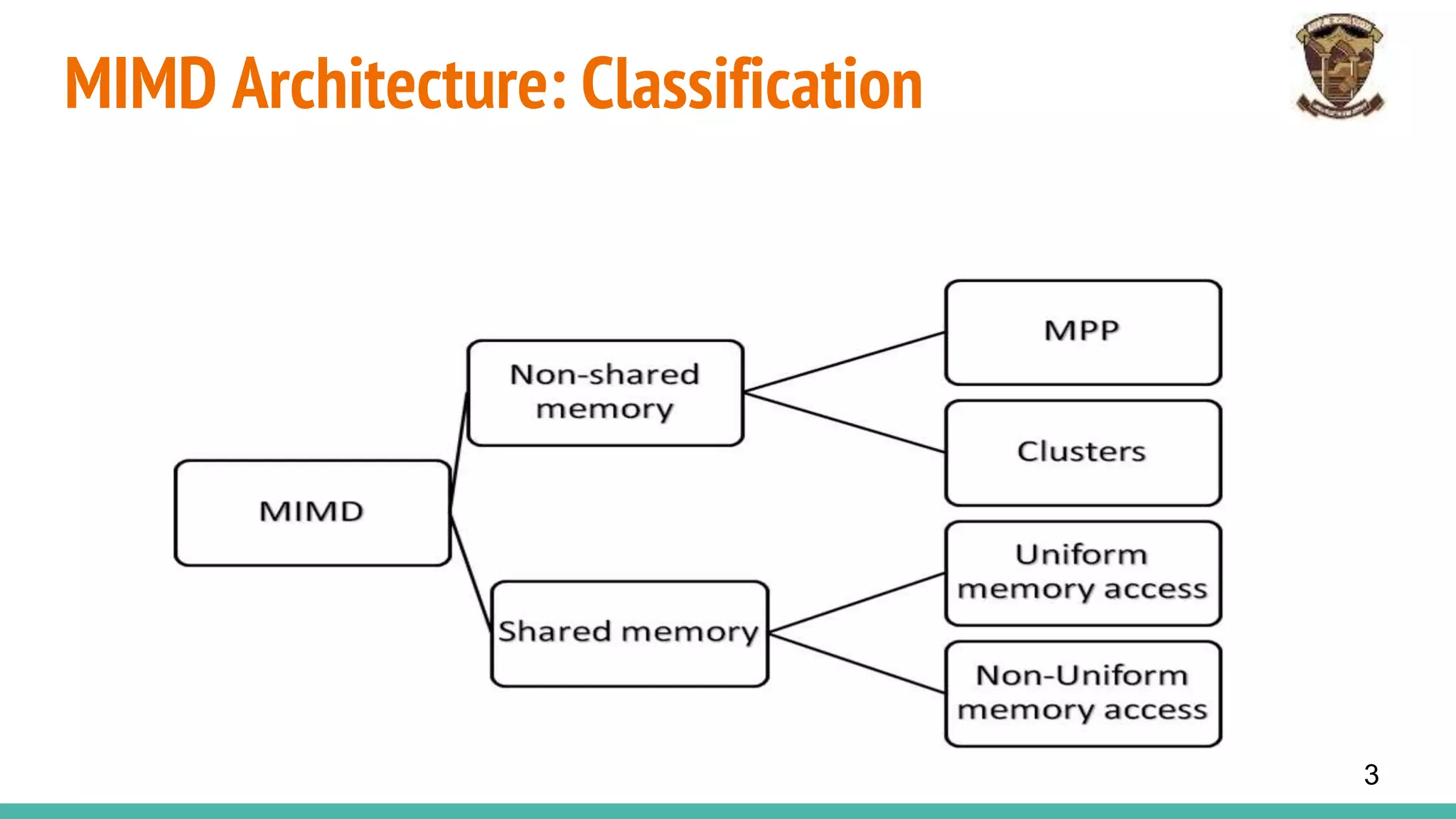
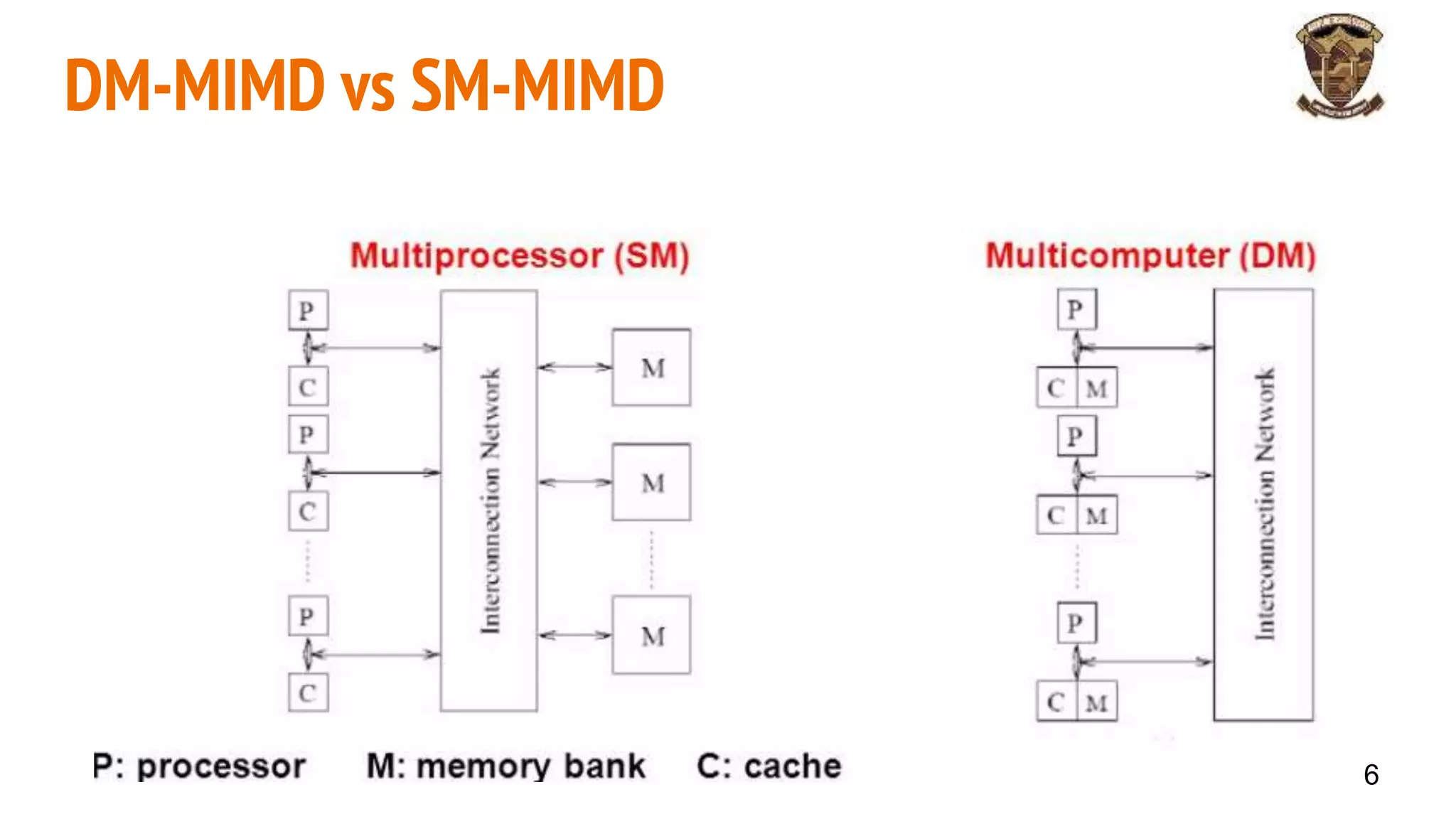
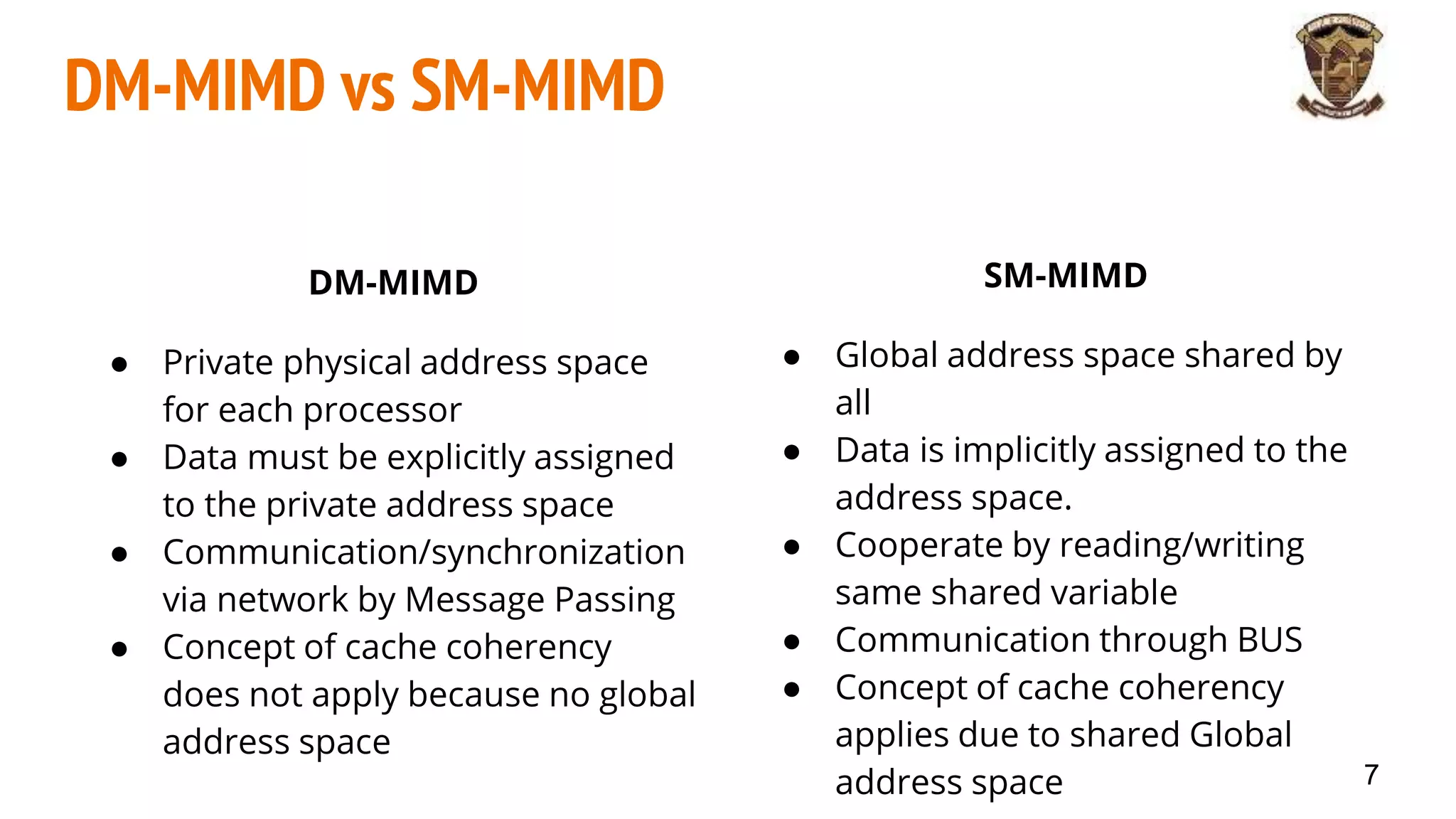
