Outline
• Shared MemoryArchitecture
– SMP Architectures (NUMA, ccNUMA)
– Cache & Cache Coherency Protocols
• Snoopy
• Directory Based
– What is Thread?
– What is Process?
– Thread vs. Process
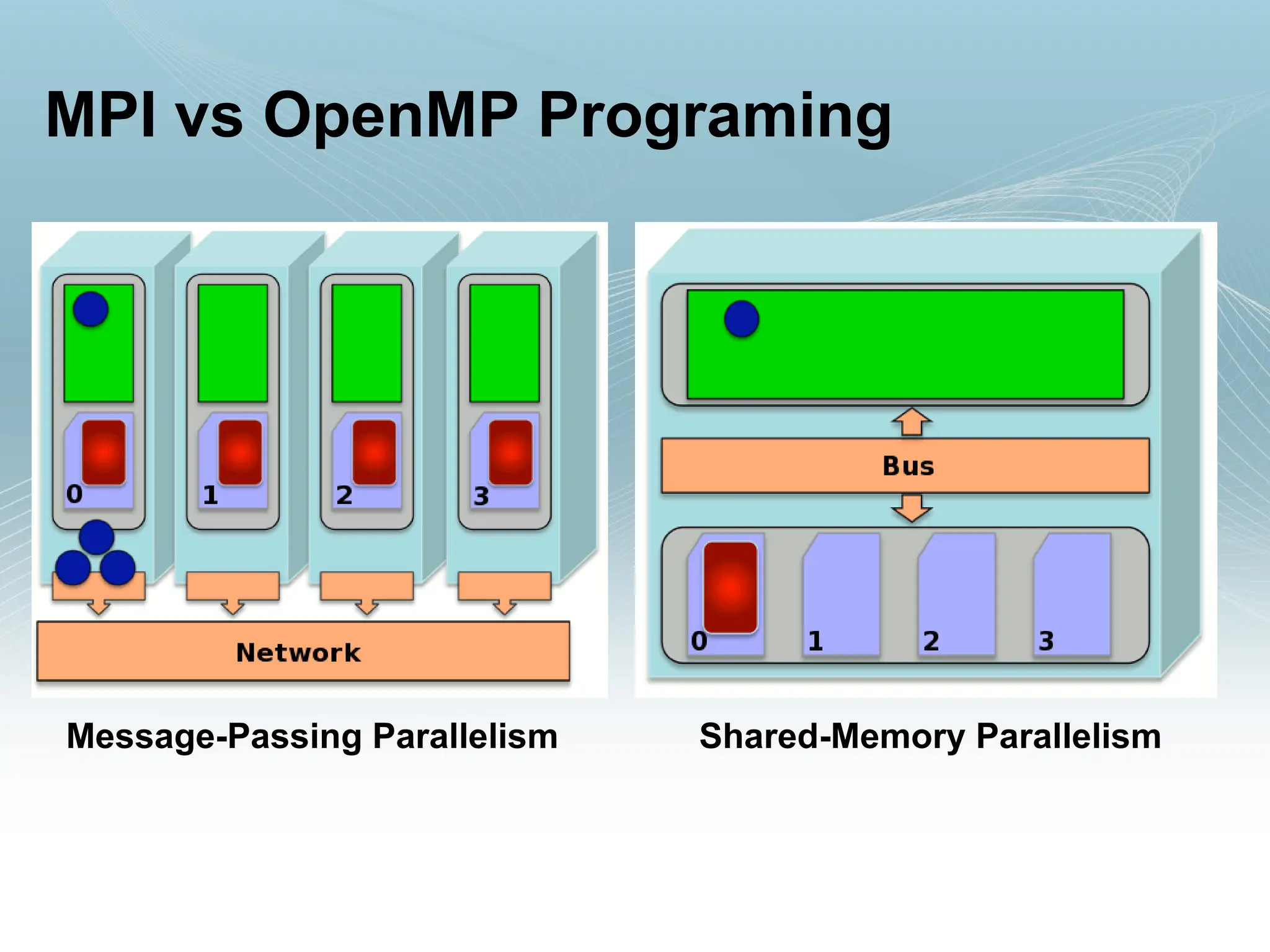
• OpenMP vs MPI
3.
