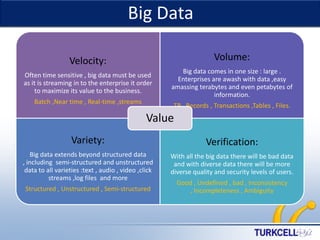
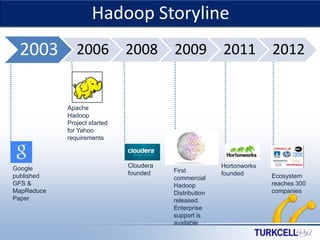
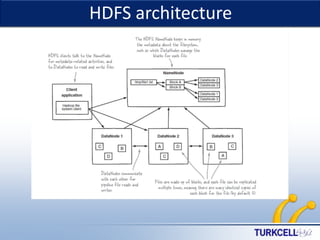
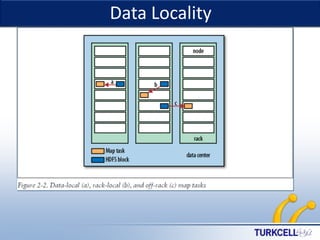
This document provides an overview of Hadoop and big data concepts. It discusses key characteristics of big data including volume, velocity, variety, and value. It then describes Hadoop distributed file system (HDFS) and MapReduce framework which are core components of Hadoop that allow distributed storage and processing of large datasets across clusters of commodity hardware. Finally, it outlines several common use cases where Hadoop can be applied such as customer churn analysis, recommendation engines, and network data analysis.