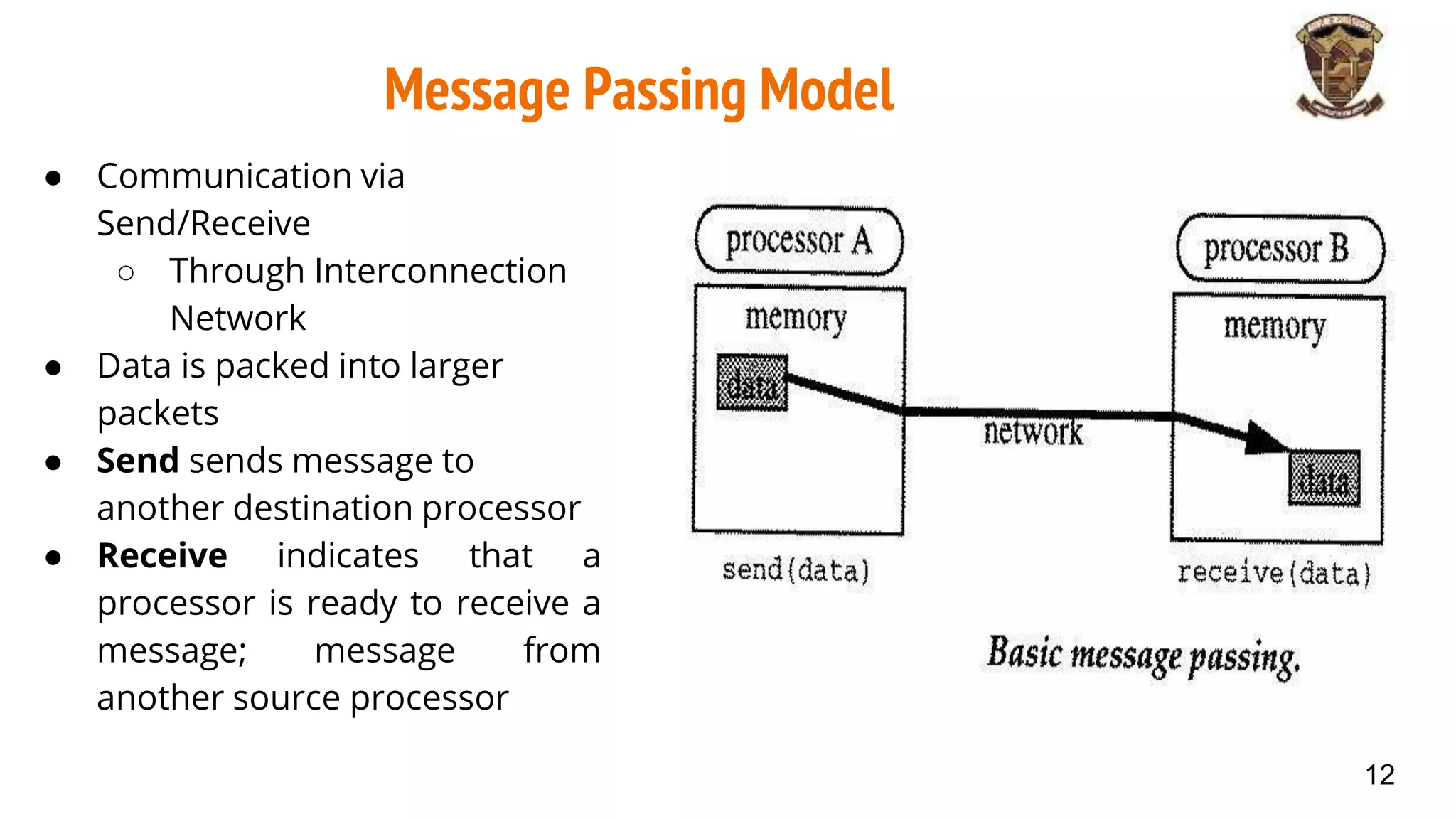
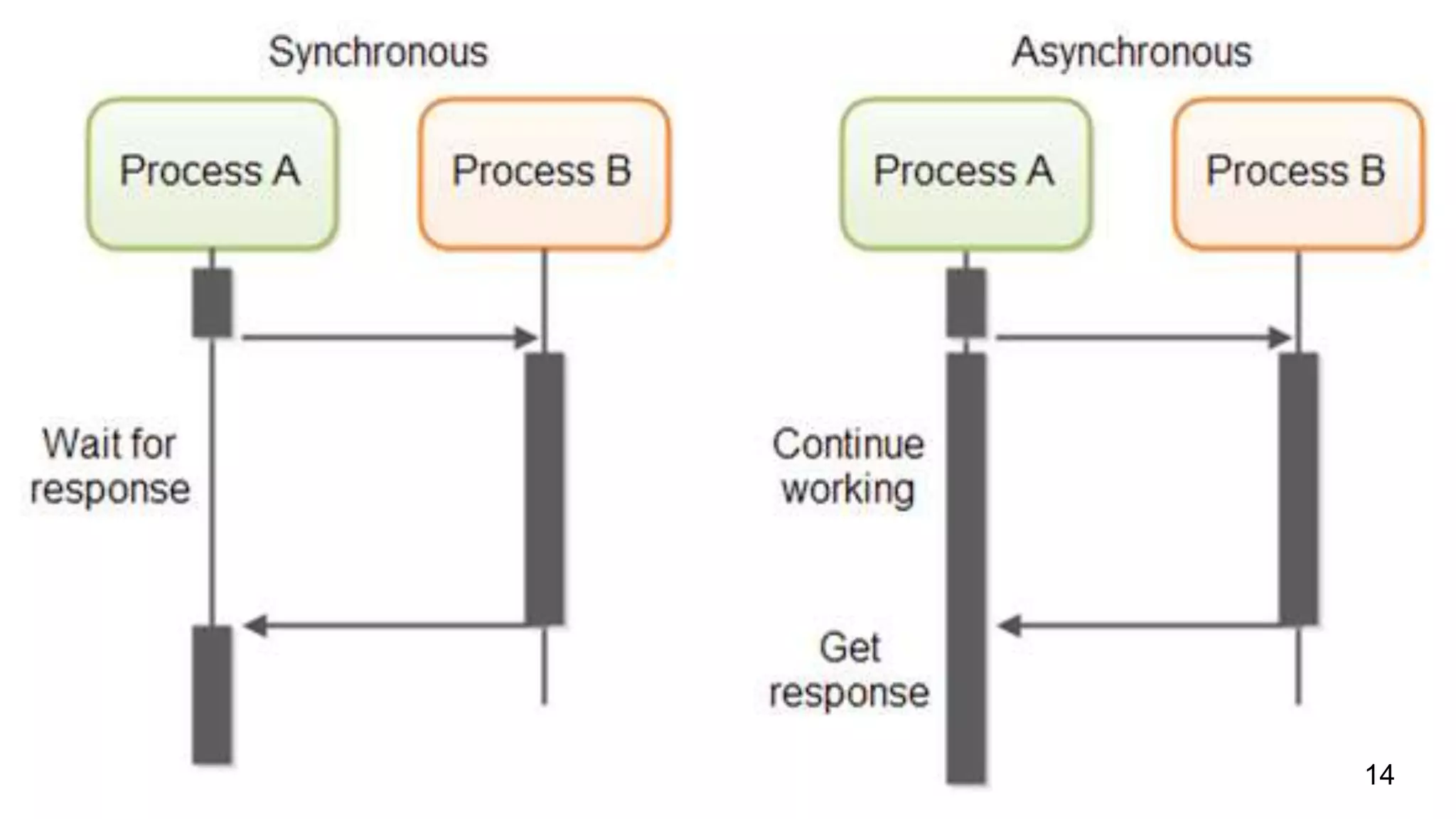
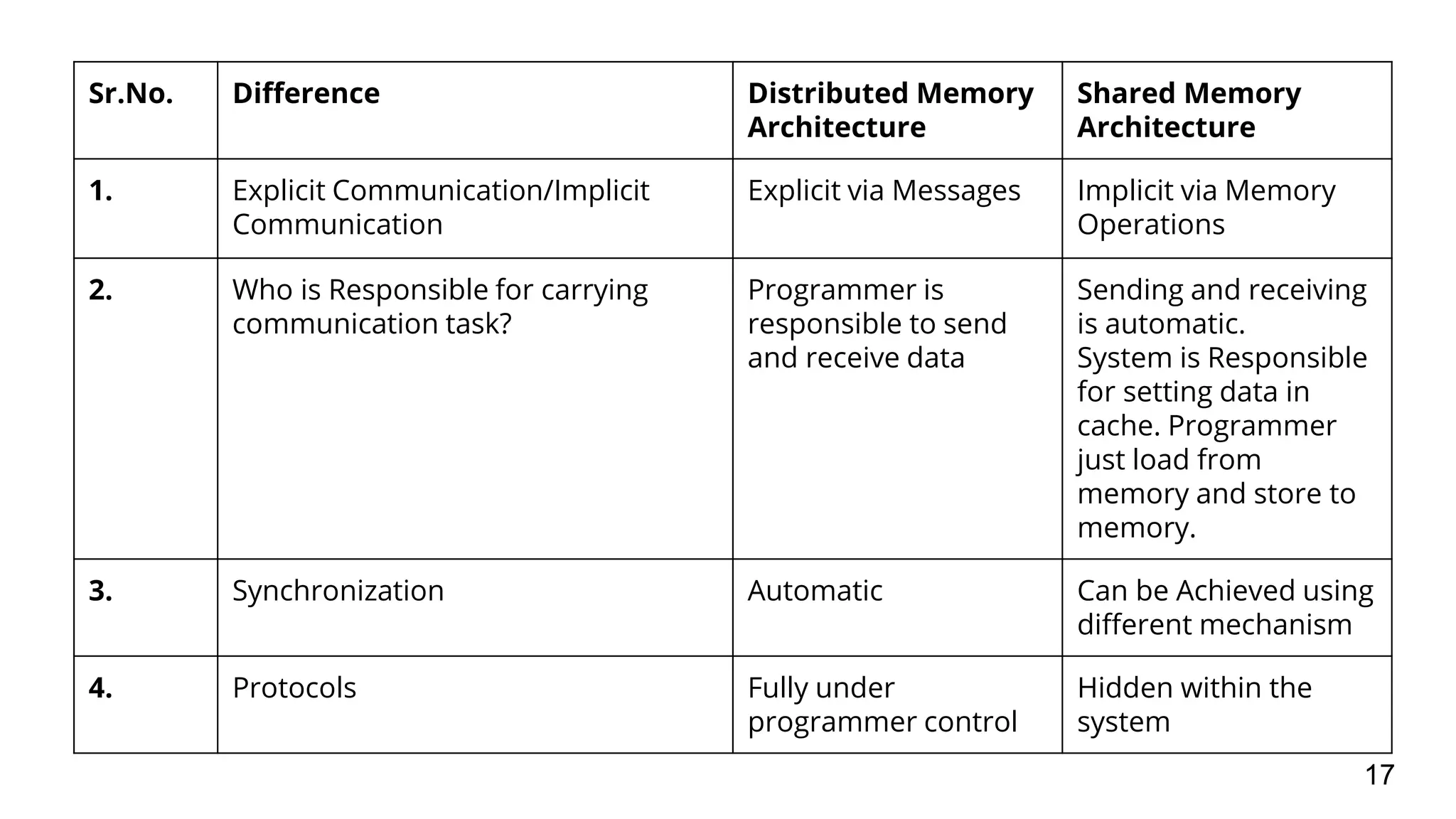
