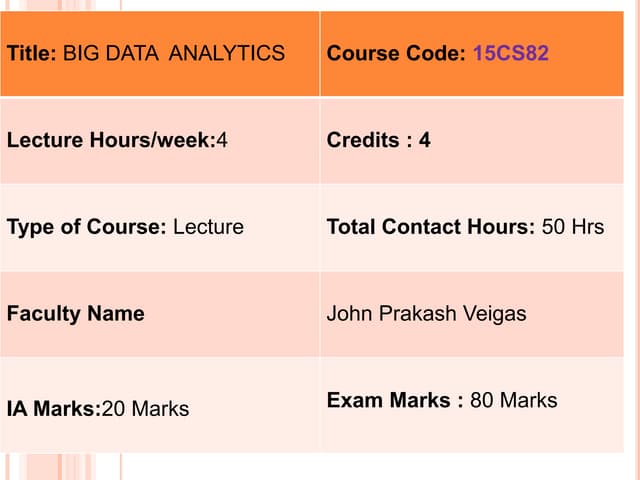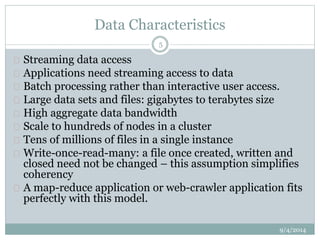



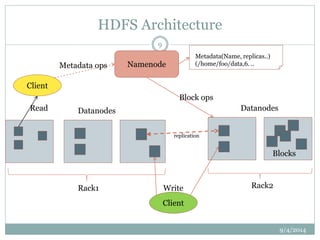




























The document describes the key features and architecture of the Hadoop Distributed File System (HDFS). HDFS is designed to reliably store very large data sets across clusters of commodity hardware. It uses a master/slave architecture with a single NameNode that manages file system metadata and regulates client access. Numerous DataNodes store file system blocks and replicate data for fault tolerance. The document outlines HDFS properties like high fault tolerance, data replication, and APIs.