Downloaded 114 times











![18 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Erasure Coding Zone
Create a zone on an empty directory
– Shell command:
hdfs erasurecode –createZone [-s <schemaName>] <path>
All the files under a zone directory are automatically erasure coded
– Rename across zones with different EC schemas are disallowed](https://image.slidesharecdn.com/sanjayradiaapachehadoop3-170921004926/85/Apache-Hadoop-3-0-Community-Update-14-320.jpg)


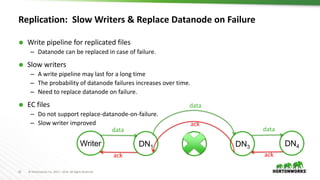
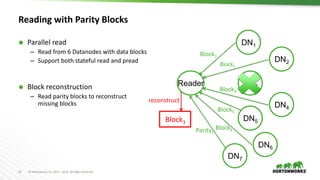
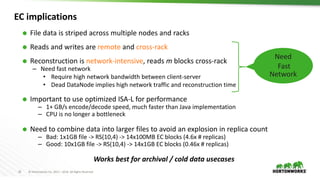
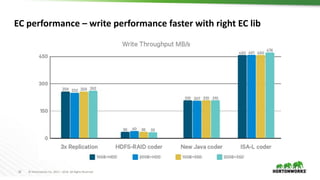
















The document outlines the major updates and new features in Apache Hadoop 3.0, which include enhanced functionality like erasure coding in HDFS, long-running service support in YARN, and a requirement for JDK 8 or later. It discusses changes in default port settings, classpath isolation, and various scheduling enhancements aimed at improving resource utilization and user experience. The community effort behind the development of Hadoop 3.0 and its planned release timeline are also highlighted.






















































































