Downloaded 39 times





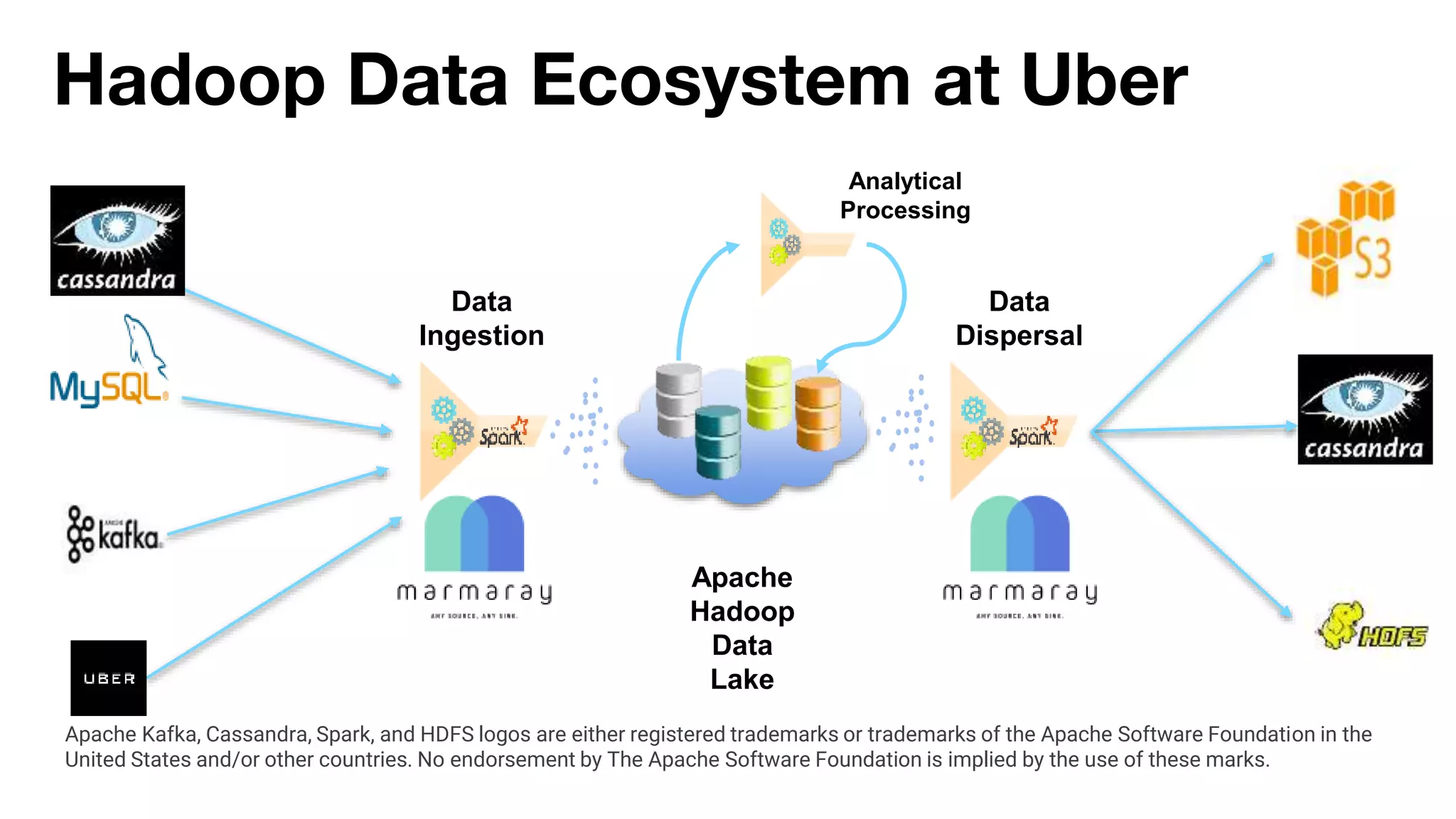
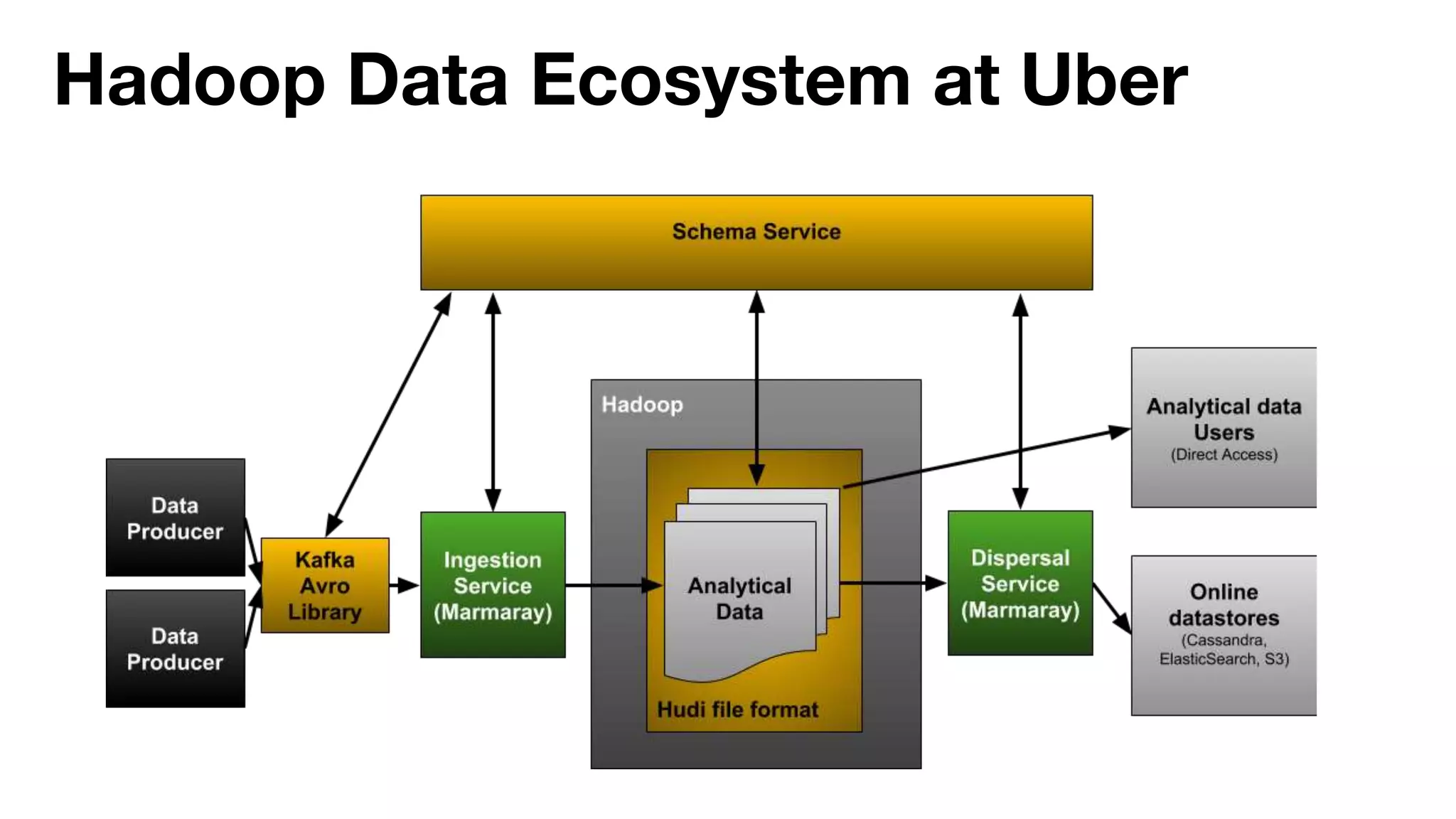



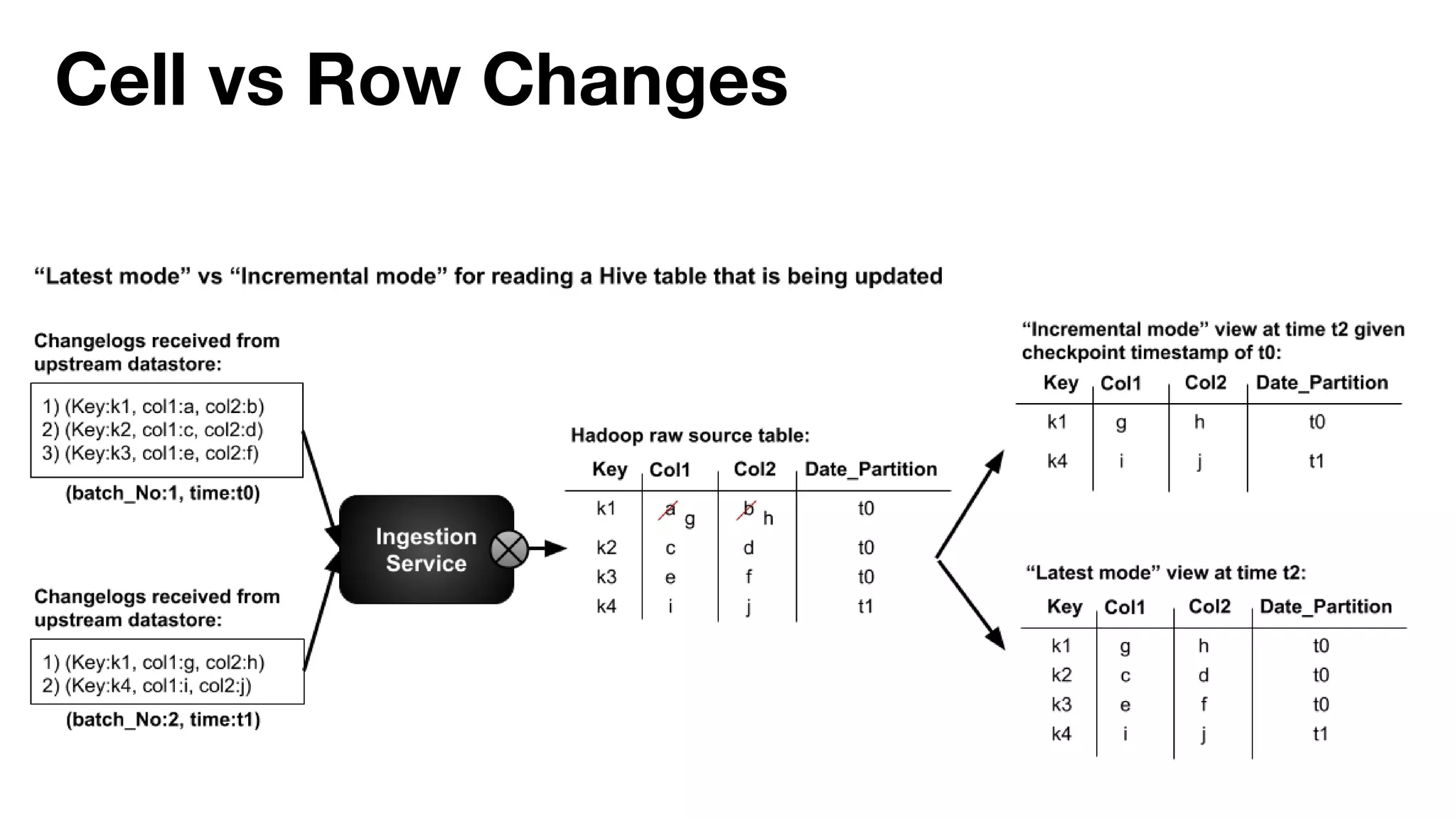