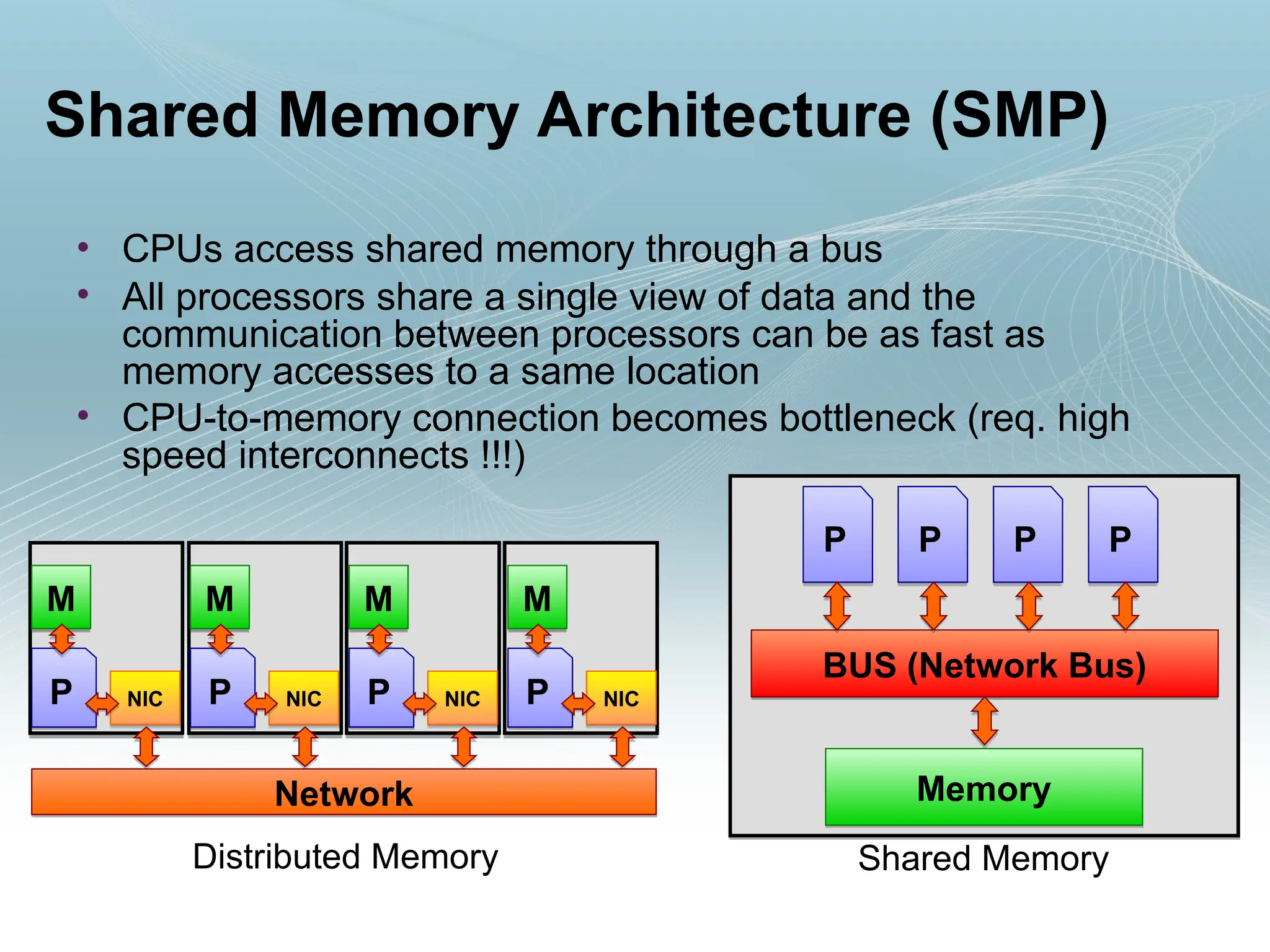
Shared Memory Architecture(SMP)
• CPUs access shared memory through a bus
• All processors share a single view of data and the
communication between processors can be as fast as
memory accesses to a same location
• CPU-to-memory connection becomes bottleneck (req. high
speed interconnects !!!)
