Downloaded 860 times


















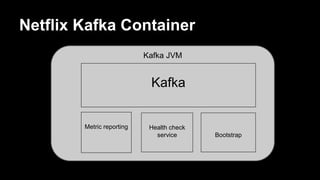







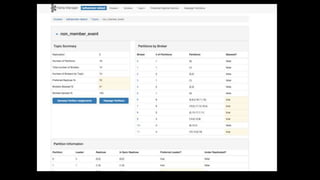











![Effect of batching
partitioner batched records
per request
broker cpu util
[1]
random without
lingering
1.25 75%
sticky without
lingering
2.0 50%
sticky with 100ms
lingering
15 33%
[1] 10 MB & 10K msgs / second per broker, 1KB per message](https://image.slidesharecdn.com/netflix-kafka-150325105558-conversion-gate01/85/Netflix-Data-Pipeline-With-Kafka-45-320.jpg)





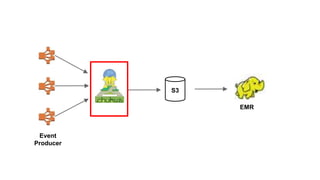
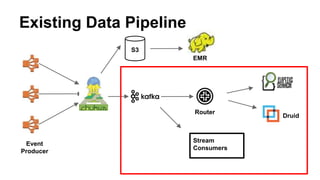
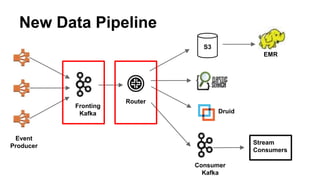
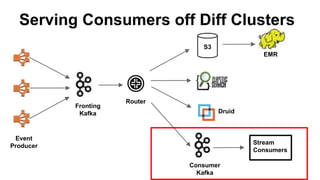
This document summarizes Netflix's use of Kafka in their data pipeline. It discusses how Netflix evolved from using S3 and EMR to introducing Kafka and Kafka producers and consumers to handle 400 billion events per day. It covers challenges of scaling Kafka clusters and tuning Kafka clients and brokers. Finally, it outlines Netflix's roadmap which includes contributing to open source projects like Kafka and testing failure resilience.



































