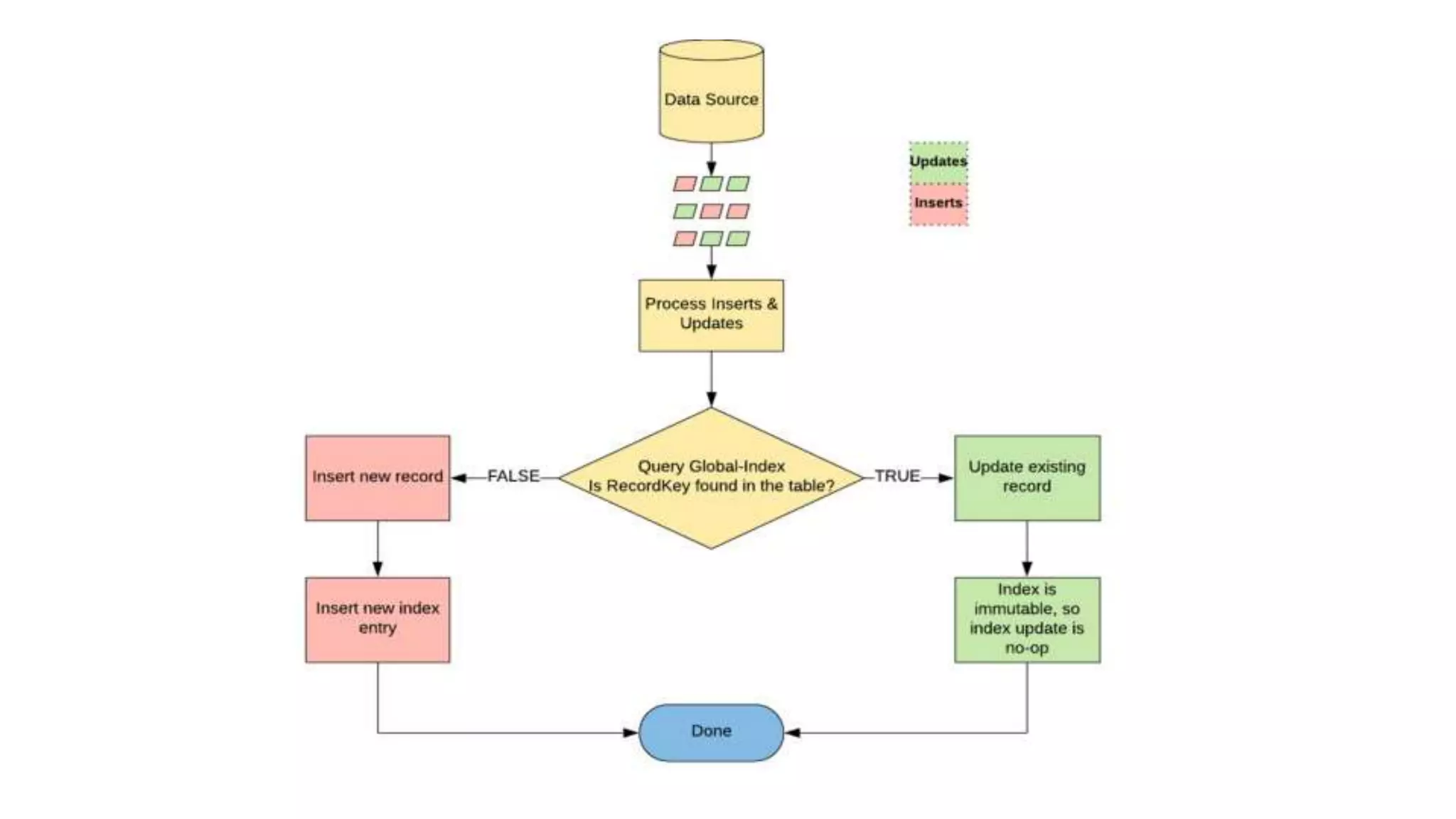
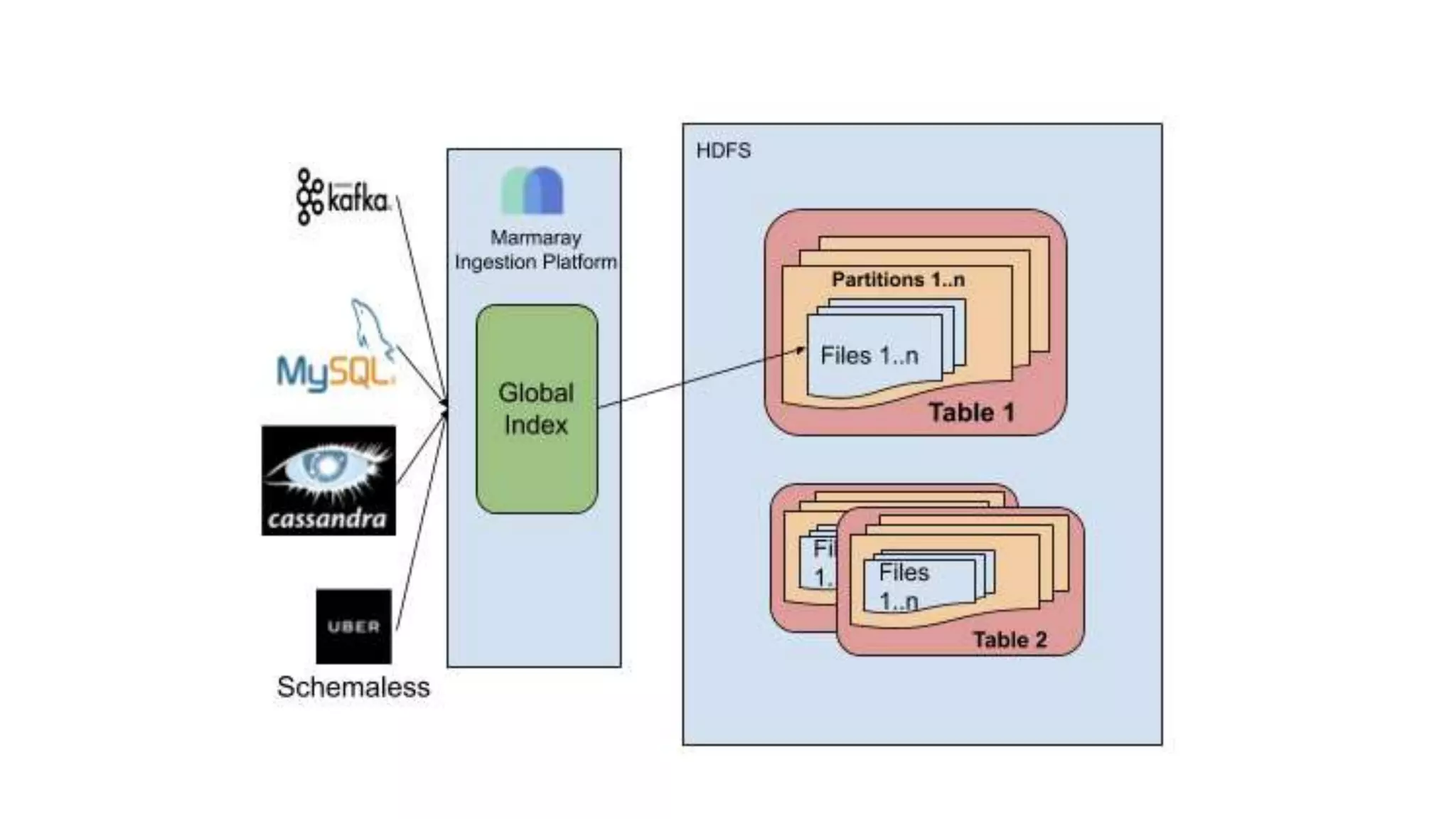

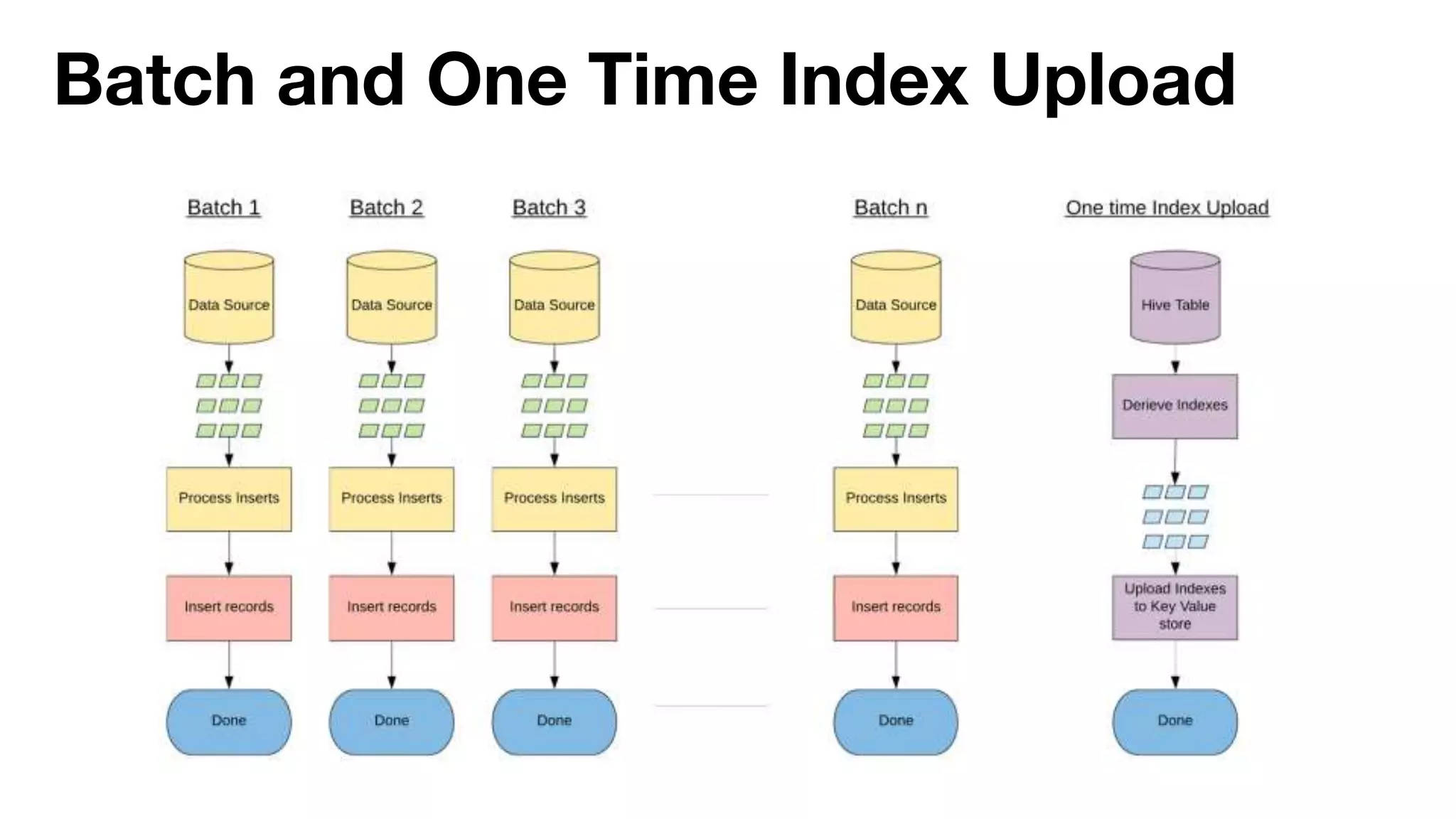
