Downloaded 83 times

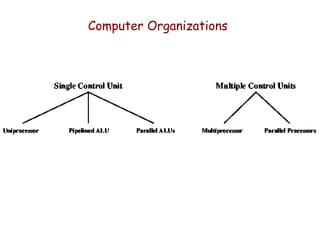







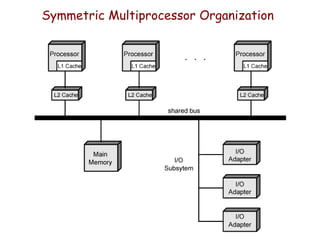



























The document discusses various types of parallel processing computer organizations, including SISD, SIMD, MISD, and MIMD, along with architecture types such as SMP and NUMA. It also covers advantages and limitations of different multiprocessor structures, including shared memory systems and cache coherence challenges, along with multithreading approaches and configurations. Additionally, it highlights the performance characteristics and scalability of cluster computing versus SMP systems.























































