Distributed Memory Shared Memory
P P P P
BUS (Network Bus)
Memory
Network
M
P NIC
M
P NIC
M
P NIC
M
P NIC
4.
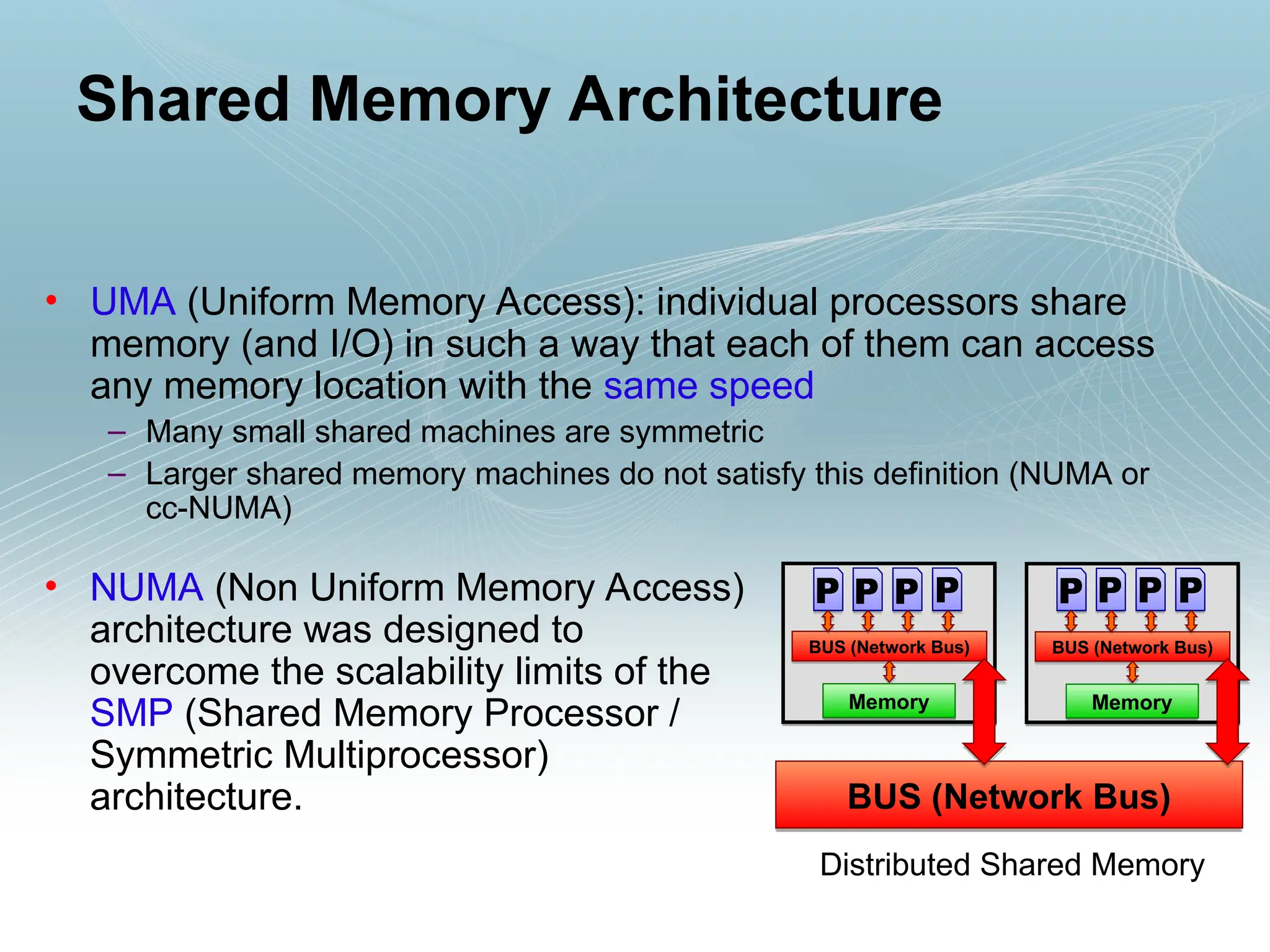
• UMA (UniformMemory Access): individual processors share
memory (and I/O) in such a way that each of them can access
any memory location with the same speed
– Many small shared machines are symmetric
– Larger shared memory machines do not satisfy this definition (NUMA or
cc-NUMA)
Shared Memory Architecture
• NUMA (Non Uniform Memory Access)
architecture was designed to
overcome the scalability limits of the
SMP (Shared Memory Processor /
Symmetric Multiprocessor)
architecture.