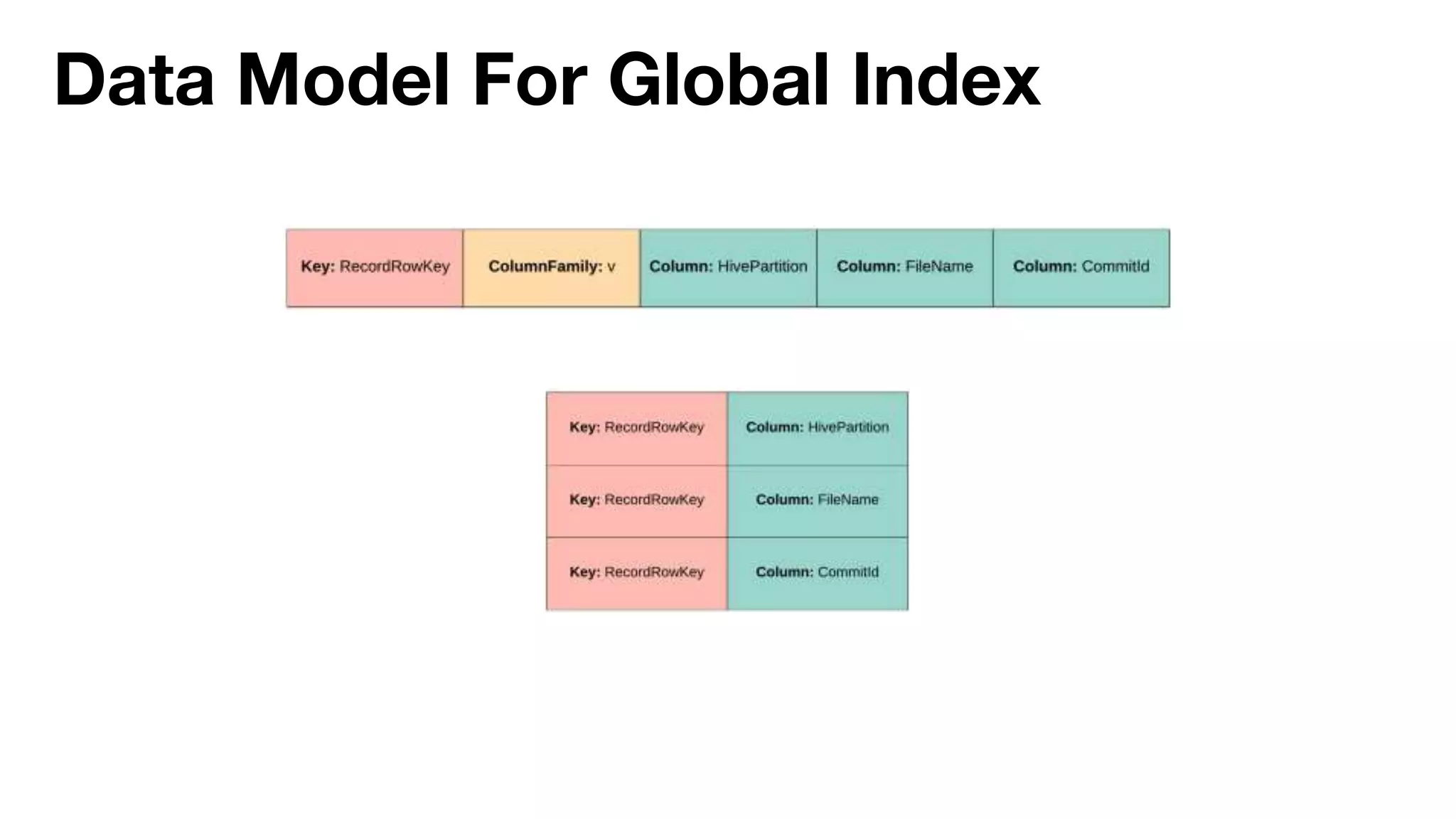

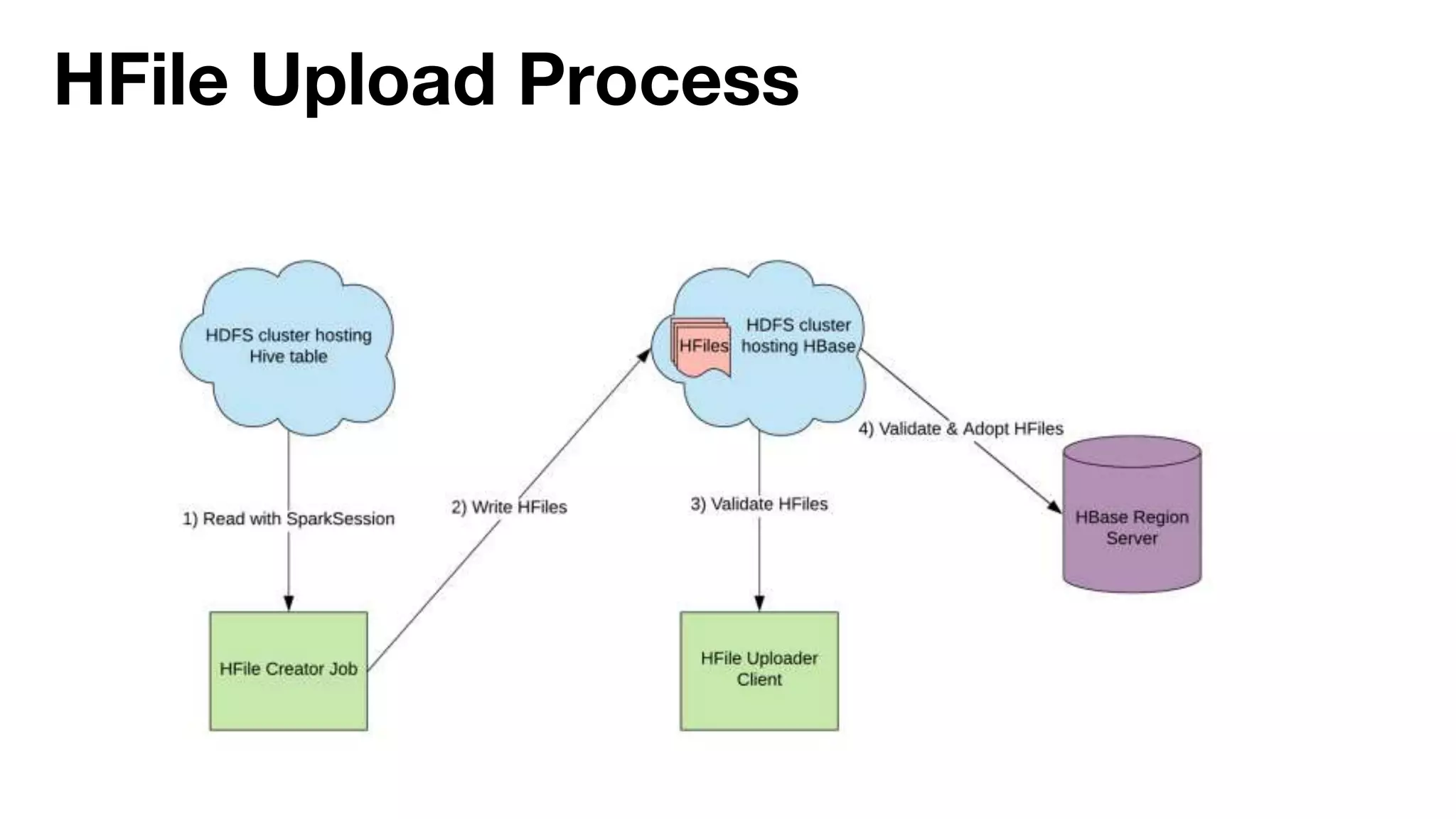


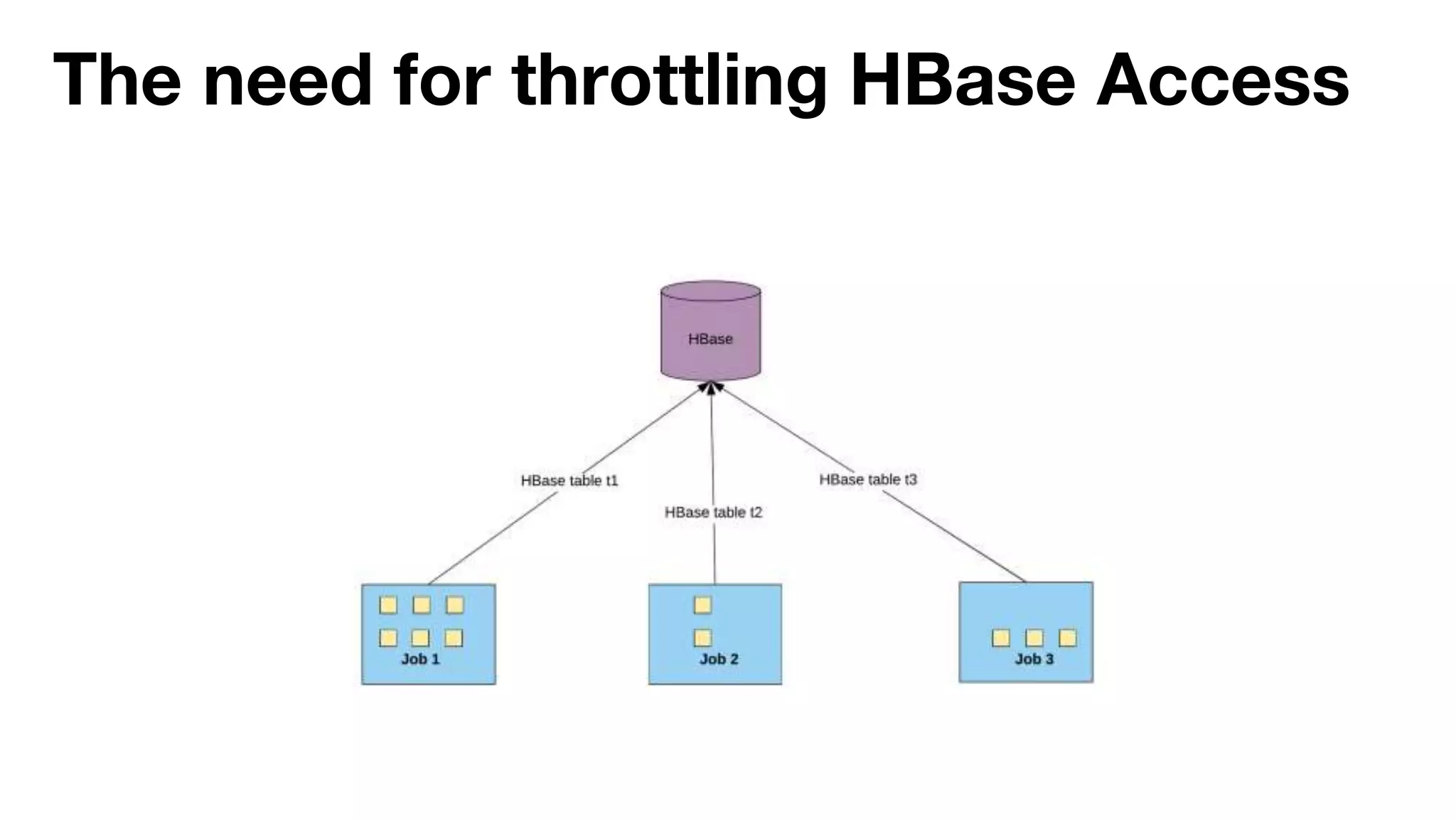
