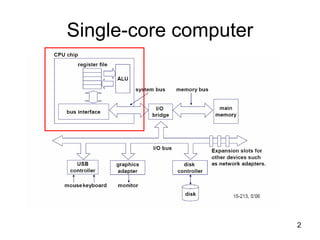
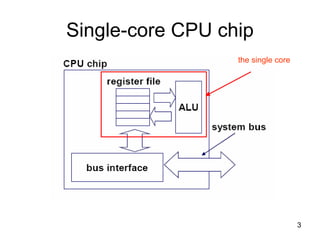
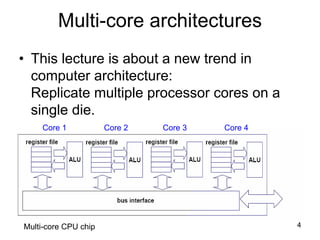

































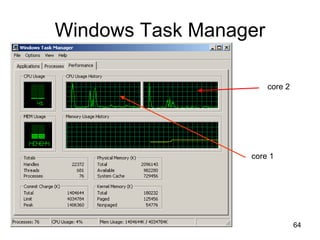
![63
Kernel scheduler API
#include <sched.h>
int sched_setaffinity(pid_t pid,
unsigned int len, unsigned long * mask);
Sets the current affinity mask of process ‘pid’ to *mask
‘len’ is the system word size: sizeof(unsigned int long)
To query affinity of a running process:
[barbic@bonito ~]$ taskset -p 3935
pid 3935's current affinity mask: f](https://image.slidesharecdn.com/27-multicore-171107084003/85/27-multicore-63-320.jpg)