Downloaded 380 times












![1
7
© Hortonworks Inc. 2011 – 2016. All Rights Reserved
Erasure Coding Zone
⬢ Create a zone on an empty directory
– Shell command: hdfs erasurecode –createZone [-s <schemaName>] <path>
⬢ All the files under a zone directory are automatically erasure
coded
– Rename across zones with different EC schemas are disallowed](https://image.slidesharecdn.com/april51410hortonworksradia-170410125621/85/Hadoop-3-in-a-Nutshell-17-320.jpg)

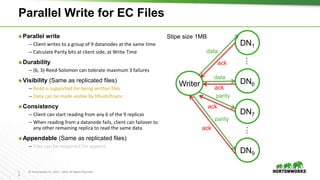
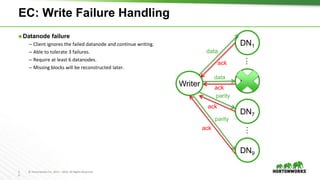
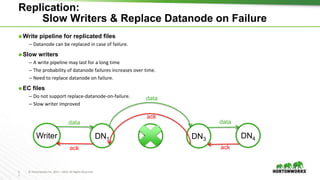
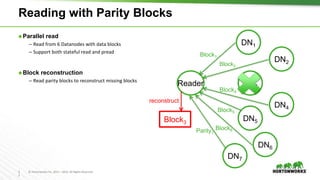














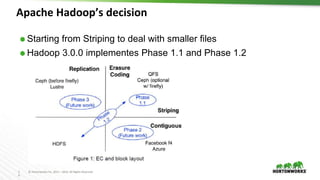
The document outlines the key features and changes introduced in Apache Hadoop 3.0, including the implementation of erasure coding, long-running service support via YARN, and various enhancements in scheduling and resource management. It discusses the requirements for upgrading, such as the minimum Java Development Kit (JDK) version and default port changes for Hadoop services. The timeline for the release of Hadoop 3.0 is also mentioned, highlighting its development progression from alpha to anticipated beta and general availability.
























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

