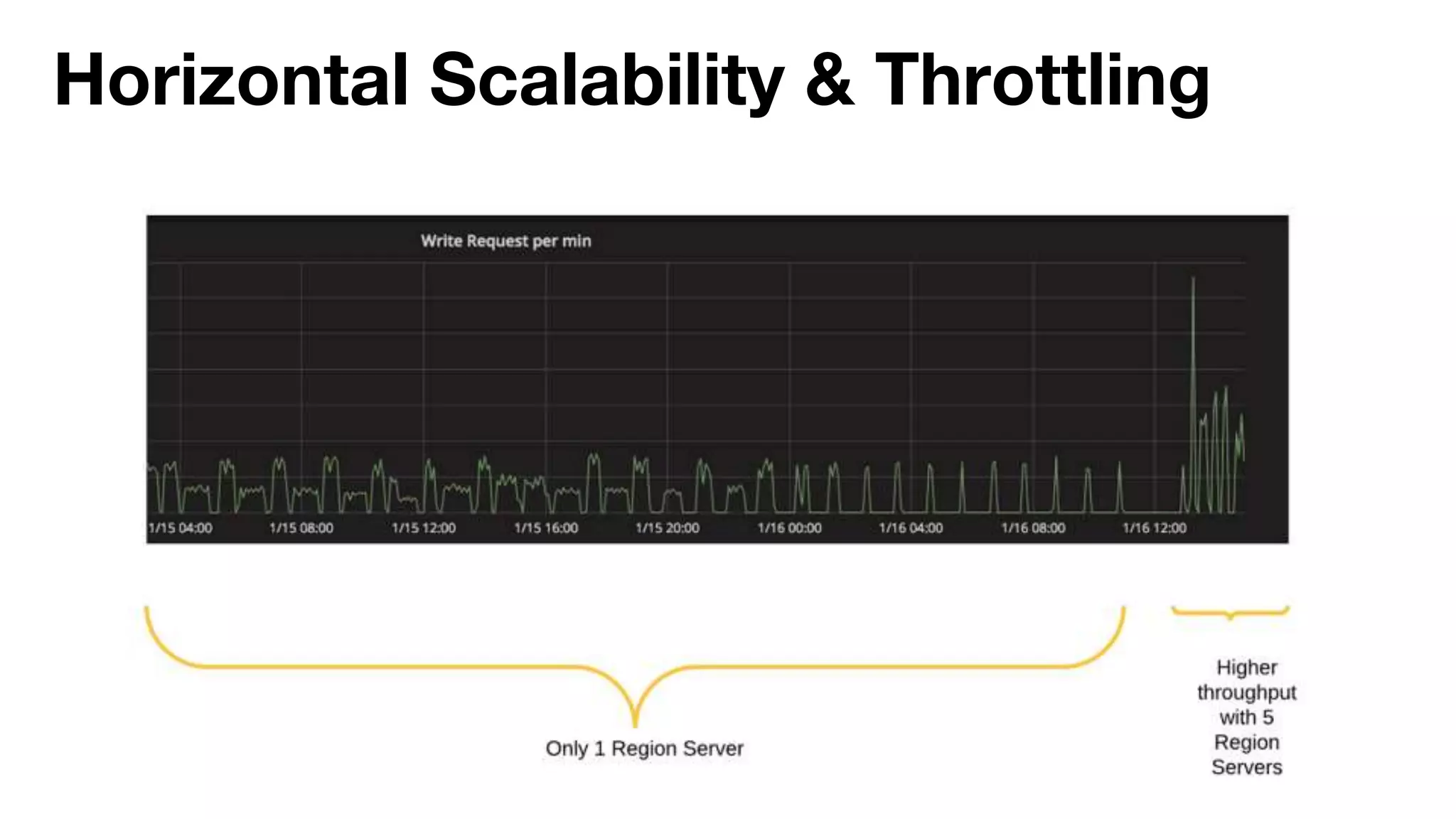








Danny Chen presented on Uber's use of HBase for global indexing to support large-scale data ingestion. Uber uses HBase to provide a global view of datasets ingested from Kafka and other data sources. To generate indexes, Spark jobs are used to transform data into HFiles, which are loaded into HBase tables. Given the large volumes of data, techniques like throttling HBase access and explicit serialization are used. The global indexing solution supports requirements for high throughput, strong consistency and horizontal scalability across Uber's data lake.






















































































