Downloaded 11 times



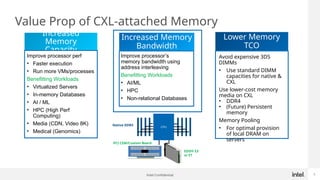

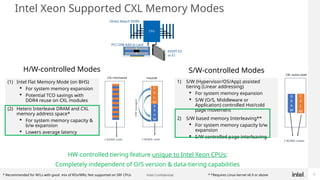
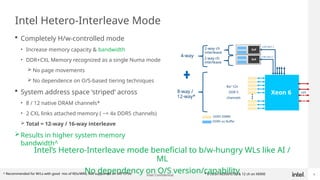
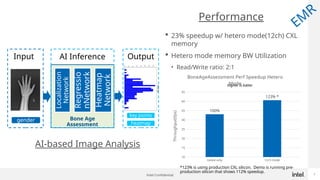
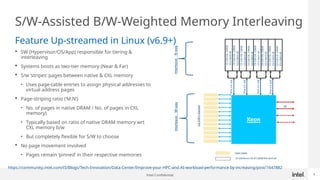
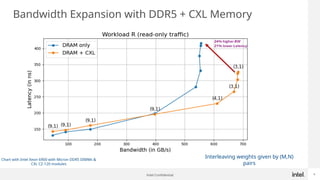
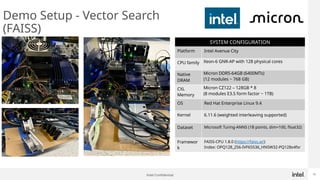

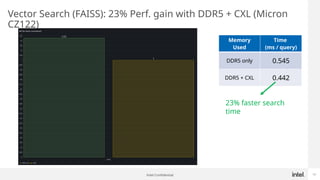

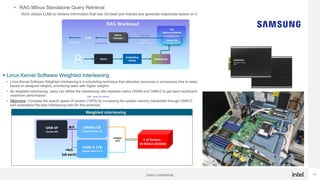
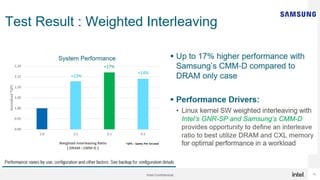

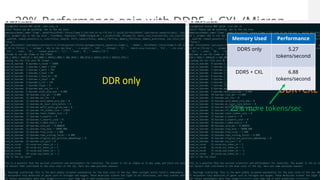




Generative AI use is one of the hottest application being run in Datacenters today. While GPUs are the dominant hardware choice for these, cost and availability may be of issue, especially for Enterprises. Also RAG (Retrieval Augmented Generation) is becoming more popular in Private clouds since Enterprises want to mine their own private data for Generative AI. This presentation will show how general purpose CPUs may be better suited to implement RAG-based AI using CXL memory.
















































