Distributed Shared Memory
BUS (Network Bus)
Memory
P
P P P
BUS (Network Bus)
Memory
P
P P P
BUS (Network Bus)
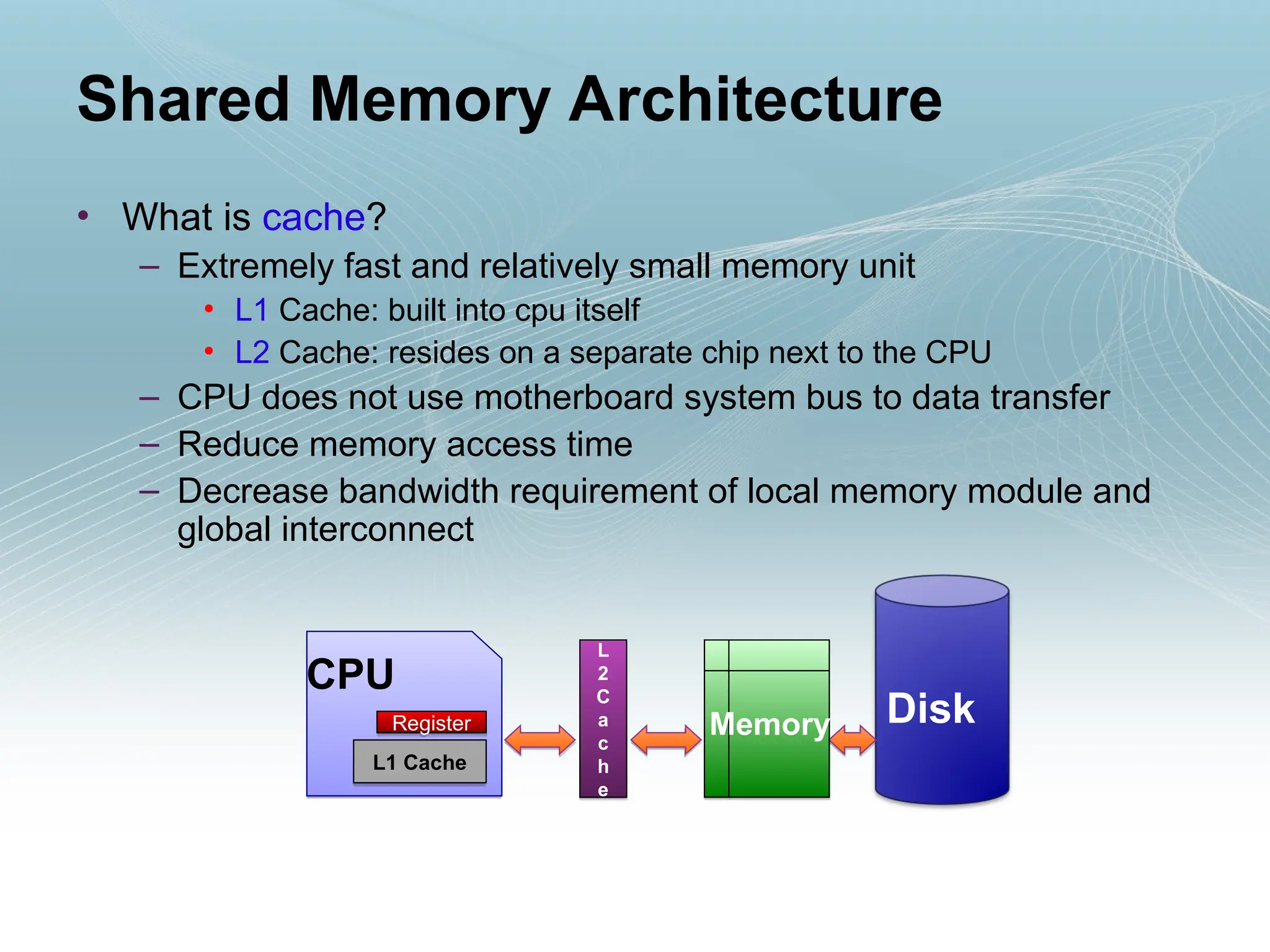
• What iscache?