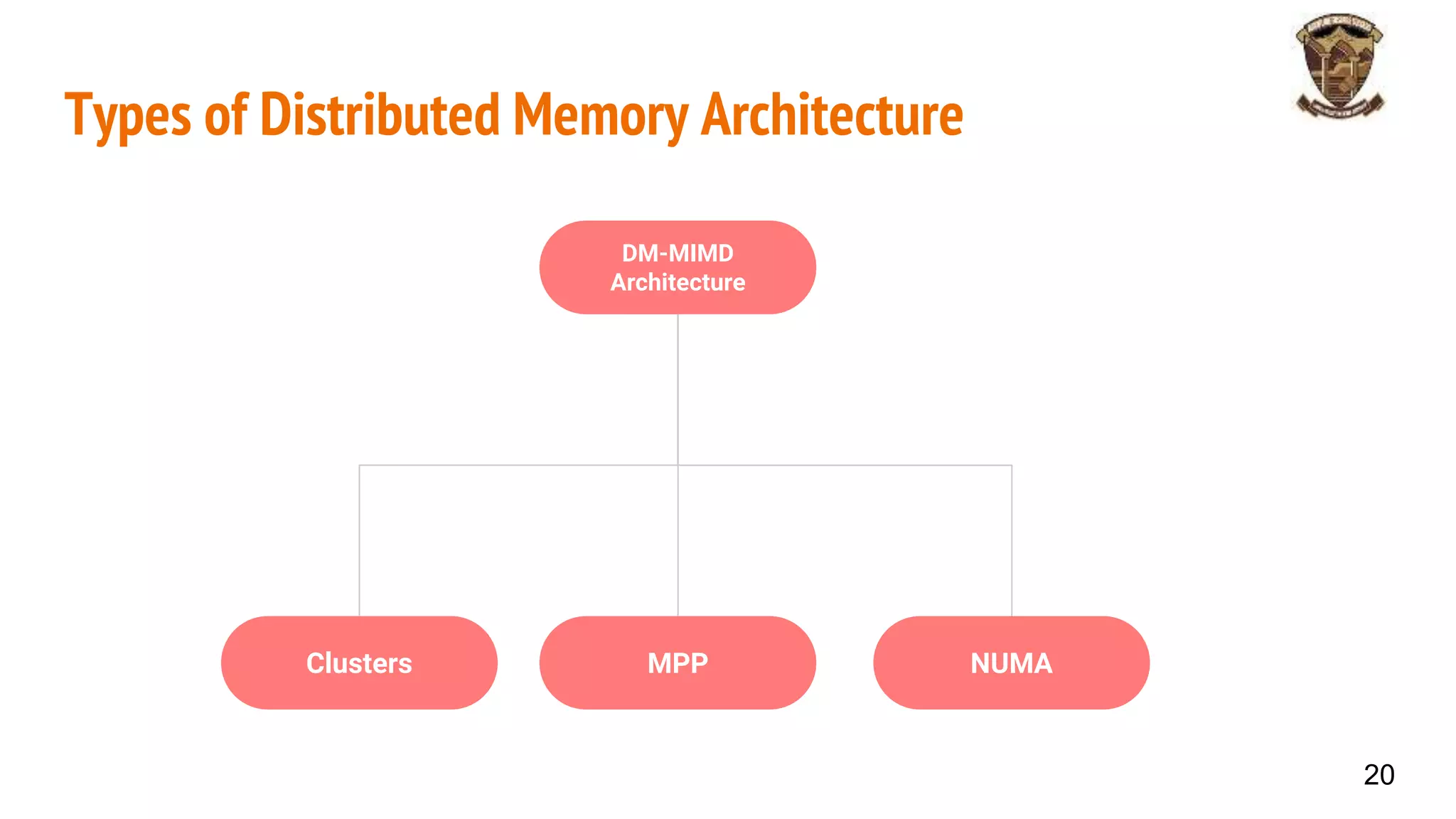
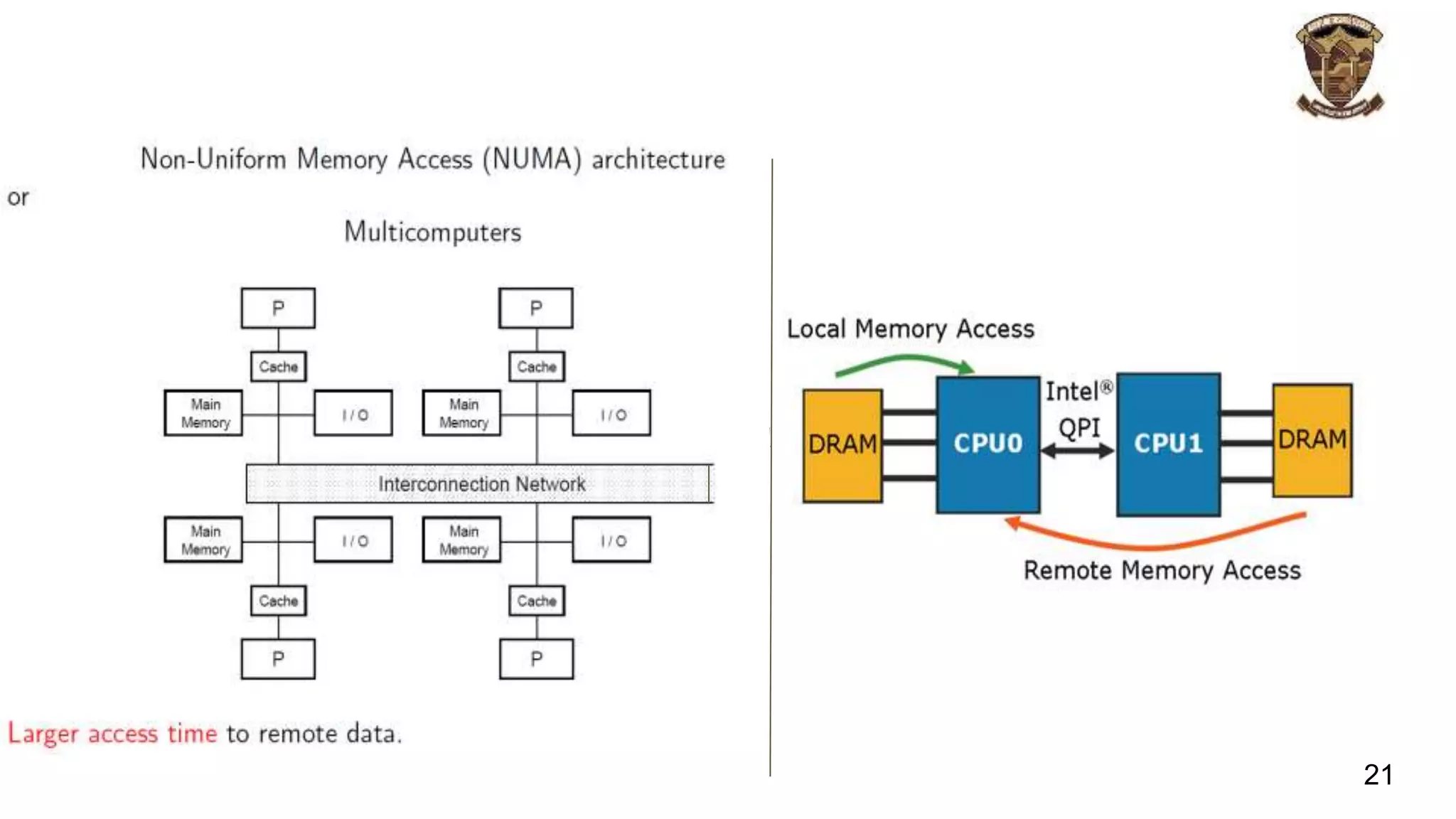
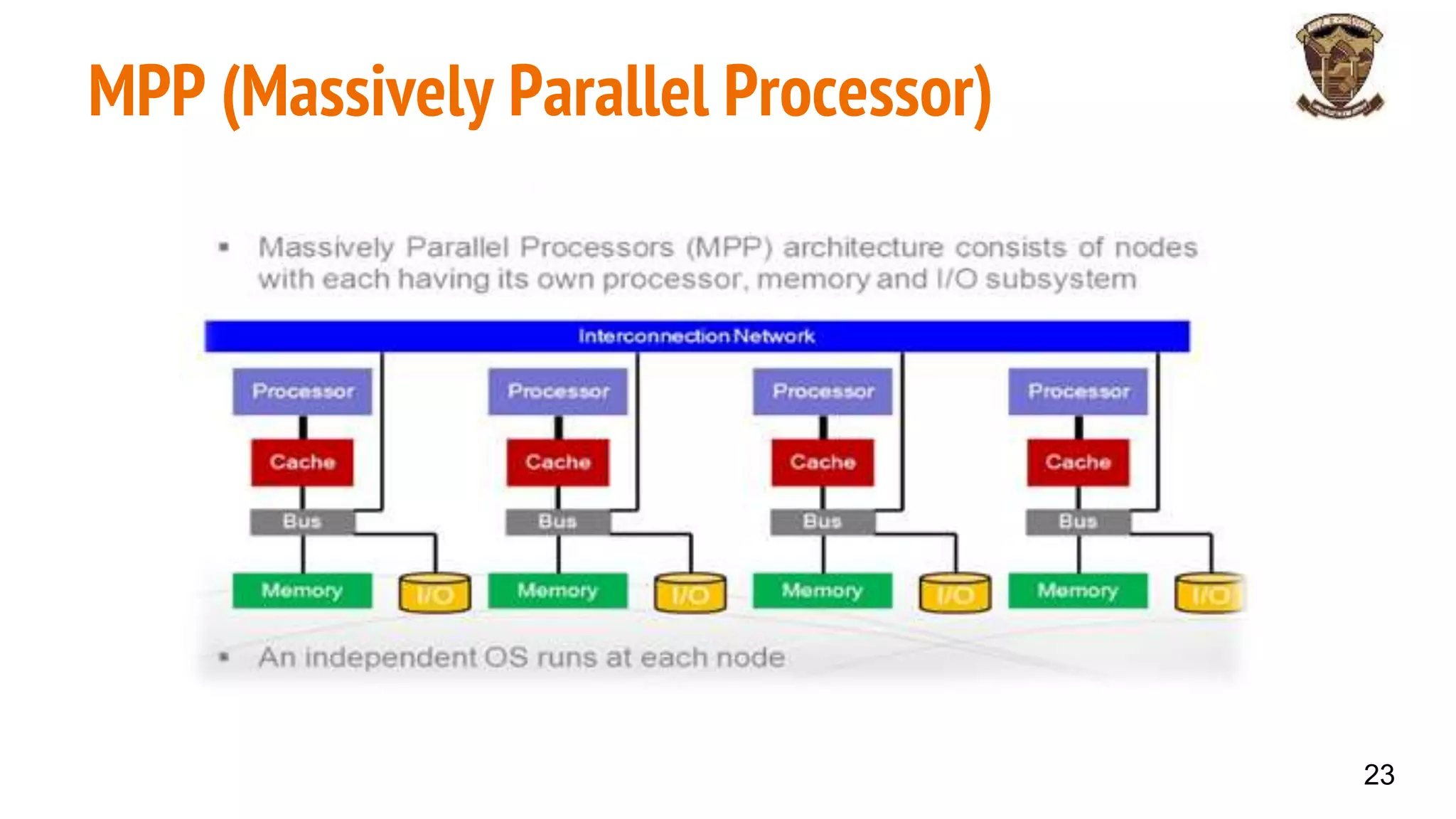
