


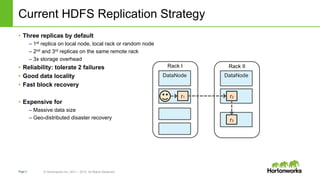

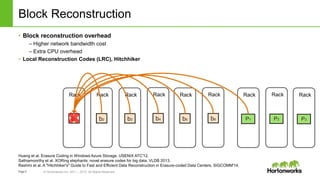
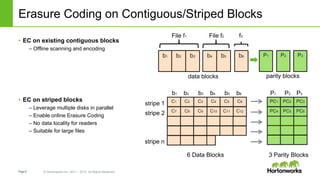
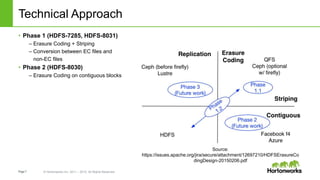
![Page9 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Erasure Coding Zone
• Create a zone on an empty directory
– Shell command: hdfs erasurecode –createZone [-s <schemaName>] <path>
• All the files under a zone directory are automatically erasure coded
– Rename across zones with different EC schemas are disallowed](https://image.slidesharecdn.com/june10525pmhortonworksszezhao-150619220712-lva1-app6891/85/HDFS-Erasure-Code-Storage-Same-Reliability-at-Better-Storage-Efficiency-9-320.jpg)
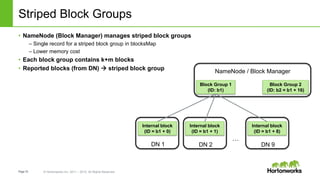
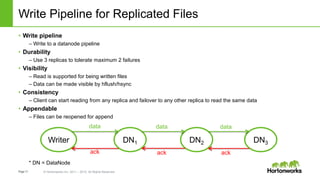

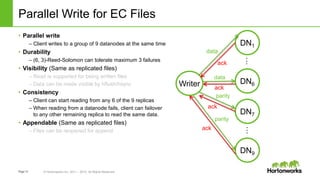
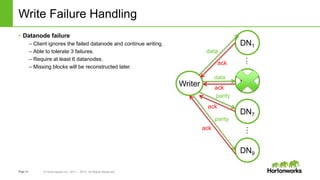
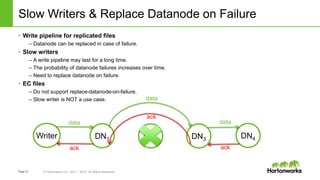
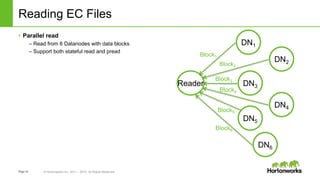
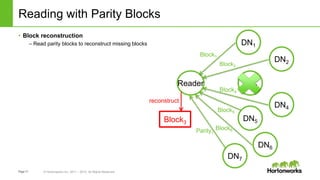
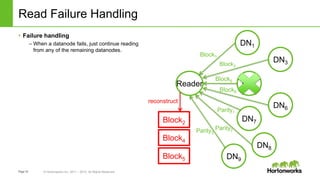










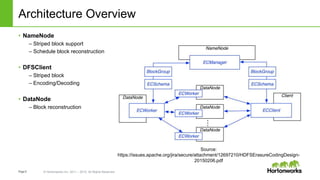
The document discusses HDFS erasure coding storage, which provides the same reliability as HDFS replication but with better storage efficiency. It describes HDFS's current replication strategy and introduces erasure coding as an alternative. Erasure coding uses k data blocks and m parity blocks to tolerate m failures while using less storage than replication. The document outlines HDFS's technical approach to implementing erasure coding, including striped block encoding, reading and writing pipelines, and reconstruction of missing blocks. It provides details on architecture, development progress, and future work to further enhance erasure coding in HDFS.










































































