– Extremely fast and relatively small memory unit
• L1 Cache: built into cpu itself
• L2 Cache: resides on a separate chip next to the CPU
– CPU does not use motherboard system bus to data transfer
– Reduce memory access time
– Decrease bandwidth requirement of local memory module and
global interconnect
Shared Memory Architecture
Register Disk
Memory
L1 Cache
L
2
C
a
c
h
e
CPU
8.
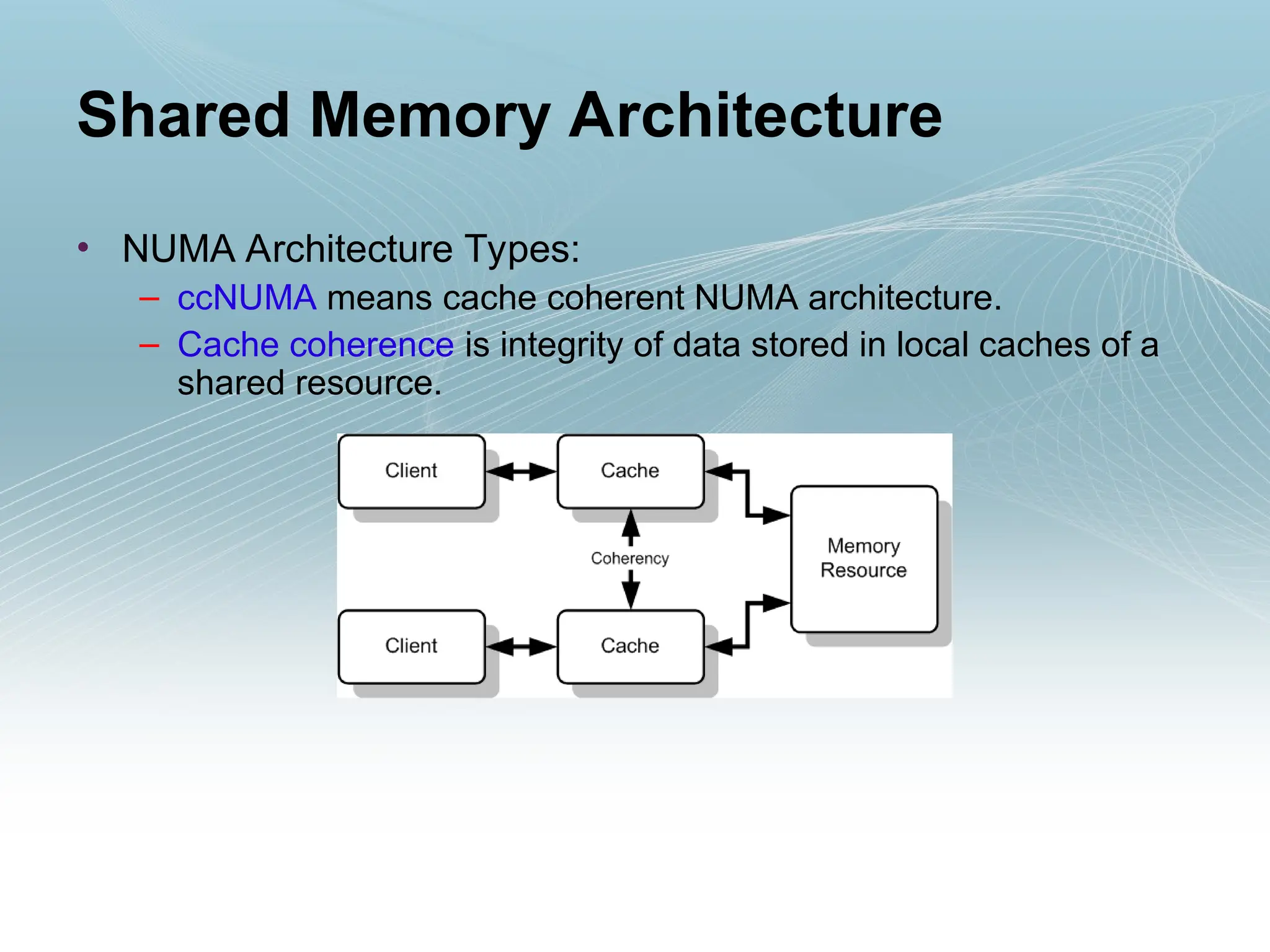
• NUMA ArchitectureTypes:
– ccNUMA means cache coherent NUMA architecture.
