


)
Instant schema and partition evolution
ALTER TABLE t1 ADD/DROP/MODIFY/RENAME COLUMN c1 ...
ALTER TABLE t1 ADD/DROP PARTITION FIELD ...
Time travel
SELECT * FROM t1 AT/BEFORE <timestamp>](https://image.slidesharecdn.com/20230215-mdsfrdremioopendatalakehouse-230223050241-aaf1eca7/75/From-Data-Warehouse-to-Lakehouse-8-2048.jpg)
















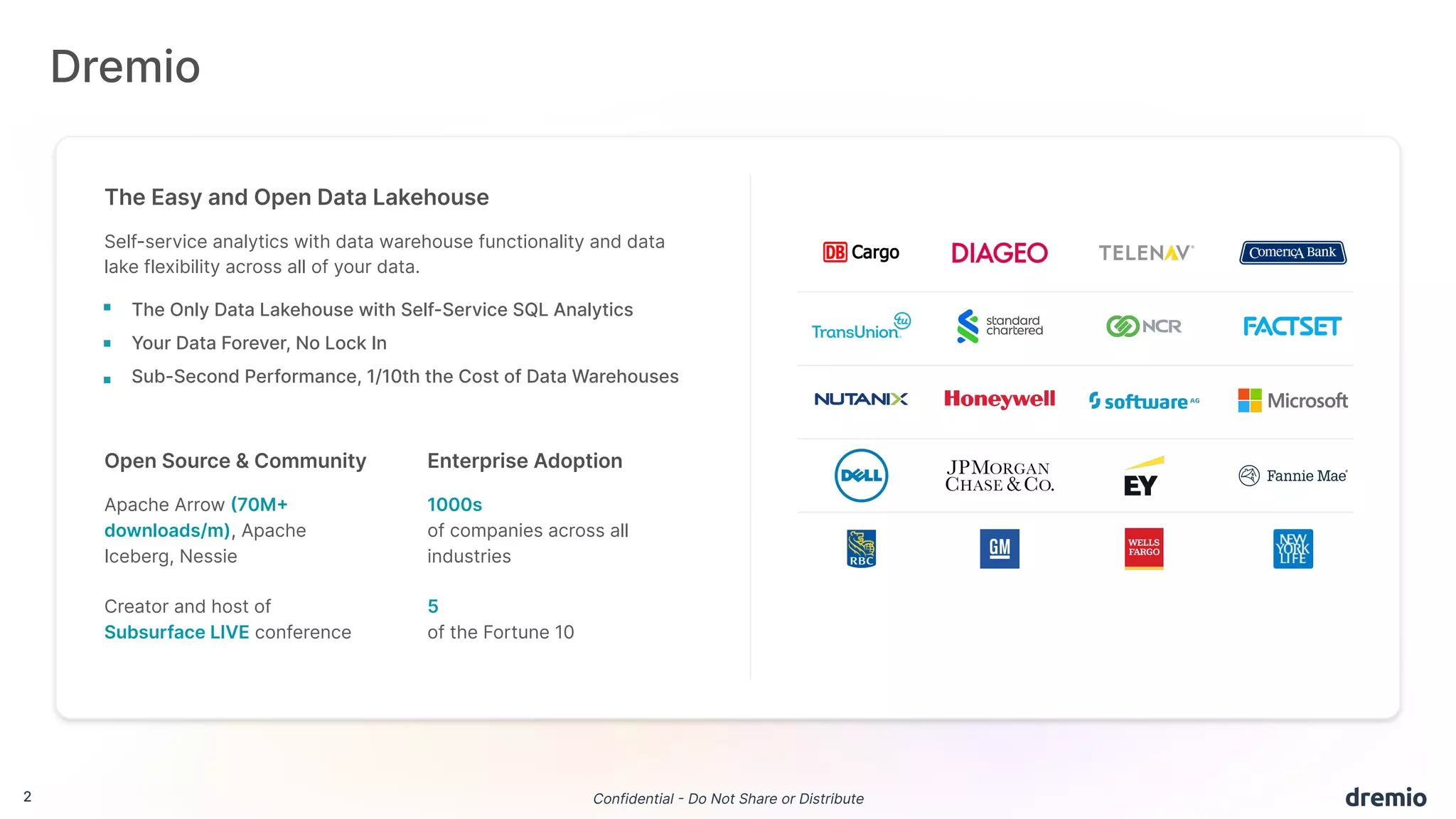
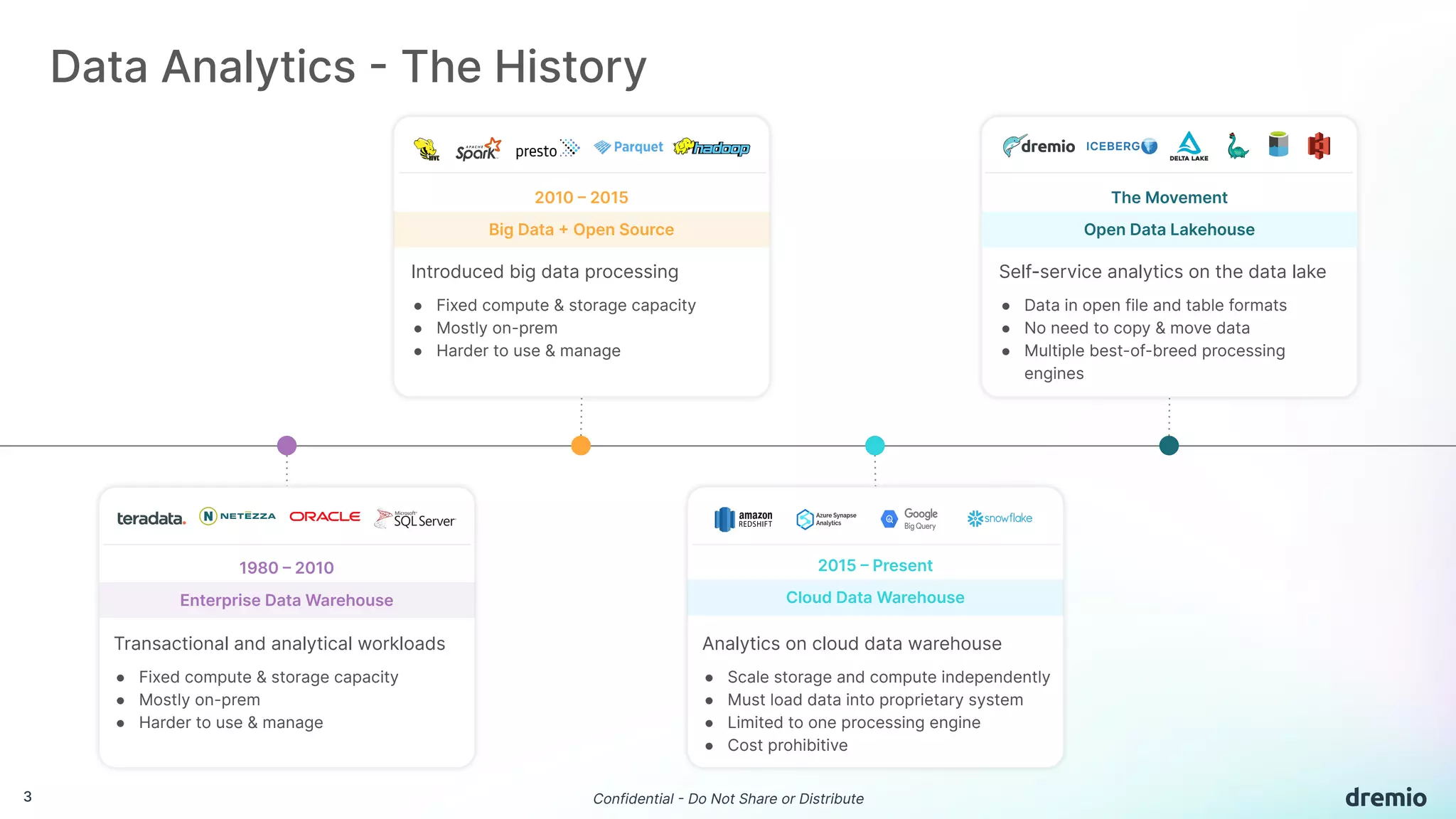
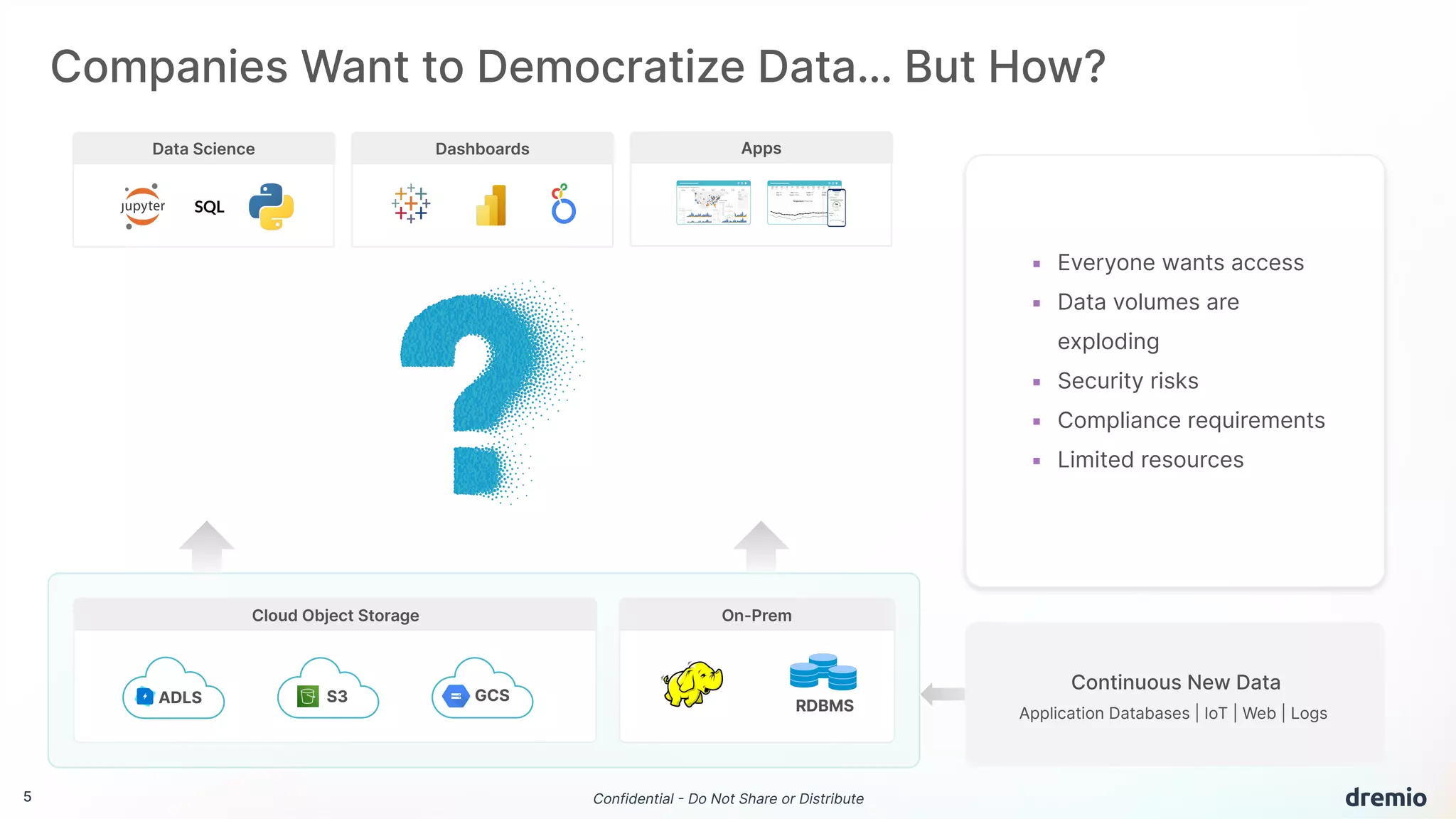
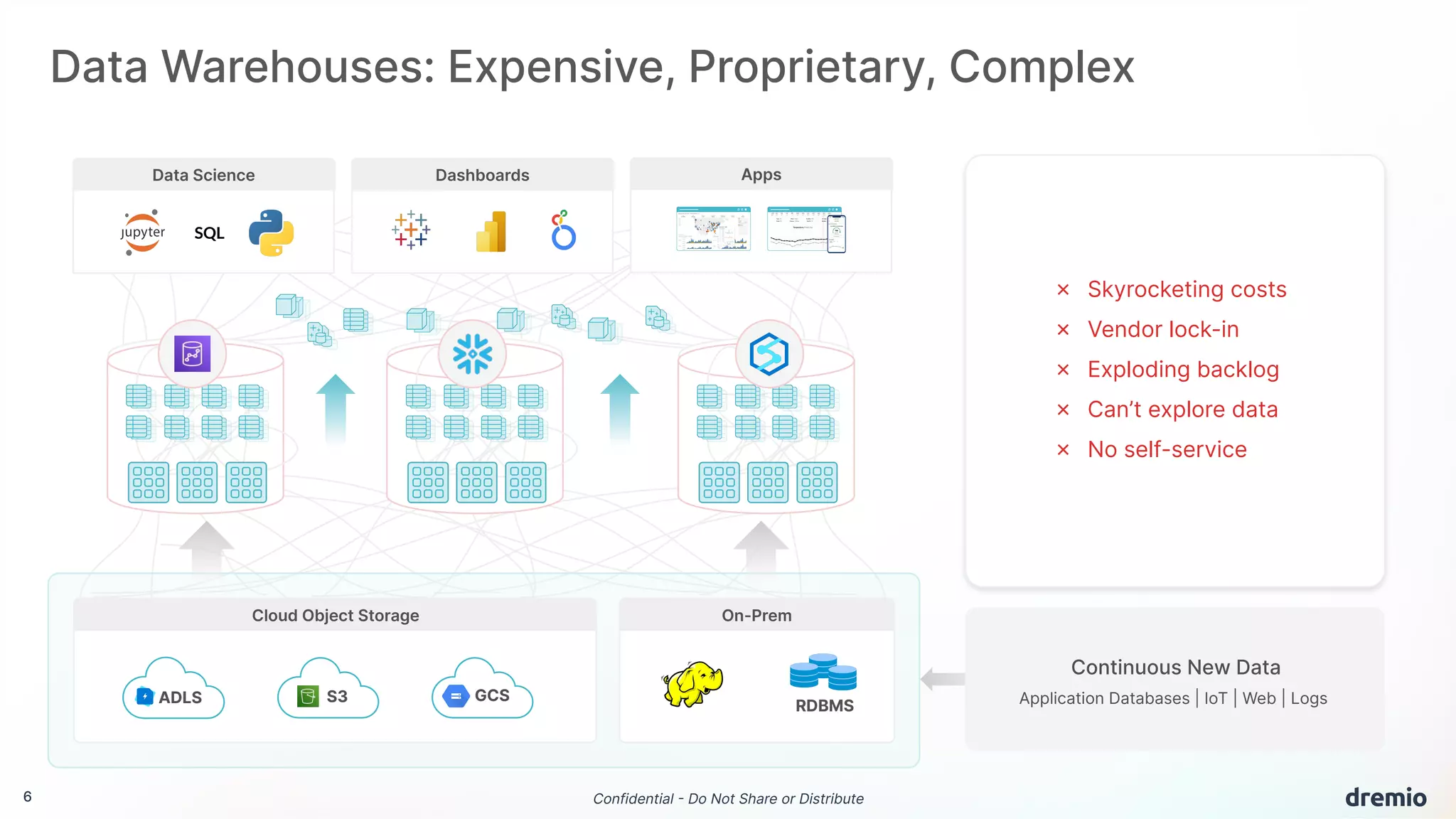
The document discusses the evolution and advantages of Dremio's data lakehouse solution, which provides self-service analytics at a significantly lower cost compared to traditional data warehouses. It highlights key features such as sub-second performance, elimination of data silos, and support for open-source technologies like Apache Iceberg. Additionally, it outlines the platform's capabilities for managing data versions, optimizing queries, and controlling access in a collaborative environment.
![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DSC Europe 22] Overview of the Databricks Platform - Petar Zecevic](https://cdn.slidesharecdn.com/ss_thumbnails/petarzecevic-databricksoverview-221130080703-c60d93de-thumbnail.jpg?width=640&height=640&fit=bounds)








































































