Download as PDF, PPTX



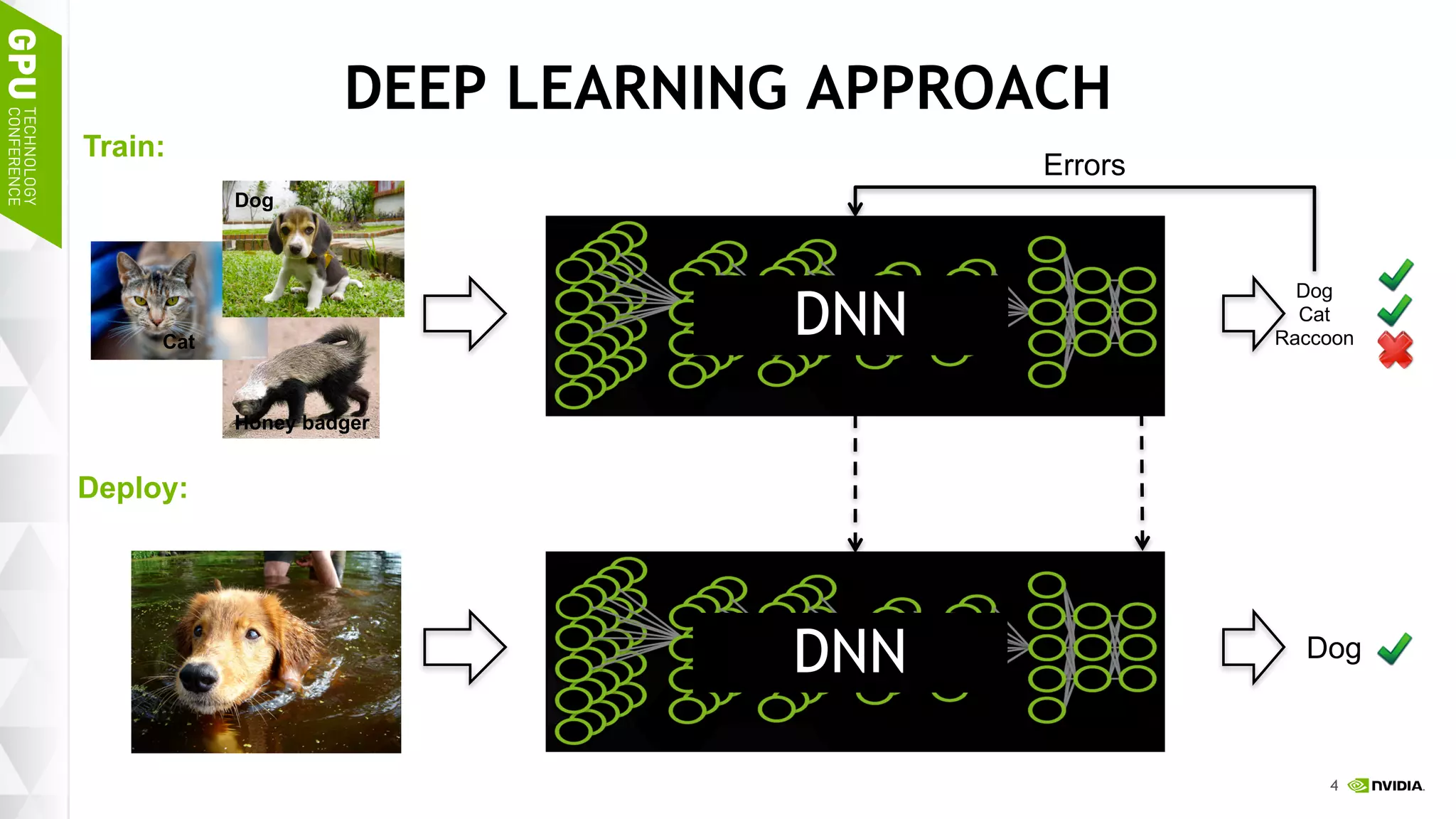
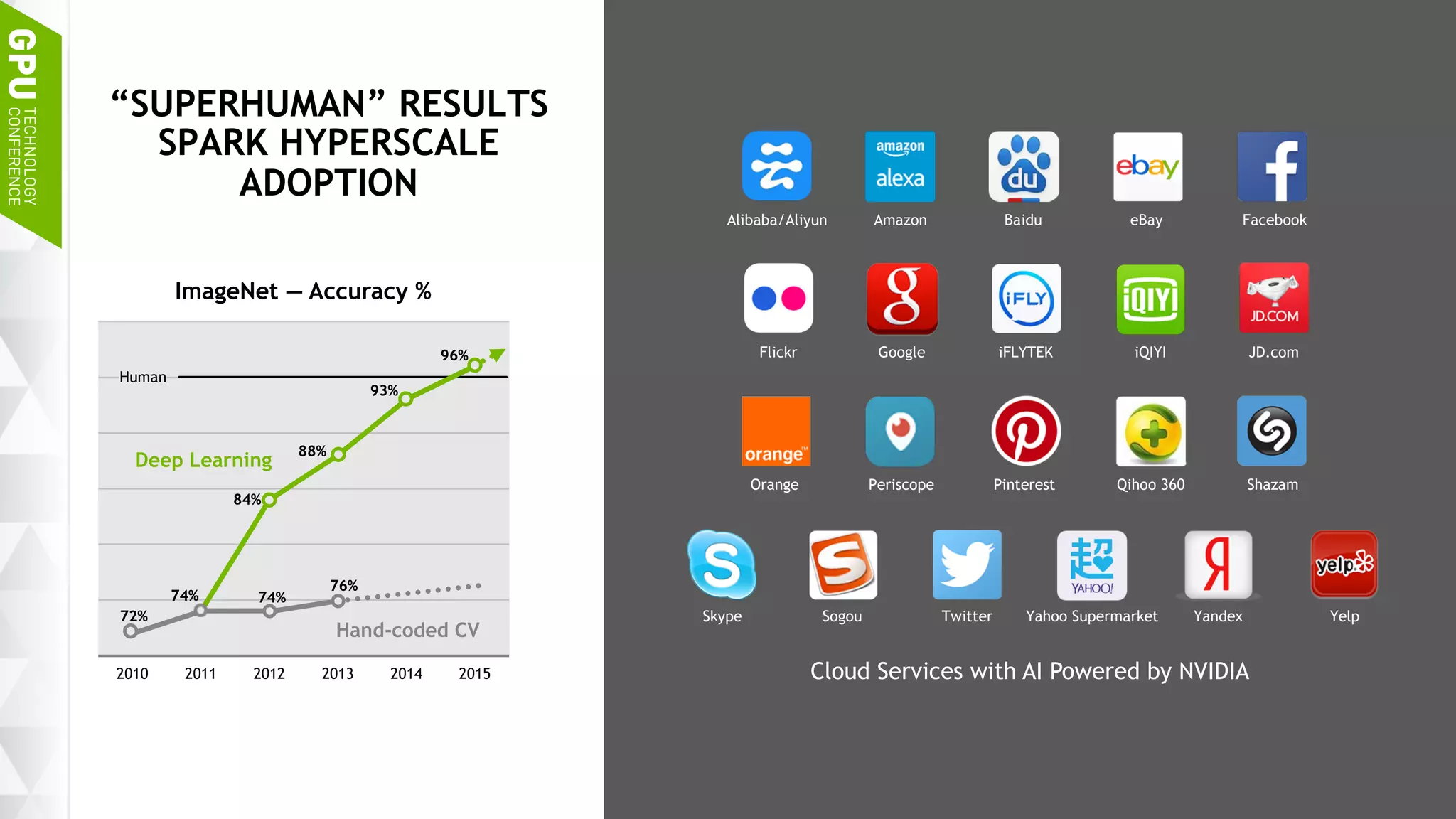




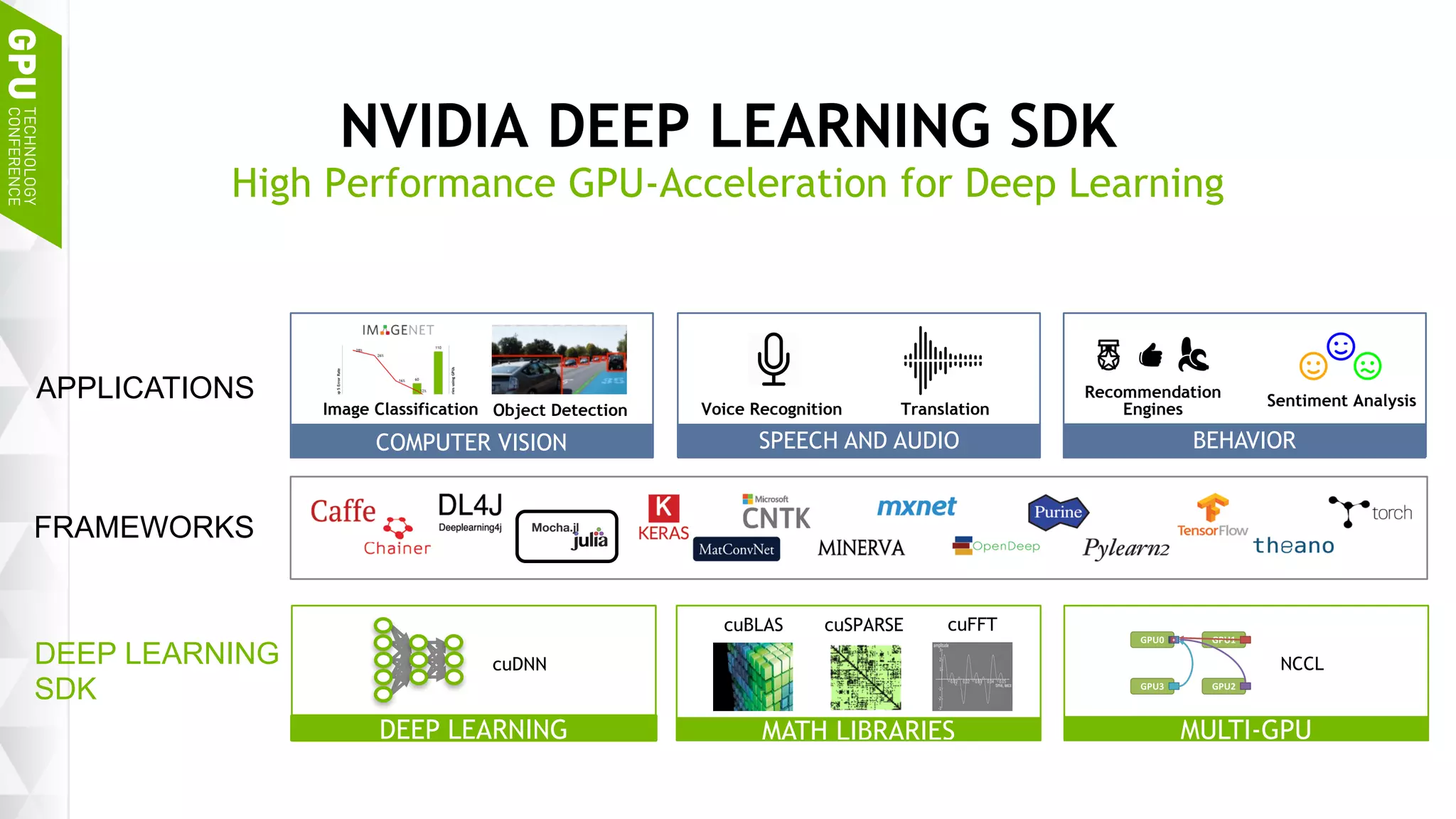