– Cache coherence is integrity of data stored in local caches of a
shared resource.
Shared Memory Architecture
9.
• Coherence definesthe behavior of reads and writes to the
same memory location.
– If each processor has a cache that reflects the state of various
parts of memory, it is possible that two or more caches may
have copies of the same line.
– If two threads make appropriately serialized changes to those
data items, the result could be that both caches end up with
different, incorrect versions of the line of memory.
– The system's state is no longer coherent !!!
Shared Memory Architecture
10.
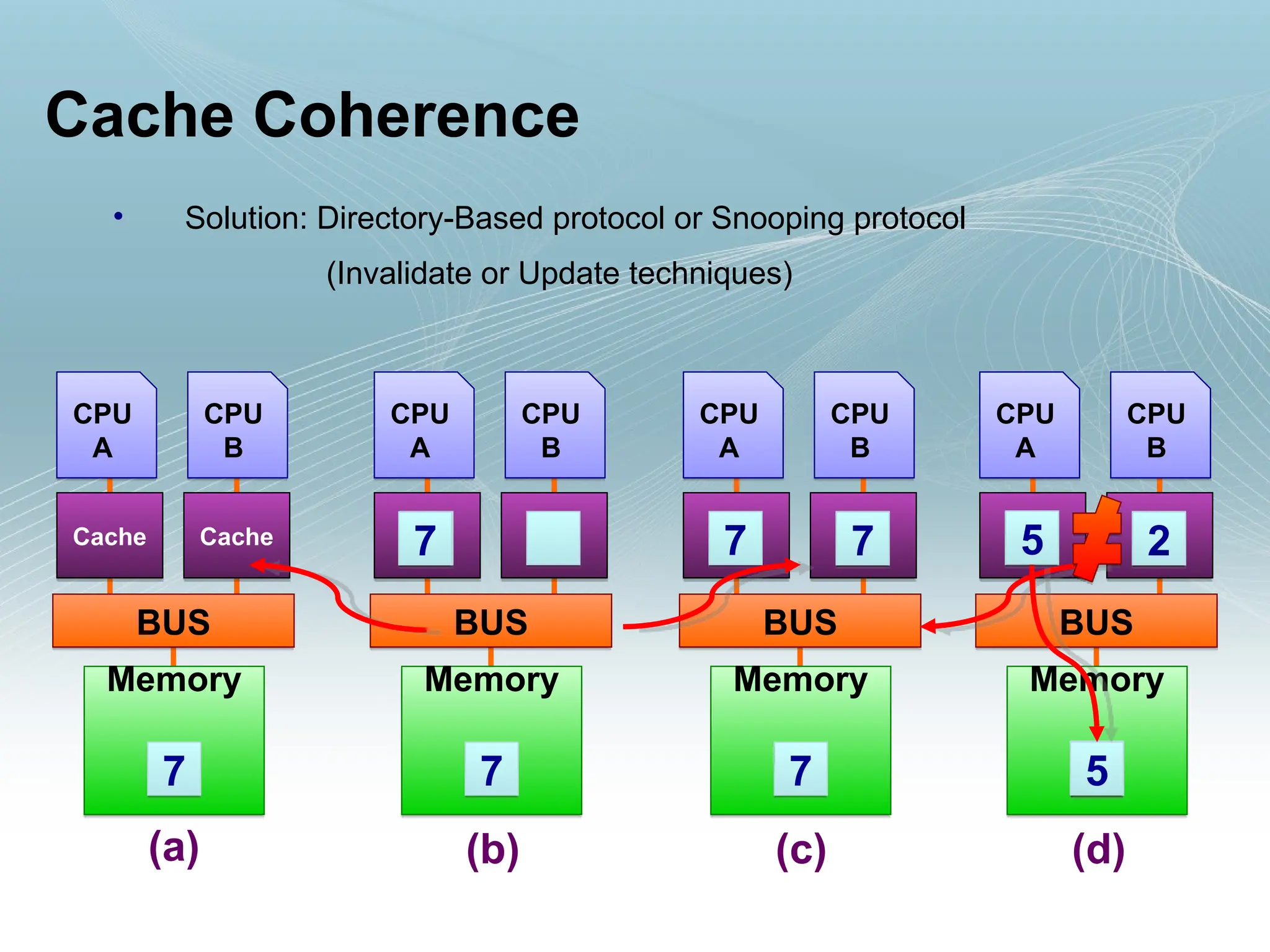
Cache Coherence
• Solution:Directory-Based protocol or Snooping protocol
(Invalidate or Update techniques)
Memory
2
5
CPU
A
BUS
Memory
Cache
CPU
B
Cache
7
(a) (b) (c) (d)
CPU
A
BUS
Memory
CPU
B
7
CPU
A
BUS
Memory
CPU
B
7
7
CPU
A
BUS
CPU
B
7 7
7 7 5 2
11.
• Solution: CacheCoherence Protocols !!!
• Protocols takes two kind of action when a cache line (L) is
written
– Invalidate all copies of L from the other cache of the machine
– They may update those lines with the new value being written
• Most modern cache coherent multiprocessors use
invalidation technique rather than update technique since it
is easier to implement in hardware
Shared Memory Architecture
12.
• Process
– Itis the "heaviest" unit of kernel scheduling.
– It is unit of allocation
– Processes execute independently. Interact with each other
via interprocess communication mechanisms