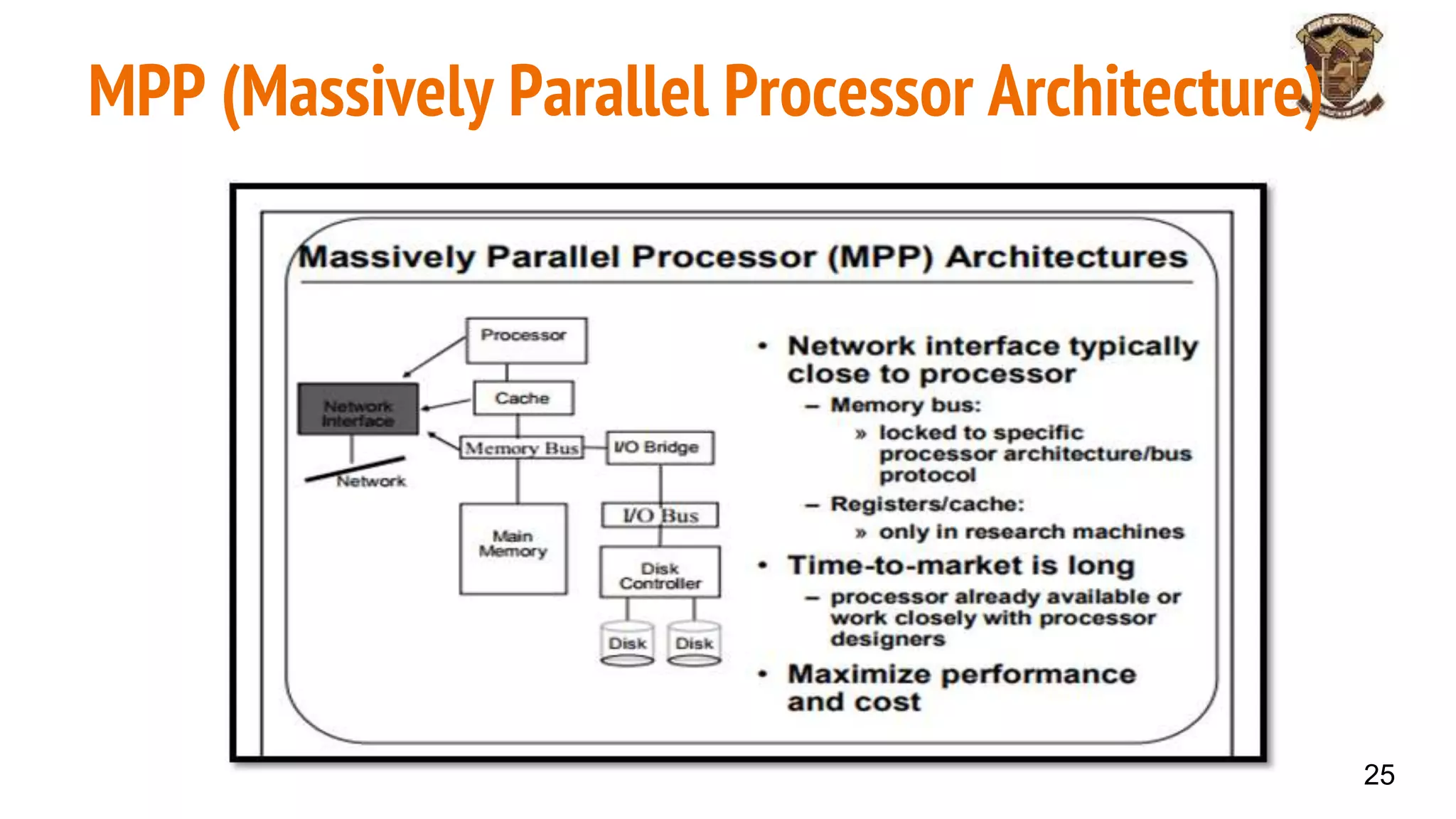
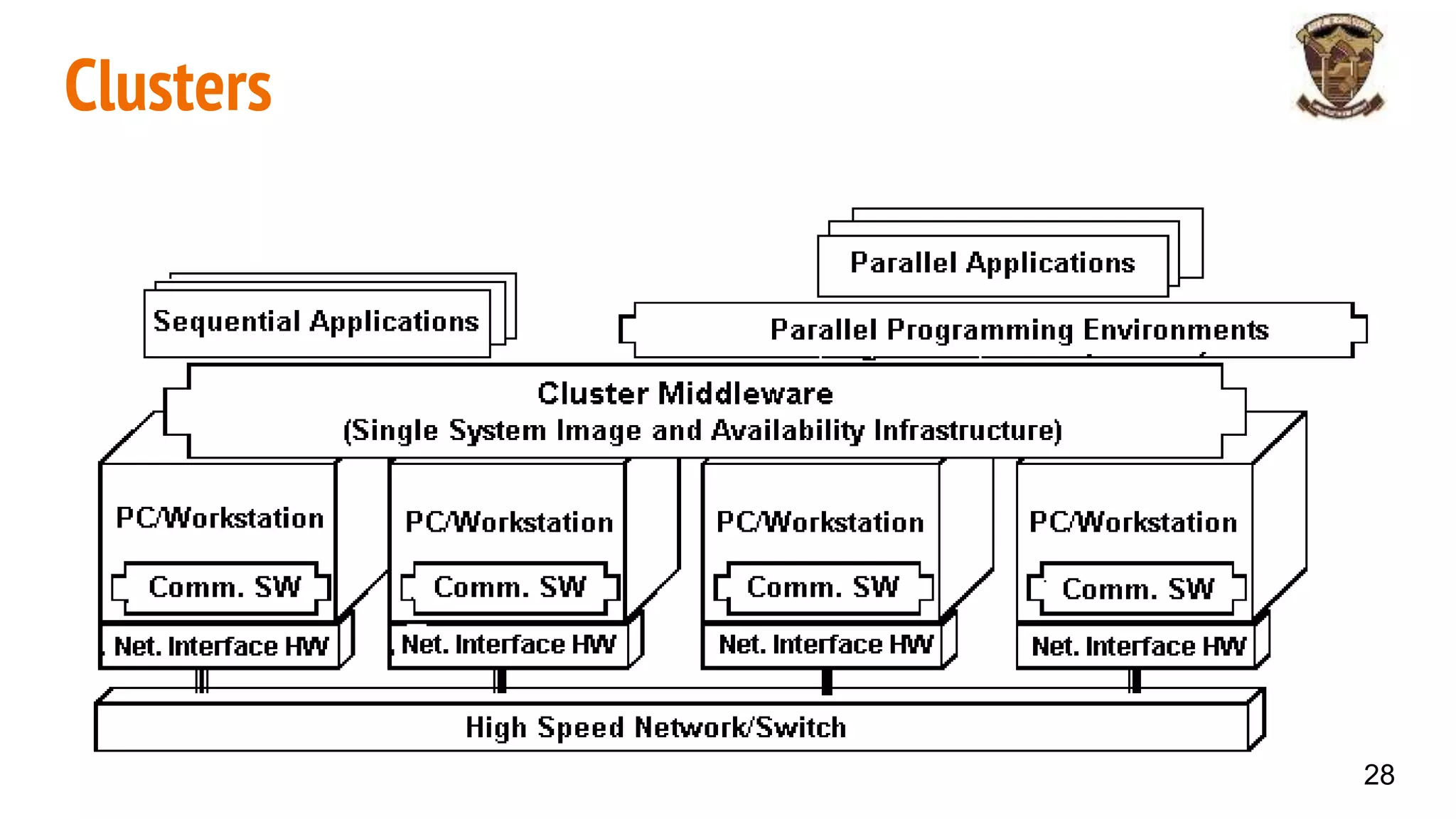
The document discusses distributed memory architecture (DM-MIMD) in computer science, highlighting its classification, communication techniques, and differences from shared memory architecture (SM-MIMD). It outlines the pros and cons of DM-MIMD regarding scalability, memory access, and programming complexity while also detailing types such as NUMA, MPP, and cluster architectures. Key points include the importance of message passing for communication and the challenges related to latency and bandwidth in accessing distributed memory.