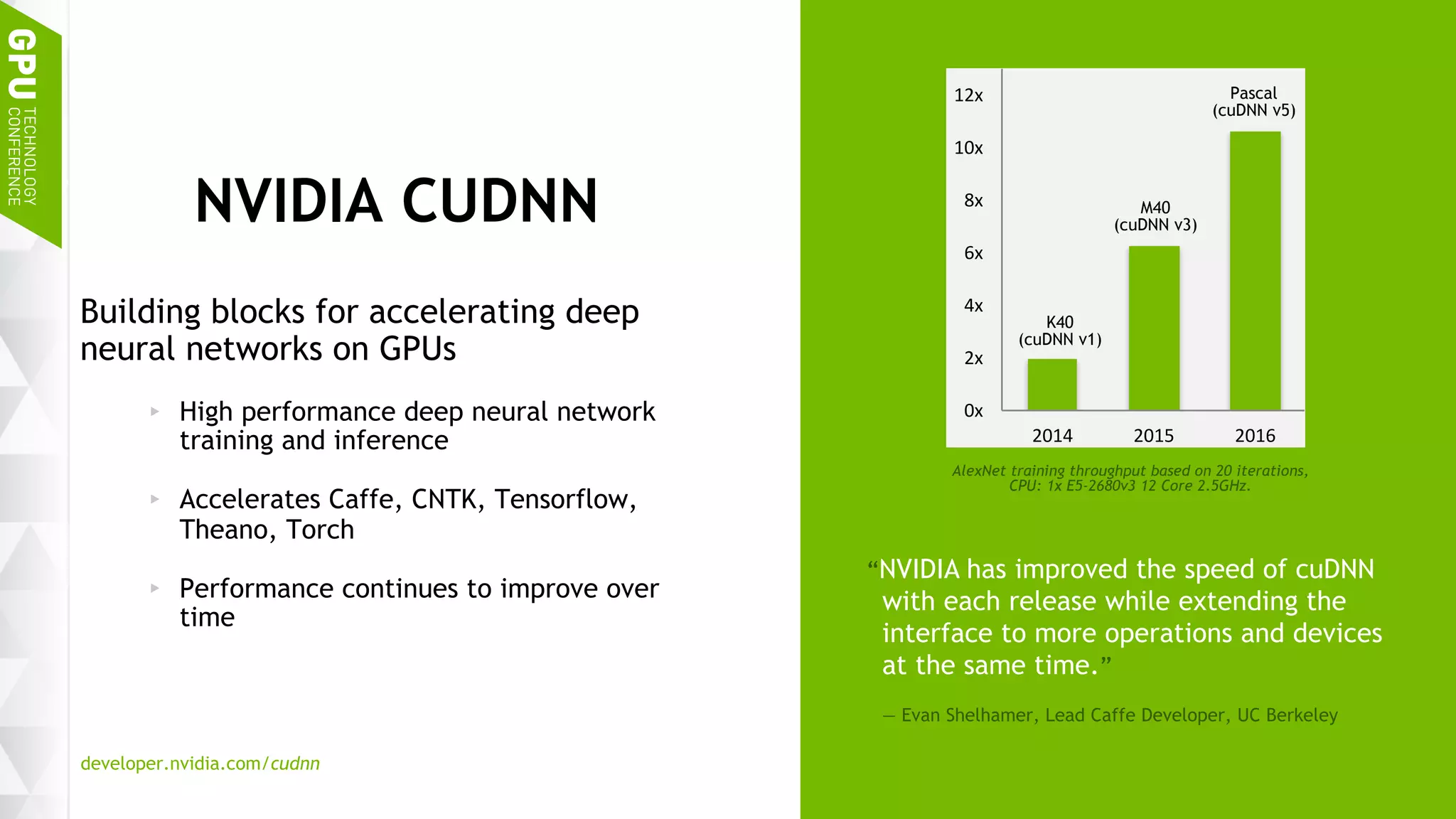

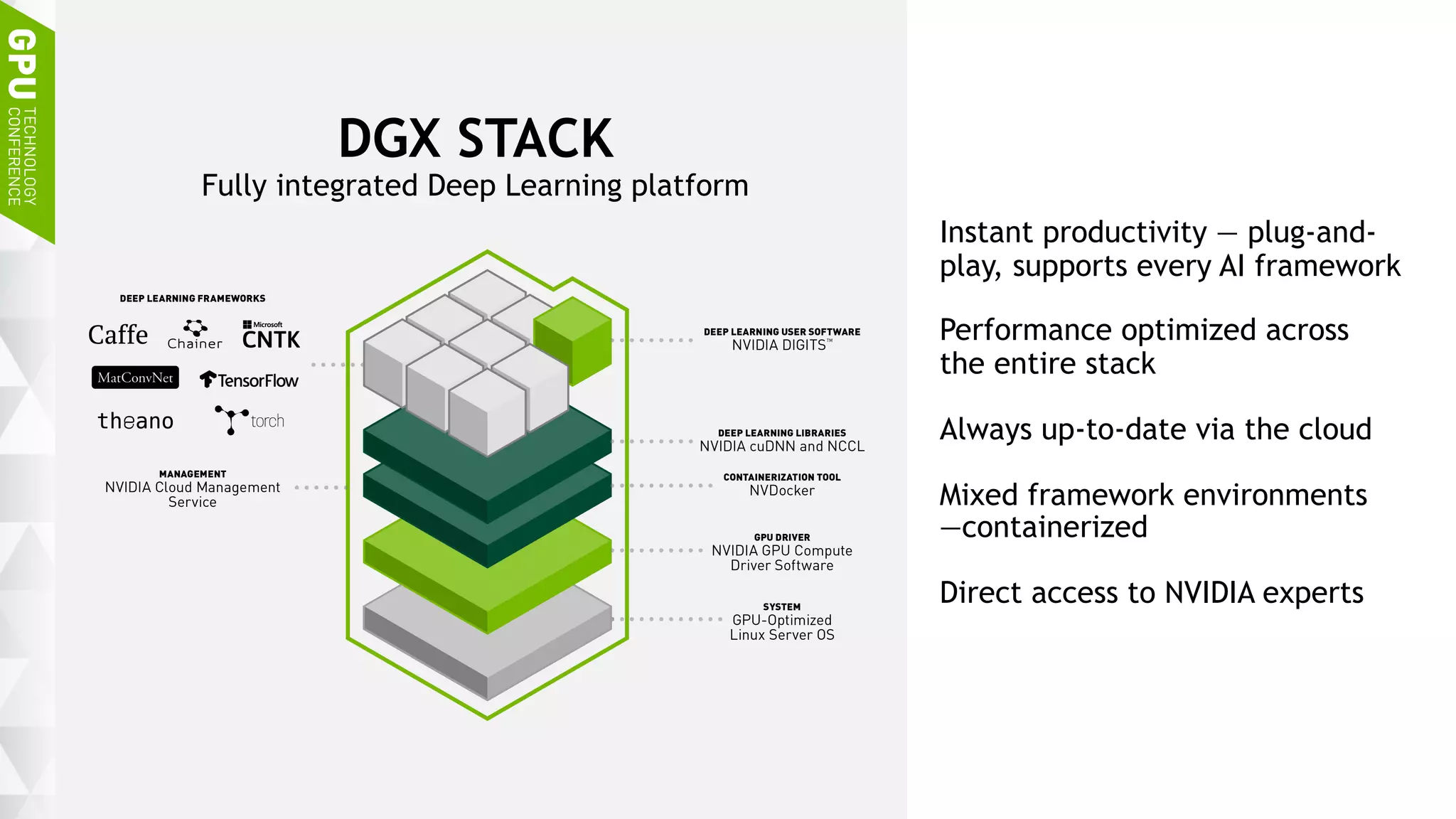

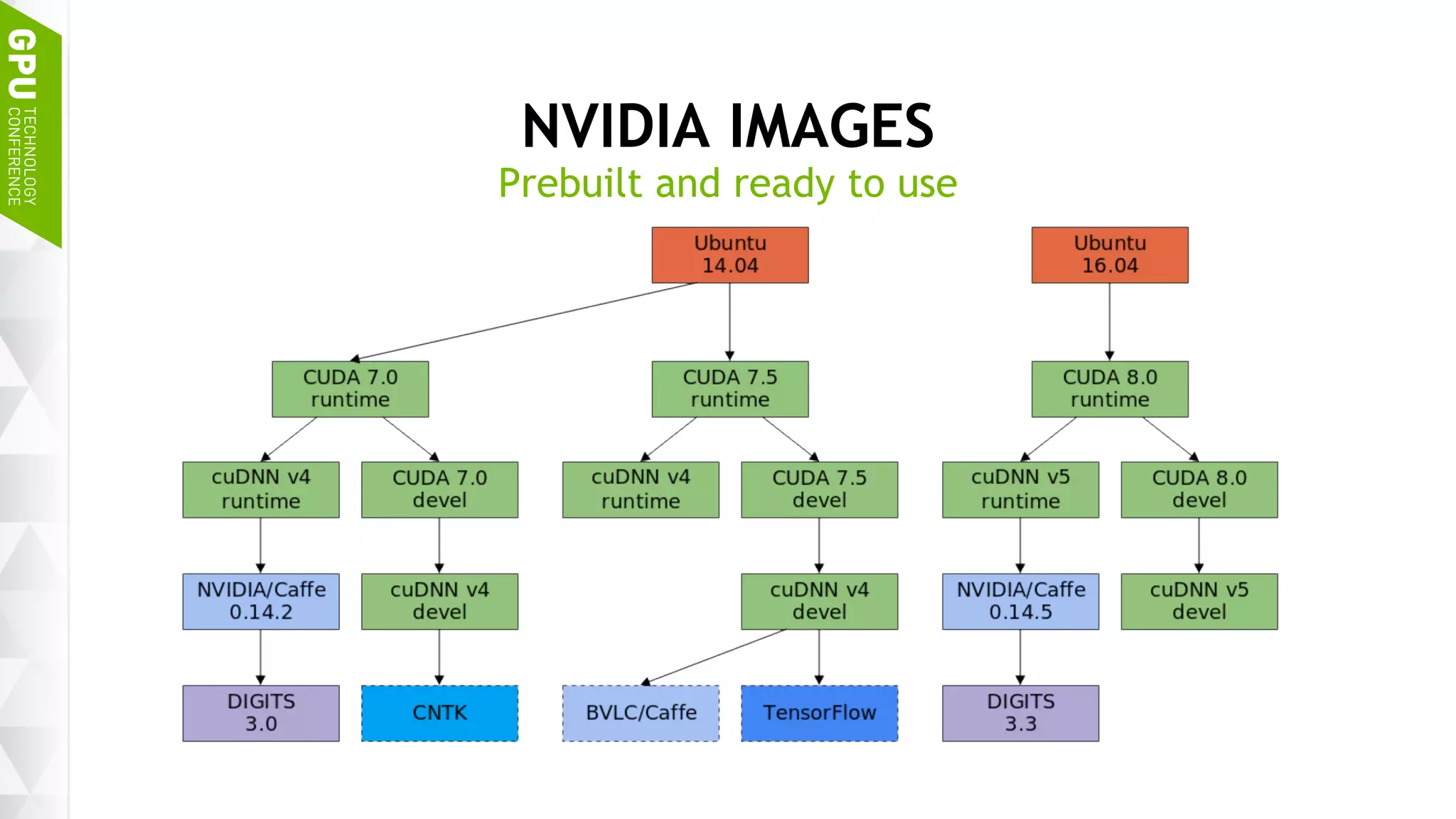



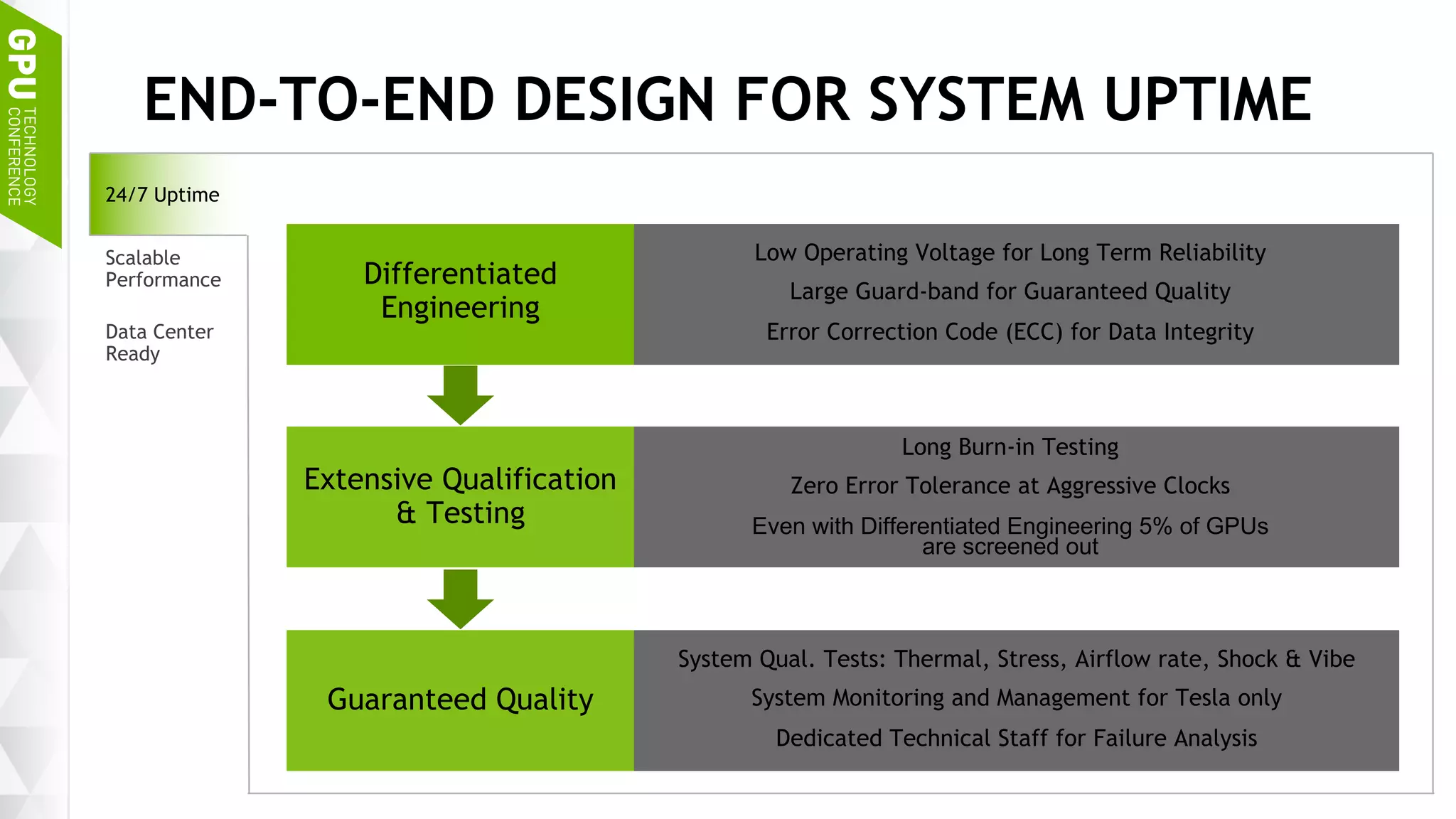