– Processes have own resources allocated by the operating
system. Resources include memory (address space) and
state information
– Own register set (temporary memory cell)
Main Definitions
13.
• Thread
– Itis the "lightest" unit of kernel scheduling.
– It is unit of execution
– At least one thread exists within each process. If multiple
threads can exist within a process, then they share the same
memory and file resources.
– Share address space, register set, process stack
– Threads do not own resources
Main Definitions
An execution entity having a serial flow of control, a set of
private variables, and access to shared variables.
OpenMP Review Board
14.
Process vs. Thread
It is a flow of control within a process.
It is a basic unit of CPU utilization.
It comprises of a thread ID, a program counter, a register set and a stack.
If the two threads belong to the same process , they share its code
section , data section and other operating system resource.
A traditional process has a single thread of control.
If the process has multiple threads of control, it can do more than one task
at a time.
Process
Thread
Thread
15.
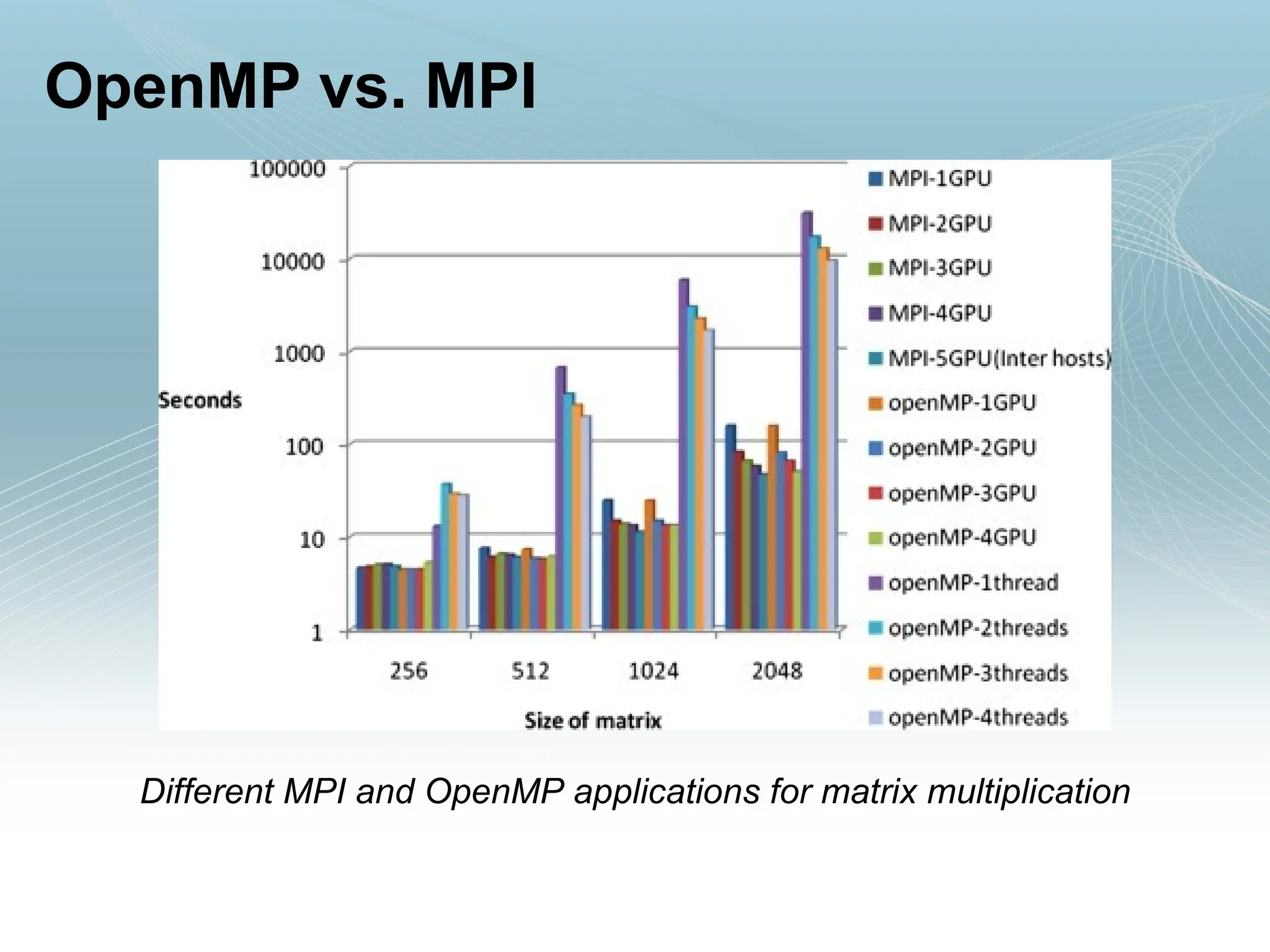
OpenMP vs. MPI
Prosof OpenMP
• considered by some to be easier to program and debug
(compared to MPI)
• data layout and decomposition is handled automatically by
directives.
• allows incremental parallelism: directives can be added
incrementally, so the program can be parallelized one portion after
another and thus no dramatic change to code is needed.
• unified code for both serial and parallel applications: OpenMP
constructs are treated as comments when sequential compilers
are used.
• original (serial) code statements need not, in general, be
modified when parallelized with OpenMP. This reduces the chance
of inadvertently introducing bugs and helps maintenance as well.
• both coarse-grained and fine-grained parallelism are possible
16.
OpenMP vs. MPI
Consof OpenMP
• currently only runs efficiently in shared-memory multiprocessor
platforms
• requires a compiler that supports OpenMP.
• scalability is limited by memory architecture.
• reliable error handling is missing.
• lacks fine-grained mechanisms to control thread-processor
mapping.
• synchronization between subsets of threads is not allowed.
• mostly used for loop parallelization
• can be difficult to debug, due to implicit communication between
threads via shared variables.
17.
OpenMP vs. MPI
Prosof MPI
• does not require shared memory architectures which are more
expensive than distributed memory architectures
• can be used on a wider range of problems since it exploits both
task parallelism and data parallelism
• can run on both shared memory and distributed memory
architectures
• highly portable with specific optimization for the implementation on
most hardware
18.
OpenMP vs. MPI
Consof MPI
• requires more programming changes to go from serial to parallel
version
• can be harder to debug












































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