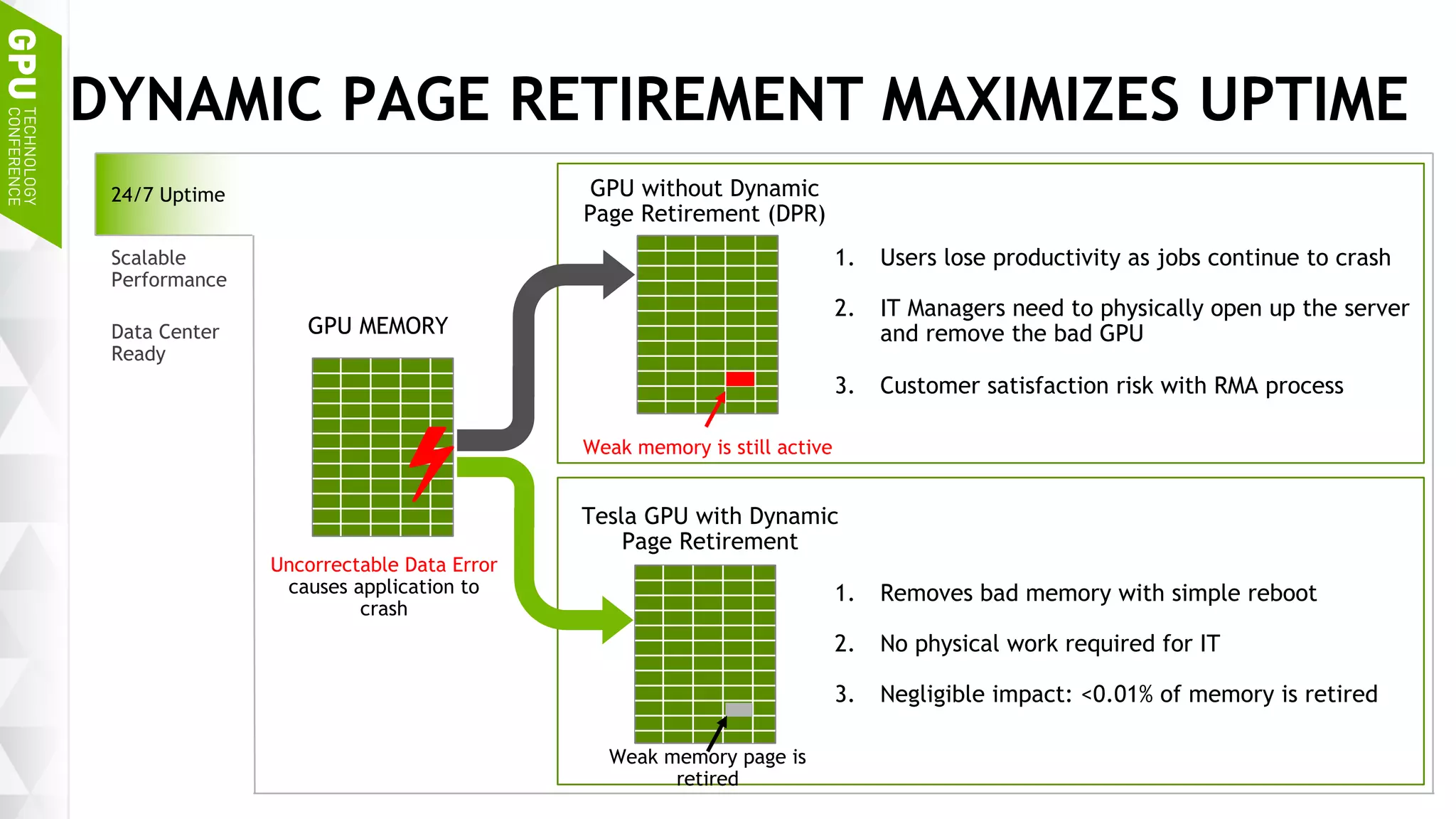


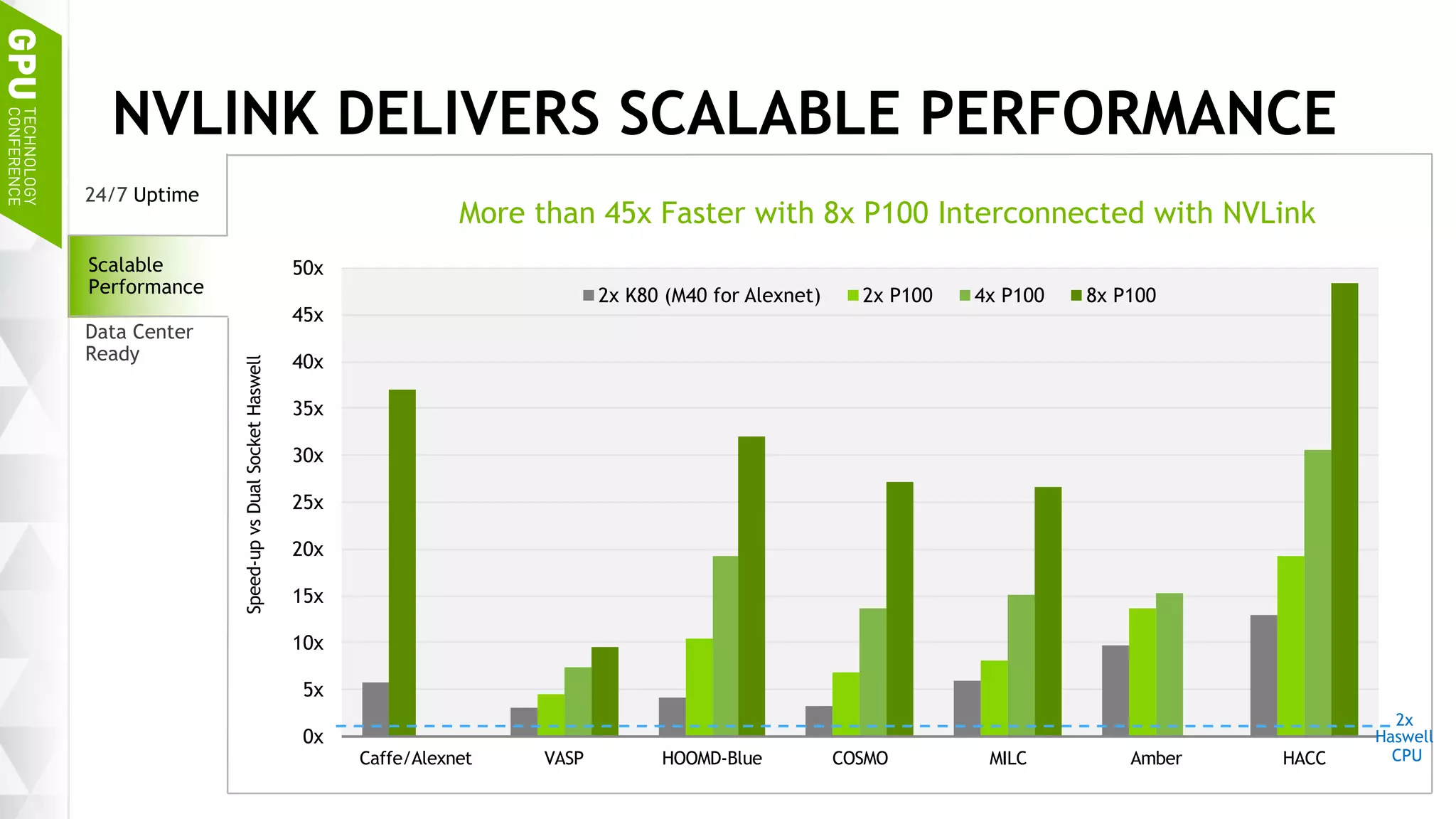
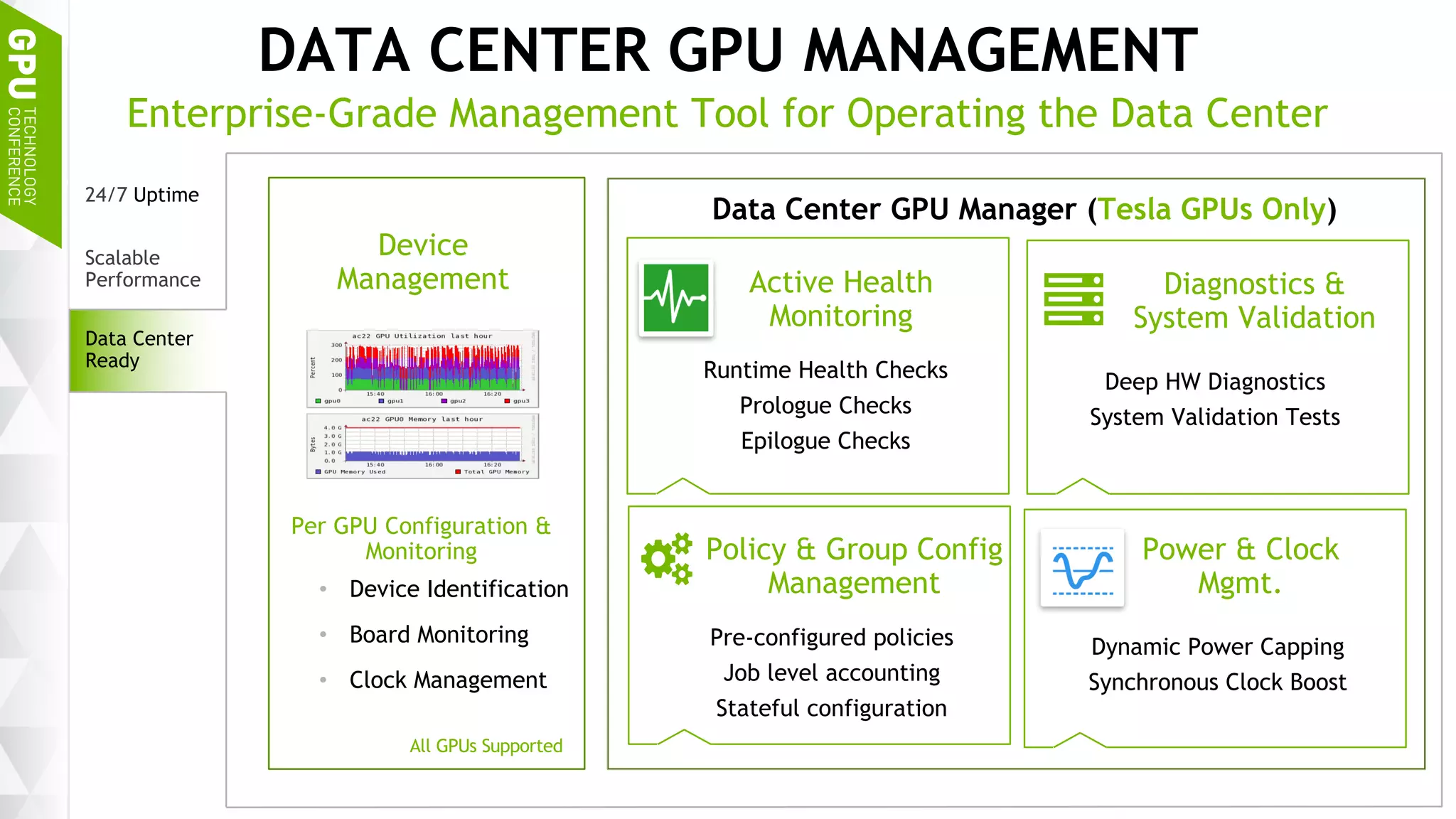



This document discusses NVIDIA's DGX-1 supercomputer and its applications for artificial intelligence and deep learning. It describes how the DGX-1 uses NVIDIA's Tesla P100 GPUs with NVLink connections to provide very high performance for deep learning workloads. It also discusses NVIDIA's software stack for deep learning including cuDNN, DIGITS, and Docker containers, which provide developers with tools for training and deploying neural networks. The document emphasizes how the DGX-1 and NVIDIA's GPUs are optimized for data center use through features like reliability, scalability, and management tools.





























![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)
























































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)

















